目标检测 —— Selective Search 算法
GitHub
简书
CSDN
论文题目: Selective Search for Object Recognition
1. 前言
由于目标检测和图像分类的不同,一张图可能存在多个目标,因此为了定位和识别出图片中的目标,一个简单的做法是通过 滑动窗口 的方法来将图像分割成许多的子区域,然后进行识别和坐标修正。但是这种方法有一个缺点就是: 他是在图像上通过穷举的方法找出所有的子区域,这样就会导致生成的小区域数量居多。而 Selective Search 是另一种基于区域的方法,该方法能大大减少子区域的数量。并且在 R-CNN 和 Fast R-CNN 中均利用该算法来生成 Region Proposals。
2. Selective Search
该算法有三个优势:
- 捕捉不同尺度(Capture All Scales)
- 多样化(Diversification)
- 计算速度快(Fast to Compute)
该方法主要包括两个内容:
- Hierarchical Grouping Algorithm
- Diversification Strategies
选择性算法使用的是按层次合并算法(Hierarchical Grouping),基本思路如下:首先使用论文“Efficient Graph-Based Image Segmentation”中的方法生成一些起始的小区域,之后使用贪心算法将区域归并到一起:先计算所有临近区域间的相似度(通过颜色,纹理,吻合度,大小等相似度),将最相似的两个区域归并,然后重新计算临近区域间的相似度,归并相似区域直至整幅图像成为一个区域
2.1 Hierarchical Grouping Algorithm(层次合并算法)

使用 Efficient Graph-Based Image Segmentation的方法获取原始分割区域R={r1,r2,…,rn};
初始化相似度集合S=∅;
计算两两相邻区域之间的相似度,将其添加到相似度集合S中;
从相似度集合S中找出相似度最大的两个区域 ri 和rj,
将其合并成为一个区域 rt,
从相似度集合S中除去原先与ri和rj相邻区域之间计算的相似度,
计算rt与其相邻区域(原先与ri或rj相邻的区域)的相似度,将其结果添加到相似度集合S中,
同时将新区域rt添加到区域集合R中;
在集合R中所有区域获取每个区域的Bounding Boxes,这个结果就是物体位置的可能结果L。
2.2 Diversification Strategies(多样性策略)
作者在这里主要考虑了三种不同的多样性策略:
- 颜色空间多样性
- 相似度多样性
- 初始化区域多样性
2.2.1 颜色空间多样性
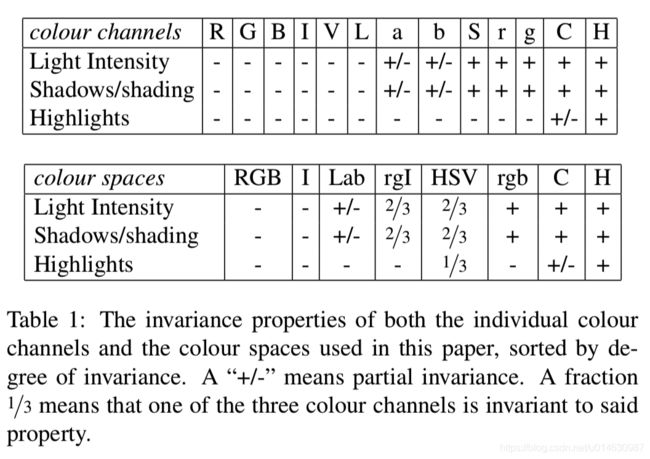
考虑场景以及光照条件等,作者采用了8种不同的颜色空间,这个策略主要应用于图像分割算法中原始区域的生成。主要使用的颜色空间有:(1)RGB,(2)灰度I,(3)Lab,(4)rgI(归一化的rg通道加上灰度),(5)HSV,(6)rgb(归一化的RGB),(7)C(8)H(HSV的H通道)。具体如下:
2.2.2 相似度多样性
1. 颜色度量
C i = { c i 1 , ⋯ c i n } C_i=\{c_i^1, \cdots c_i^n\} Ci={ci1,⋯cin} 表示第 i 个区域的在三个通道上的研制直方图,每个颜色通道有 25 个 bins 的直方图,这样三个通道共有 n=75 个 bins, 即 C i C_i Ci 为一个 75 维的向量,切该直方图使用 L1-norm标准化了,且用如下公式计算颜色相似度:
(1) s c o l o r ( r i , r j ) = ∑ k = 1 n min ( r i k , r j k ) s_{color}(r_i, r_j)=\sum_{k=1}^n \min(r_i^k, r_j^k) \tag{1} scolor(ri,rj)=k=1∑nmin(rik,rjk)(1)
合并后的颜色直方图计算如下:
(2) C t = s i z e ( r i ) ∗ C i + s i z e ( r j ) ∗ C j s i z e ( r i ) + s i z e ( r j ) C_t = \frac{size(r_i) * C_i + size(r_j) * C_j}{size(r_i)+size(r_j)} \tag{2} Ct=size(ri)+size(rj)size(ri)∗Ci+size(rj)∗Cj(2)
2. 纹理相似度
纹理采用SIFT-Like特征,具体做法是对每个颜色通道的8个不同方向计算方差σ=1的高斯微分(Gaussian Derivative),每个通道每个颜色获取10 bins的直方图(L1-norm归一化),这样就可以获取到一个240维的向量 T i = { t i 1 , t i 2 , ⋯ t i n } T_i=\{t_i^1, t_i^2, \cdots t_i^n\} Ti={ti1,ti2,⋯tin},区域之间纹理相似度计算方式和颜色相似度计算方式类似,合并之后新区域的纹理特征计算方式和颜色特征计算相同
(3) s t e x t u r e ( r i , r j ) = ∑ k = 1 n m i n ( t i k , t j k ) s_{texture}(r_i, r_j)=\sum_{k=1}^n min(t_i^k, t_j^k) \tag{3} stexture(ri,rj)=k=1∑nmin(tik,tjk)(3)
3. 大小相似度
大小是指区域中包含像素点的个数,使用如下公式计算ri和rj区域大小占的比例共同决定大小相似度,计算方式是总体减去两个像素和占全图像像素比例,这样可以让小区域优先级高,尽量让小的区域先合并,避免对大区域关注度过高,或者说是避免某个大区域对周围小区域进行吞并。
(4) s s i z e ( r i , r j ) = 1 − s i z e ( r i ) + s i z e ( r j ) s i z e ( i m ) s_{size}(r_i, r_j)=1-\frac{size(r_i) + size(r_j)}{size(im)} \tag{4} ssize(ri,rj)=1−size(im)size(ri)+size(rj)(4)
4. 形状相似度
形状相似度主要是为了衡量两个区域是否更加“吻合”,其指标是合并后的区域的Bounding Box(能够框住区域的最小矩形(没有旋转))和原始两图像大小和的差越小,其吻合度越高,计算公式如下
(5) f i l l ( r i , r j ) = 1 − s i z e ( B B i j − s i z e ( r i ) − s i z e ( r j ) ) s i z e ( i m ) fill(r_i, r_j)=1-\frac{size(BB_{ij}-size(r_i)-size(r_j))}{size(im)} \tag{5} fill(ri,rj)=1−size(im)size(BBij−size(ri)−size(rj))(5)
5. 总的相似度计算
(6) s ( r i , r j ) = a 1 s c o l o r ( r i , r j ) + a 2 s t e x t u r e ( r i , r j ) + a 3 s s i z e ( r i , r j ) + a 4 f i l l ( r i , r j ) s(r_i, r_j) = a_1s_{color}(r_i, r_j)+a_2s_{texture}(r_i, r_j)+a3s_{size}(r_i, r_j)+a_4fill(r_i, r_j) \tag{6} s(ri,rj)=a1scolor(ri,rj)+a2stexture(ri,rj)+a3ssize(ri,rj)+a4fill(ri,rj)(6)
2.2.3 初始化区域多样性
基于图的图像分割得到初始区域,而这个初始区域对于最终的影响是很大的,因此通过多种参数初始化图像分割,也算是扩充了多样性
2.3 区域打分
通过上述的步骤我们能够得到很多很多的区域,但是显然不是每个区域作为目标的可能性都是相同的,因此我们需要衡量这个可能性,这样就可以根据我们的需要筛选区域建议个数啦。
这篇文章做法是,给予最先合并的图片块较大的权重,比如最后一块完整图像权重为1,倒数第二次合并的区域权重为2以此类推。但是当我们策略很多,多样性很多的时候呢,这个权重就会有太多的重合了,排序不好搞啊。文章做法是给每个权重乘以一个 [ 0 , 1 ] [0, 1] [0,1] 的随机数,然后对于相同的区域多次出现的也叠加下权重,毕竟多个方法都说你是目标,也是有理由的嘛。这样我就得到了所有区域的目标分数,也就可以根据自己的需要选择需要多少个区域了。