监控架构概述
kubernetes监控指标大体可以分为两类:核心监控指标和自定义指标,核心监控指标是kubernetes内置稳定可靠监控指标,早期由heapster完成,现由metric-server实现;自定义指标用于实现核心指标的扩展,能够提供更丰富的指标支持,如应用状态指标,自定义指标需要通过Aggregator和k8s api集成,当前主流通过promethues实现。
监控指标用途:
- kubectl top 查看node和pod的cpu+内存使用情况
- kubernetes-dashbaord 控制台查看节点和pod资源监控
- Horizontal Pod Autoscaler 水平横向动态扩展
- Scheduler 调度器调度选择条件
metric-server架构和安装
metric-server简介
Metrics Server is a cluster-wide aggregator of resource usage data. Resource metrics are used by components like kubectl top and the Horizontal Pod Autoscaler to scale workloads. To autoscale based upon a custom metric, you need to use the Prometheus Adapter Metric-server是一个集群级别的资源指标收集器,用于收集资源指标数据
- 提供基础资源如CPU、内存监控接口查询;
- 接口通过 Kubernetes aggregator注册到kube-apiserver中;
- 对外通过Metric API暴露给外部访问;
- 自定义指标使用需要借助Prometheus实现。
The Metrics API
- /node 获取所有节点的指标,指标名称为NodeMetrics
- /node/
特定节点指标 - /namespaces/{namespace}/pods 获取命名空间下的所有pod指标
- /namespaces/{namespace}/pods/{pod} 特定pod的指标,指标名称为PodMetrics
未来将能够支持指标聚合,如max最大值,min最小值,95th峰值,以及自定义时间窗口,如1h,1d,1w等。
metric-server架构
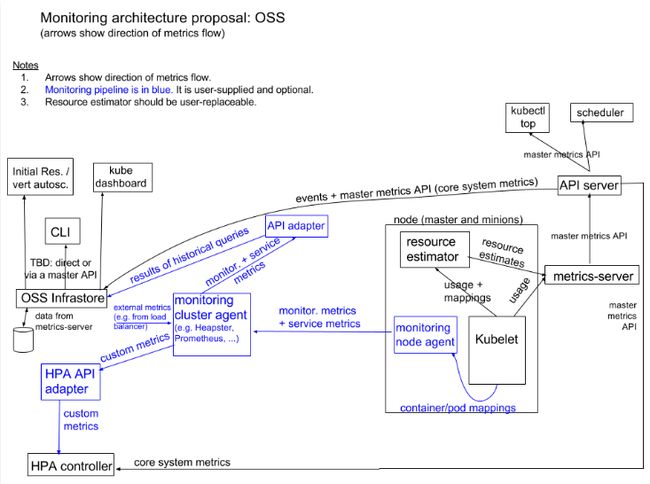
监控架构分两部分内容:核心监控(图白色部分)和自定义监控(图蓝色部分)
1、 核心监控实现
- 通过kubelet收集资源估算+使用估算
- metric-server负责数据收集,不负责数据存储
- metric-server对外暴露Metric API接口
- 核心监控指标客用户HPA,kubectl top,scheduler和dashboard
2、 自定义监控实现
- 自定义监控指标包括监控指标和服务指标
- 需要在每个node上部署一个agent上报至集群监控agent,如prometheus
- 集群监控agent收集数据后需要将监控指标+服务指标通过API adaptor转换为apiserver能够处理的接口
- HPA通过自定义指标实现更丰富的弹性扩展能力,需要通过HPA adaptor API做次转换。
metric-server部署
1、获取metric-server安装文件,当前具有两个版本:1.7和1.8+,kubernetes1.7版本安装1.7的metric-server版本,kubernetes 1.8后版本安装metric server 1.8+版本,现在最新的版本推荐使用0.3.7 版本
https://github.com/kubernetes-sigs/metrics-server/
2、部署metric-server,部署0.3.7版本
wget https://github.com/kubernetes-sigs/metrics-server/releases/download/v0.3.7/components.yaml
核心的配置文件是metrics-server-deployment.yaml,metric-server以Deployment的方式部署在集群中,镜像k8s.gcr.io/metrics-server-amd64:v0.3.7需要提前下载好,其对应的安装文件内容如下:
# 修改后的metrics-server文件
cat metrics-server-0.3.7.yaml
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: system:aggregated-metrics-reader
labels:
rbac.authorization.k8s.io/aggregate-to-view: "true"
rbac.authorization.k8s.io/aggregate-to-edit: "true"
rbac.authorization.k8s.io/aggregate-to-admin: "true"
rules:
- apiGroups: ["metrics.k8s.io"]
resources: ["pods", "nodes"]
verbs: ["get", "list", "watch"]
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: metrics-server:system:auth-delegator
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: system:auth-delegator
subjects:
- kind: ServiceAccount
name: metrics-server
namespace: kube-system
---
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:
name: metrics-server-auth-reader
namespace: kube-system
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: Role
name: extension-apiserver-authentication-reader
subjects:
- kind: ServiceAccount
name: metrics-server
namespace: kube-system
---
apiVersion: apiregistration.k8s.io/v1beta1
kind: APIService
metadata:
name: v1beta1.metrics.k8s.io
spec:
service:
name: metrics-server
namespace: kube-system
group: metrics.k8s.io
version: v1beta1
insecureSkipTLSVerify: true
groupPriorityMinimum: 100
versionPriority: 100
---
apiVersion: v1
kind: ServiceAccount
metadata:
name: metrics-server
namespace: kube-system
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: metrics-server
namespace: kube-system
labels:
k8s-app: metrics-server
spec:
selector:
matchLabels:
k8s-app: metrics-server
replicas: 1
strategy:
rollingUpdate:
maxSurge: 25%
maxUnavailable: 25%
template:
metadata:
name: metrics-server
labels:
k8s-app: metrics-server
spec:
serviceAccountName: metrics-server
volumes:
# mount in tmp so we can safely use from-scratch images and/or read-only containers
- name: tmp-dir
emptyDir: {}
containers:
- name: metrics-server
image: k8s.gcr.io/metrics-server/metrics-server:v0.3.7
imagePullPolicy: IfNotPresent
args:
- --cert-dir=/tmp
# - --v=6
- --metric-resolution=30s
- --secure-port=4443
- --kubelet-insecure-tls
- --kubelet-preferred-address-types=InternalIP,Hostname,InternalDNS,ExternalDNS,ExternalIP
ports:
- name: main-port
containerPort: 4443
protocol: TCP
# add livenessProbe
livenessProbe:
httpGet:
path: /healthz
port: 4443
scheme: HTTPS
initialDelaySeconds: 30
periodSeconds: 30
successThreshold: 1
failureThreshold: 3
readinessProbe:
httpGet:
path: /healthz
port: 4443
scheme: HTTPS
initialDelaySeconds: 30
periodSeconds: 30
successThreshold: 1
failureThreshold: 3
securityContext:
readOnlyRootFilesystem: true
runAsNonRoot: true
runAsUser: 1000
volumeMounts:
- name: tmp-dir
mountPath: /tmp
nodeSelector:
kubernetes.io/os: linux
kubernetes.io/arch: "amd64"
---
apiVersion: v1
kind: Service
metadata:
name: metrics-server
namespace: kube-system
labels:
kubernetes.io/name: "Metrics-server"
kubernetes.io/cluster-service: "true"
spec:
selector:
k8s-app: metrics-server
ports:
- port: 443
protocol: TCP
targetPort: main-port
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: system:metrics-server
rules:
- apiGroups:
- ""
resources:
- pods
- nodes
- nodes/stats
- namespaces
- configmaps
verbs:
- get
- list
- watch
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: system:metrics-server
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: system:metrics-server
subjects:
- kind: ServiceAccount
name: metrics-server
namespace: kube-system
3、检查metric-server部署的情况,查看metric-server的Pod已部署成功
[root@localhost metrisc-server]# kubectl get deployments metrics-server -n kube-system
NAME READY UP-TO-DATE AVAILABLE AGE
metrics-server 0/1 1 0 10s
[root@localhost metrisc-server]# kubectl get pods -n kube-system -l k8s-app=metrics-server
NAME READY STATUS RESTARTS AGE
metrics-server-74c4d67d6f-g6rgq 1/1 Running 0 12m
metric-server api测试
1、安装完metric-server后会增加一个metrics.k8s.io/v1beta1的API组,该API组通过Aggregator接入apiserver中
[root@localhost metrisc-server]# kubectl get apiservices.apiregistration.k8s.io |grep metrics-server
v1beta1.metrics.k8s.io kube-system/metrics-server True 13m
2、使用命令行查看kubectl top node的监控信息,可以看到CPU和内存的利用率
[root@localhost metrisc-server]# kubectl top nodes
NAME CPU(cores) CPU% MEMORY(bytes) MEMORY%
test-control-plane 48m 4% 1152Mi 38%
3、查看pod监控信息,可以看到pod中CPU和内存的使用情况
kubectl top po
NAME CPU(cores) MEMORY(bytes)
haproxy-ingress-demo-855c859585-4fj7k 0m 2Mi
haproxy-ingress-demo-855c859585-nf8gl 0m 2Mi
haproxy-ingress-demo-855c859585-nkkv7 0m 2Mi
haproxy-ingress-demo2-744696b97-6hrx5 0m 2Mi
haproxy-ingress-demo2-744696b97-g9n5k 0m 2Mi
haproxy-ingress-demo2-744696b97-r8czj 0m 2Mi
hit-counter-app-77c47576d4-2xhwn 3m 45Mi
4、除了用命令行连接metricc-server获取监控资源,还可以通过API方式链接方式获取,可用API有
- http://127.0.0.1:8001/apis/metrics.k8s.io/v1beta1/nodes
- http://127.0.0.1:8001/apis/metrics.k8s.io/v1beta1/nodes/
- http://127.0.0.1:8001/apis/metrics.k8s.io/v1beta1/pods
- http://127.0.0.1:8001/apis/metrics.k8s.io/v1beta1/namespace/ /pods/
如下测试API接口的使用:
a、创建一个kube proxy代理,用于链接apiserver,默认将监听在127的8001端口
[root@node-1 ~]# kubectl proxy
Starting to serve on 127.0.0.1:8001
b、查看node列表的监控数据,可以获取到所有node的资源监控数据,usage中包含cpu和memory
[root@node-1 ~]# curl http://127.0.0.1:8001/apis/metrics.k8s.io/v1beta1/nodes
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 1167 100 1167 0 0 393k 0 --:--:-- --:--:-- --:--:-- 569k
{
"kind": "NodeMetricsList",
"apiVersion": "metrics.k8s.io/v1beta1",
"metadata": {
"selfLink": "/apis/metrics.k8s.io/v1beta1/nodes"
},
"items": [
{
"metadata": {
"name": "node-3",
"selfLink": "/apis/metrics.k8s.io/v1beta1/nodes/node-3",
"creationTimestamp": "2019-12-30T14:23:00Z"
},
"timestamp": "2019-12-30T14:22:07Z",
"window": "30s",
"usage": {
"cpu": "32868032n",
"memory": "1027108Ki"
}
},
{
"metadata": {
"name": "node-1",
"selfLink": "/apis/metrics.k8s.io/v1beta1/nodes/node-1",
"creationTimestamp": "2019-12-30T14:23:00Z"
},
"timestamp": "2019-12-30T14:22:07Z",
"window": "30s",
"usage": {
"cpu": "108639556n",
"memory": "4305356Ki"
}
},
{
"metadata": {
"name": "node-2",
"selfLink": "/apis/metrics.k8s.io/v1beta1/nodes/node-2",
"creationTimestamp": "2019-12-30T14:23:00Z"
},
"timestamp": "2019-12-30T14:22:12Z",
"window": "30s",
"usage": {
"cpu": "47607386n",
"memory": "1119960Ki"
}
}
]
}
c、指定某个具体的node访问到具体node的资源监控数据
[root@node-1 ~]# curl http://127.0.0.1:8001/apis/metrics.k8s.io/v1beta1/nodes/node-2
{
"kind": "NodeMetrics",
"apiVersion": "metrics.k8s.io/v1beta1",
"metadata": {
"name": "node-2",
"selfLink": "/apis/metrics.k8s.io/v1beta1/nodes/node-2",
"creationTimestamp": "2019-12-30T14:24:39Z"
},
"timestamp": "2019-12-30T14:24:12Z",
"window": "30s",
"usage": {
"cpu": "43027609n",
"memory": "1120168Ki"
}
}
d、查看所有pod的列表信息
curl http://127.0.0.1:8001/apis/metrics.k8s.io/v1beta1/pods
e、查看某个具体pod的监控数据
[root@node-1 ~]# curl http://127.0.0.1:8001/apis/metrics.k8s.io/v1beta1/namespaces/default/pods/haproxy-ingress-demo-5d487d4fc-sr8tm
{
"kind": "PodMetrics",
"apiVersion": "metrics.k8s.io/v1beta1",
"metadata": {
"name": "haproxy-ingress-demo-5d487d4fc-sr8tm",
"namespace": "default",
"selfLink": "/apis/metrics.k8s.io/v1beta1/namespaces/default/pods/haproxy-ingress-demo-5d487d4fc-sr8tm",
"creationTimestamp": "2019-12-30T14:36:30Z"
},
"timestamp": "2019-12-30T14:36:13Z",
"window": "30s",
"containers": [
{
"name": "haproxy-ingress-demo",
"usage": {
"cpu": "0",
"memory": "1428Ki"
}
}
]
}
5、当然也可以通过kubectl -raw的方式访问接口,如调用node-3的数据
[root@node-1 ~]# kubectl get --raw /apis/metrics.k8s.io/v1beta1/nodes/node-3 | jq .
{
"kind": "NodeMetrics",
"apiVersion": "metrics.k8s.io/v1beta1",
"metadata": {
"name": "node-3",
"selfLink": "/apis/metrics.k8s.io/v1beta1/nodes/node-3",
"creationTimestamp": "2019-12-30T14:44:46Z"
},
"timestamp": "2019-12-30T14:44:09Z",
"window": "30s",
"usage": {
"cpu": "35650151n",
"memory": "1026820Ki"
}
}
其他近似的接口有:
kubectl get --raw /apis/metrics.k8s.io/v1beta1/nodes 获取所有node的数据
kubectl get --raw /apis/metrics.k8s.io/v1beta1/nodes/
kubectl get --raw /apis/metrics.k8s.io/v1beta1/pods 获取所有pod的数据
kubectl get --raw /apis/metrics.k8s.io/v1beta1/namespaces/default/pods/haproxy-ingress-demo-5d487d4fc-sr8tm 获取某个特定pod的数据
HPA水平横向动态扩展
HPA概述
The Horizontal Pod Autoscaler automatically scales the number of pods in a replication controller, deployment, replica set or stateful set based on observed CPU utilization (or, with custom metrics support, on some other application-provided metrics). Note that Horizontal Pod Autoscaling does not apply to objects that can’t be scaled, for example, DaemonSets.
HPA即Horizontal Pod Autoscaler,Pod水平横向动态扩展,即根据应用分配资源使用情况,动态增加或者减少Pod副本数量,以实现集群资源的扩容,其实现机制为:
- HPA需要依赖于监控组件,调用监控数据实现动态伸缩,如调用Metrics API接口
- HPA是二级的副本控制器,建立在Deployments,ReplicaSet,StatefulSets等副本控制器基础之上
- HPA根据获取资源指标不同支持两个版本:v1和v2alpha1
- HPA V1获取核心资源指标,如CPU和内存利用率,通过调用Metric-server API接口实现
- HPA V2获取自定义监控指标,通过Prometheus获取监控数据实现
- HPA根据资源API周期性调整副本数,检测周期horizontal-pod-autoscaler-sync-period定义的值,默认15s
HPA实现
如下开始延时HPA功能的实现,先创建一个Deployment副本控制器,然后再通过HPA定义资源度量策略,当CPU利用率超过requests分配的80%时即扩容。
1、创建Deployment副本控制器
[root@node-1 ~]# cat nginx-test.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: hpa-demo
name: hpa-demo
spec:
replicas: 3
selector:
matchLabels:
app: hpa-demo
template:
metadata:
labels:
app: hpa-demo
spec:
containers:
- image: nginx:1.7.9
name: nginx
resources:
requests:
cpu: 10m
memory: 80Mi
---
apiVersion: v1
kind: Service
metadata:
name: hpa-demo
namespace: default
spec:
clusterIP: 10.109.197.67
ports:
- port: 80
protocol: TCP
targetPort: 80
selector:
app: hpa-demo
type: ClusterIP
[root@node-1 ~]# kubectl get deployments hpa-demo -o yaml
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
annotations:
deployment.kubernetes.io/revision: "1"
creationTimestamp: "2019-12-31T01:43:24Z"
generation: 1
labels:
run: hpa-demo
name: hpa-demo
namespace: default
resourceVersion: "14451208"
selfLink: /apis/extensions/v1beta1/namespaces/default/deployments/hpa-demo
uid: 3b0f29e8-8606-4e52-8f5b-6c960d396136
spec:
progressDeadlineSeconds: 600
replicas: 1
revisionHistoryLimit: 10
selector:
matchLabels:
run: hpa-demo
strategy:
rollingUpdate:
maxSurge: 25%
maxUnavailable: 25%
type: RollingUpdate
template:
metadata:
creationTimestamp: null
labels:
run: hpa-demo
spec:
containers:
- image: nginx:1.7.9
imagePullPolicy: IfNotPresent
name: hpa-demo
ports:
- containerPort: 80
protocol: TCP
resources:
requests:
cpu: 200m
memory: 64Mi
terminationMessagePath: /dev/termination-log
terminationMessagePolicy: File
dnsPolicy: ClusterFirst
restartPolicy: Always
schedulerName: default-scheduler
securityContext: {}
terminationGracePeriodSeconds: 30
status:
availableReplicas: 1
conditions:
- lastTransitionTime: "2019-12-31T01:43:25Z"
lastUpdateTime: "2019-12-31T01:43:25Z"
message: Deployment has minimum availability.
reason: MinimumReplicasAvailable
status: "True"
type: Available
- lastTransitionTime: "2019-12-31T01:43:24Z"
lastUpdateTime: "2019-12-31T01:43:25Z"
message: ReplicaSet "hpa-demo-755bdd875c" has successfully progressed.
reason: NewReplicaSetAvailable
status: "True"
type: Progressing
observedGeneration: 1
readyReplicas: 1
replicas: 1
updatedReplicas: 1
2、创建HPA控制器,基于CPU实现横向扩展,策略为至少2个Pod,最大5个,targetCPUUtilizationPercentage表示CPU实际使用率占requests百分比
vim hpa-demo.yaml
apiVersion: autoscaling/v1
kind: HorizontalPodAutoscaler
metadata:
name: hpa-demo
spec:
maxReplicas: 5
minReplicas: 2
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: hpa-demo
targetCPUUtilizationPercentage: 80
3、应用HPA规则并查看详情,由于策略需确保最小2个副本,Deployment默认不是2个副本,因此需要扩容,在详情日志中看到副本扩展至2个
[root@node-1 ~]# kubectl apply -f hpa-demo.yaml
horizontalpodautoscaler.autoscaling/hpa-demo created
#查看HPA列表
[root@node-1 ~]# kubectl get horizontalpodautoscalers.autoscaling
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
hpa-demo Deployment/hpa-demo /80% 2 5 0 7s
#查看HPA详情
[root@node-1 ~]# kubectl describe horizontalpodautoscalers.autoscaling hpa-demo
Name: hpa-demo
Namespace: default
Labels:
Annotations: kubectl.kubernetes.io/last-applied-configuration:
{"apiVersion":"autoscaling/v1","kind":"HorizontalPodAutoscaler","metadata":{"annotations":{},"name":"hpa-demo","namespace":"default"},"spe...
CreationTimestamp: Tue, 31 Dec 2019 09:52:51 +0800
Reference: Deployment/hpa-demo
Metrics: ( current / target )
resource cpu on pods (as a percentage of request): / 80%
Min replicas: 2
Max replicas: 5
Deployment pods: 1 current / 2 desired
Conditions:
Type Status Reason Message
---- ------ ------ -------
AbleToScale True SucceededRescale the HPA controller was able to update the target scale to 2
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal SuccessfulRescale 1s horizontal-pod-autoscaler New size: 2; reason: Current number of replicas below Spec.MinReplicas #副本扩容至2个,根据MinReplica的策略
4、查看Deployment列表校验确认扩容情况,已达到HPA基础最小化策略
[root@node-1 ~]# kubectl get deployments hpa-demo --show-labels
NAME READY UP-TO-DATE AVAILABLE AGE LABELS
hpa-demo 2/2 2 2 94m run=hpa-demo
[root@node-1 ~]# kubectl get pods -l run=hpa-demo
NAME READY STATUS RESTARTS AGE
hpa-demo-5fcd9c757d-7q4td 1/1 Running 0 5m10s
hpa-demo-5fcd9c757d-cq6k6 1/1 Running 0 10m
5、假如业务增长期间,CPU利用率增高,会自动横向增加Pod来实现,下面开始通过CPU压测来演示Deployment的扩展
[root@node-1 ~]# kubectl exec -it hpa-demo-5fcd9c757d-cq6k6 /bin/bash
root@hpa-demo-5fcd9c757d-cq6k6:/# dd if=/dev/zero of=/dev/null
再次查看HPA的日志,提示已扩容,原因是cpu resource utilization (percentage of request) above target,即CPU资源利用率超过requests设置的百分比
[root@node-1 ~]# kubectl describe horizontalpodautoscalers.autoscaling hpa-demo
Name: hpa-demo
Namespace: default
Labels:
Annotations: kubectl.kubernetes.io/last-applied-configuration:
{"apiVersion":"autoscaling/v1","kind":"HorizontalPodAutoscaler","metadata":{"annotations":{},"name":"hpa-demo","namespace":"default"},"spe...
CreationTimestamp: Tue, 31 Dec 2019 09:52:51 +0800
Reference: Deployment/hpa-demo
Metrics: ( current / target )
resource cpu on pods (as a percentage of request): 99% (199m) / 80%
Min replicas: 2
Max replicas: 5
Deployment pods: 5 current / 5 desired
Conditions:
Type Status Reason Message
---- ------ ------ -------
AbleToScale True ReadyForNewScale recommended size matches current size
ScalingActive True ValidMetricFound the HPA was able to successfully calculate a replica count from cpu resource utilization (percentage of request)
ScalingLimited True TooManyReplicas the desired replica count is more than the maximum replica count
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal SuccessfulRescale 8m2s horizontal-pod-autoscaler New size: 4; reason: cpu resource utilization (percentage of request) above target
查看副本的个数,确认扩容情况,已成功扩容至5个
[root@node-1 ~]# kubectl get pods
NAME READY STATUS RESTARTS AGE
hpa-demo-5fcd9c757d-7q4td 1/1 Running 0 16m
hpa-demo-5fcd9c757d-cq6k6 1/1 Running 0 21m
hpa-demo-5fcd9c757d-jmb6w 1/1 Running 0 16m
hpa-demo-5fcd9c757d-lpxk8 1/1 Running 0 16m
hpa-demo-5fcd9c757d-zs6cg 1/1 Running 0 21m
6、停止CPU压测业务,HPA会自定缩减Pod的副本个数,直至满足条件
[root@node-1 ~]# kubectl describe horizontalpodautoscalers.autoscaling hpa-demo
Name: hpa-demo
Namespace: default
Labels:
Annotations: kubectl.kubernetes.io/last-applied-configuration:
{"apiVersion":"autoscaling/v1","kind":"HorizontalPodAutoscaler","metadata":{"annotations":{},"name":"hpa-demo","namespace":"default"},"spe...
CreationTimestamp: Tue, 31 Dec 2019 09:52:51 +0800
Reference: Deployment/hpa-demo
Metrics: ( current / target )
resource cpu on pods (as a percentage of request): 0% (0) / 80%
Min replicas: 2
Max replicas: 5
Deployment pods: 2 current / 2 desired
Conditions:
Type Status Reason Message
---- ------ ------ -------
AbleToScale True ReadyForNewScale recommended size matches current size
ScalingActive True ValidMetricFound the HPA was able to successfully calculate a replica count from cpu resource utilization (percentage of request)
ScalingLimited True TooFewReplicas the desired replica count is increasing faster than the maximum scale rate
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal SuccessfulRescale 18m horizontal-pod-autoscaler New size: 4; reason: cpu resource utilization (percentage of request) above target
Normal SuccessfulRescale 113s horizontal-pod-autoscaler New size: 2; reason: All metrics below target #缩减至2个pod副本
确认副本的个数,已缩减至最小数量2个
[root@node-1 ~]# kubectl get pods -l run=hpa-demo
NAME READY STATUS RESTARTS AGE
hpa-demo-5fcd9c757d-cq6k6 1/1 Running 0 24m
hpa-demo-5fcd9c757d-zs6cg 1/1 Running 0 24m
通过上面的例子可以知道,HPA可以基于metric-server提供的API监控数据实现水平动态弹性扩展的需求,从而可以根据业务CPU使用情况,动态水平横向扩展,保障业务的可用性。当前HPA V1扩展使用指标只能基于CPU分配使用率进行扩展,功能相对有限,更丰富的功能需要由HPA V2版来实现,其由不同的API来实现:
- metrics.k8s.io 资源指标API,通过metric-server提供,提供node和pod的cpu,内存资源查询;
- custom.metrics.k8s.io 自定义指标,通过adapter和kube-apiserver集成,如promethues;
- external.metrics.k8s.io 外部指标,和自定义指标类似,需要通过adapter和k8s集成。
参考文献
资源指标说明:https://kubernetes.io/docs/tasks/debug-application-cluster/resource-metrics-pipeline/
部署官方说明:(https://github.com/kubernetes-sigs/metrics-server)
参考文档:https://cloud.tencent.com/developer/article/1579216