SpringCloud 应用在 Kubernetes 上的最佳实践 — 线上发布(优雅上下线)
前言
上篇我们讲的是发布回滚过程,尤其是在 Kubernetes 的回滚过程中,原生有提供 Rollout 到上一个版本的能力,能保证我们在发布过程中遇到问题时快速回退的能力。然而在每一次上线的过程中,我们最难处理的就是正在运行中的流量,如何做到流量的无损上/下线,是一个系统能保证 SLA 的关键。
介绍
什么是优雅上线?就如下面这个房子一样,未建好的房子,人住进去会有危险,房子应该建好,装修好,人才能住进去。

那么如何做到优雅上线,我们先来看一个WEB应用的加载过程,就像上面造房子一样,是个漫长的过程:
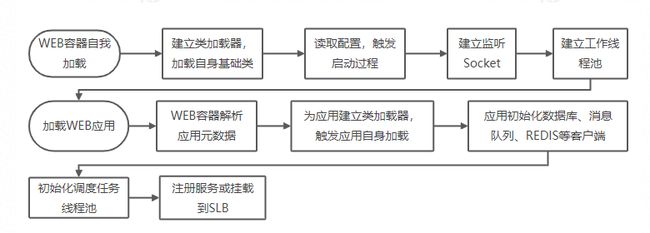
应用的加载是漫长的,在加载过程,服务是不可预期的;如过早的打开Socket监听,则客户端可能感受到漫长的等待;如果数据库、消息队列、REDIS客户端未完成初始化,则服务可能因缺少关键的底层服务而异常。
所以在应用准备完成后,才接入服务,即做到优雅上线。当然应用上线后,也可能因如数据库断连等情况引起服务不可用;或是准备完成了,但在上线前又如发生数据库断连,导致服务异常。为了简化问题,后面两种情况作为一个应用自愈的问题来看待。
什么是优雅下线?与建房子相反就像下面的危房一样,人住在里面很危险,人应该先从房子出来,然后推掉房子。
那么如何做到优雅下线,我们先来看一个WEB应用的停止过程: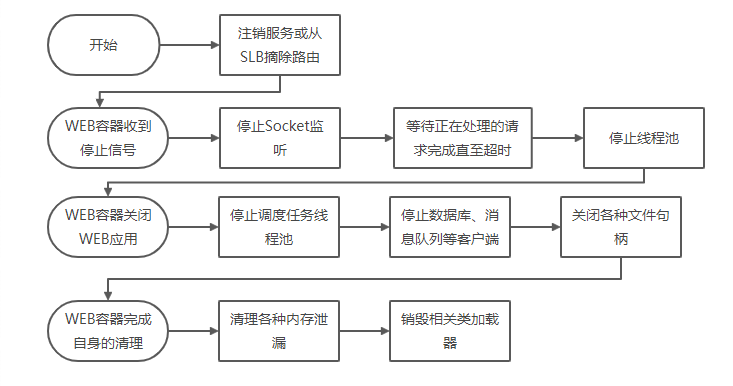
所以关闭服务接入(转移服务接入),完成正在处理的服务,清理自身占用的资源后退出即做到优雅下线。
如何实现优雅下线
从上面介绍看,似乎不难,但事实上,很少系统真正实现了优雅上下线。因为软件本身由无数各种各样相互依赖的结构组成,每个结构都使用一些资源,污染一些资源;通常在设计之初优雅上下线也不被作为优先考虑的需求,所以对于下线的过程,通常都没被充分考虑,在设计上通常要求:
- 结构(组件)应形成层次关系。
- 用户线程需能收到停止信号并响应退出;否则使用daemon线程。
- 结构应按依赖关系自下向上构建:就像建房子一样,自内向外构建而成。
- 结构应按依赖关系自上向下销毁:就像拆房子一样,自外向内拆解。
优雅下线实现路径
大致分为一个完整的过程,需要经历一下四个关键的节点,如下图;
- 接收信号:停止信号可能从进程内部触发(比如 Crash 场景),如果自退出的话基本上无法保证优雅下线;所以能保证优雅下线的前提就是需要正确处理来自进程外部的信号。
- 停止流量接收:由于在停止之前,我们会有一些正在处理的请求,贸然退出会对这些请求产生损耗。但是在这段时间之内我们绝不能再接收新的业务请求,如果这是一个后台任务型(消息消费型或任务调度型)的程序,也要停止接收新的消息和任务。对于一个普通的 WEB 场景,这一块不同的场景实现的方式也会不一样,下面的 Srping Cloud 应用的下线流程会详细讲解。
- 销毁资源:常见的是一些系统资源,也包括一些缓存、锁的清理、同时也包括线程池、关闭阻塞中的的IO操作,等到我们这些服务器资源销毁之后,就可以通知主线程退出。
Spring Cloud应用
一个Spring boot应用通常由应用本身加一系列的Starter组成,对于Spring boot体系,需要了解如下核心概念:
- Starter:提供一系列的模块,由Spring boot核心通过auto-configuration机制加载。
- Bean:一切皆Bean,starter模块的加载产生各种Bean。
- Context:Bean的容器,容器拥有生命周期,Bean需要感知生命周期事件。
- LifeCycle:生命周期管理接口。
- ApplicationEvent:模块之间,模块与容器之间,通过发送或监听事件来达到互相通讯的目的。
所以对于应用上下线这个主题,我们应尽可能利用其丰富的原生事件机制,Spring Cloud 中内置的 Starter 机制针对整个生命周期管理的过程有了很好的封装。
Spring Cloud应用的优雅上线
Spring Cloud 启动过程触发回调及事件如下,详细介绍见application-events-and-listeners,简单罗列如下: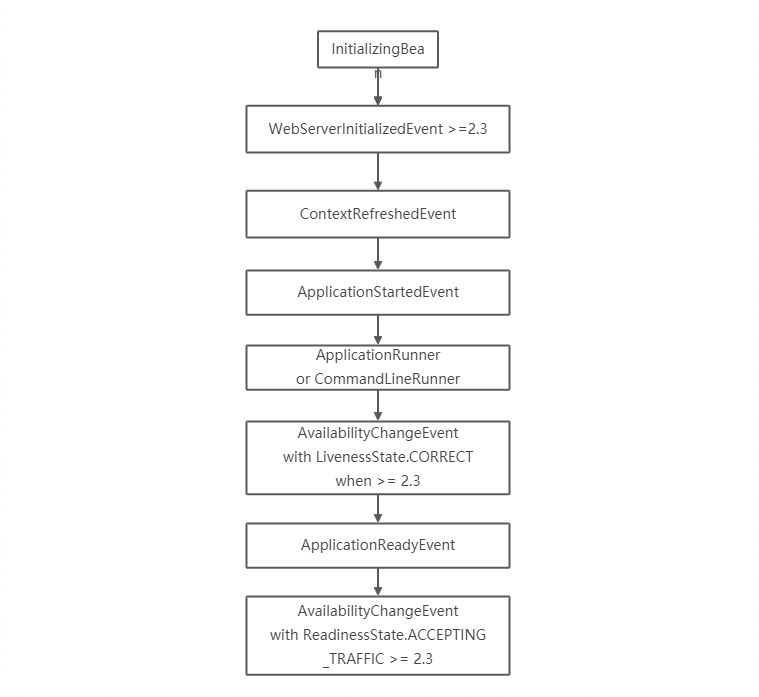
Spring自身及其组件大量基于这些事件构建,如响应WebServerInitializedEvent事件向服务注册中心注册服务,对于应用一般可利用:
- InitializingBean or @PostConstruct:在Bean装配完后,被回调,如完成数据源初始化连接。
- ApplicationReadyEvent、ApplicationRunner、CommandLineRunner:如开始监听消息队列,处理消息;注册到SLB等;先通过配置禁用服务的自动注册,在这里做手动服务注册。
Spring Cloud应用的优雅下线
Spring Cloud 本身可以作为一个应用单独存在,也可以是依附在一个微服务集群中,同时还能作为反向代理架构中的一个网关。不同的场景,需要用到的方法也不一样,我们就常用的三种场景针对性的加以说明。
场景一:直接访问WEB服务

客户端直接访问WEB应用,在这个用例下,优雅下线需要做的事情有:
- 正在处理的请求完成处理
- 应用自身完成的安全下线并正常退出
- 客户端感知到连接异常
Spring-boot从2.3开始内置了WEB应用优雅下线的能力,需配置如下,具体介绍参见graceful-shutdown
server.shutdown=graceful
spring.lifecycle.timeout-per-shutdown-phase=20s其实现方式:
- 首先关闭socket监听,等待正在处理的所有请求完成:具体可见WebServerGracefulShutdownLifecycle,通过getPhase返回最大值,达到早于WEB容器关闭执行的目的,
- 然后触发WEB容器关闭:具体可见WebServerStartStopLifecycle
但其实,对于未被WEB容器完全接收的请求,客户端仍会收到连接被重置的异常,只是这个时间窗口极小。该需求从提出到实现的时间跨度较长,感兴趣的可参见github上的讨论。
场景二:经由反向代理的服务优雅下线

因为实例前面还有反向代理,相比上个场景,需要新增“反向代理下线”这个处理流程。即若应用已经下线,但反向代理未摘除该应用实例时客户端将感知到失败。一般采取的策略有:
- 反向代理支持失败转移到其它应用实例
- 在关闭应用前,如将健康探测接口返回不健康以及等待足够的超时,让反向代理感知并摘除实例的路由信息。
对于仍在使用2.3以前版本的Spring Cloud应用,可参见一个方案,实现方式:
- 使用自身的shutdownHook替换Spring的shutdownHook
- 先改变health状态,等待一段时间,让反向代理感知并摘除实例的路由信息
场景三:在微服务集群中下线单个服务

在优雅关闭Spring Cloud应用自身之前,我们除了完成场景一之中的目标之外,还需要将自身节点从注册中心中下线。目前在Spring Cloud中针对注册中心下线的场景暂未提供开箱即用的方法,下面介绍两种可能的实现方案:
- 方案1:先通过脚本、或通过监听ContextClosedEvent反注册服务摘除流量;等待足够时间,如使用ribbon负载均衡器,需要长于配置的刷新时间;对于基于HTTP的服务,若Spring Cloud版本小于2.3,则时间需加上预期的请求处理时间。
- 方案2:客户端支持连接感知重试,如重试,实现方案可参考Spring-retry,针对连接异常RemoteConnectFailureException做重试。
针对 Eureka 中的场景,有一个很好的参考的例子,请参见:https://home1-oss.github.io/home1-oss-gitbook/release/docs/oss-eureka/GRACEFUL_SHUTDOWN.html
Kubernetes 下的机制
Kubernetes 中针对应用的的管控提供了丰富的手段,正常的情况他提供了应用生命周期中的灵活的扩展点,同时也支持自己扩展他的 Operator 自定义上下线的流程。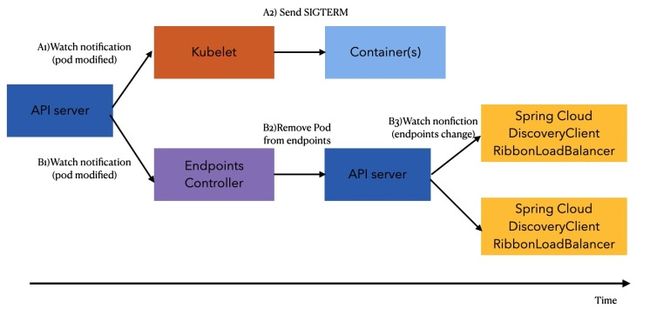
抛开实现成本,以下线的情况来说,一个 Kubernetes 应用实例下线之前,管控程序会向 POD 发送一个 SIGTERM 的信号,应用响应时除了额外响应这一个信号之外,还能触发一段自定义的 PreStop 的挂在脚本,代码样例如下:
yaml
lifecycle:
preStop:
exec:
command:
- sh
- -c
- "sleep 5"上面的例子一点特殊说明:因服务控制面刷新与POD收到SIGTERM同时发生,所以这里通过sleep 5让服务控制面先完成刷新,应用进程再响应SIGTERM信号。
Spring Cloud 与 Kubernetes 的结合
Kubernetes 会根据健康检查的情况来更新服务(Service)列表,其中如果 Liveness 失败,则会触发容器重建,这是一个相对很重的操作;若 Readiness 失败,则 Kubenetes 则默认不会将路由服务流量到相应的容器;基于这一基理,Spring Cloud 2.3开始,也做了原生的的支持,具体参见 liveness-and-readiness-probes-with-Spring-boot,这些健康检查端点可对接kubnetes相应的probe:
- /actuator/health/liveness
- /actuator/health/readiness
同时,Spring Boot 内置了相应的 API、事件、Health Check 监控,部分代码/配置片段如下:
java
// Available as a component in the application context
ApplicationAvailability availability;
LivenessState livenessState = availabilityProvider.getLivenessState();
ReadinessState readinessState = availabilityProvider.getReadinessState();
....
// 对于应用,也可以通过API,发布相应的事件,来改变应用的状态
AvailabilityChangeEvent.publish(this.eventPublisher, ex, LivenessState.BROKEN);
// 同时,应用监控也可影响这健康状态,将监控与健康关联,在K8S体系下,可以实现如离群摘除,应用自愈的能力
// application.properties
management.endpoint.health.group.liveness.include=livenessProbe,cacheCheck回到 Spring Cloud 应用 在微服务集群中下线单个服务 的章节中,我们的应用如果跑在 Kuberntes 中,如果我们使用了原生的 Kubernetes 机制去管理应用生命周期的话,只需要发布一个应用事件(LivenessState.BROKEN)即可实现优雅下线的能力。
EDAS提供内置的优雅上下线能力
通过上面两部分了解了 Spring Cloud 和 K8S 中的机制,EDAS 基于原生的机制,衍生出来了自己的方法,除了最大化利用这些能力:主动更新 Liveness、Readiness、Ribbon 服务列表之外,我们还提供了无代码侵入的开箱即用的能力,列举如下:
- 无损下线Spring Cloud应用
- 无损下线dubbo应用
- 使用离群实例摘除保障 Spring Cloud 应用的可用性
- 使用离群实例摘除保障 Dubbo 应用的可用性
后续
这一章节之后,和发布相关的内容都已经更新完毕,下一章节我们要开始高可用部分的能力,高可用也是系统保障 SLA 的关键部分,简单的理解是流量洪峰到来如何保证系统不会受到影响?当然我们还有一部分要达成的是洪峰退去之后资源是否存在浪费?敬请期待 ...