全文共2329字,推荐阅读时间10~15分钟。
文章共分四个部分:
-
作业分析
-
评测相关
-
重构策略
-
课程体验感受
作业分析
Unit2要求我们模拟现实生活中的电梯调度情景,迭代路径是单电梯->多电梯->特殊选层电梯。本单元的作业分析有独特的地方——因为三次作业都采用了一致的架构,因此以第三次作业的UML图为例即可了解整个单元迭代开发的过程。
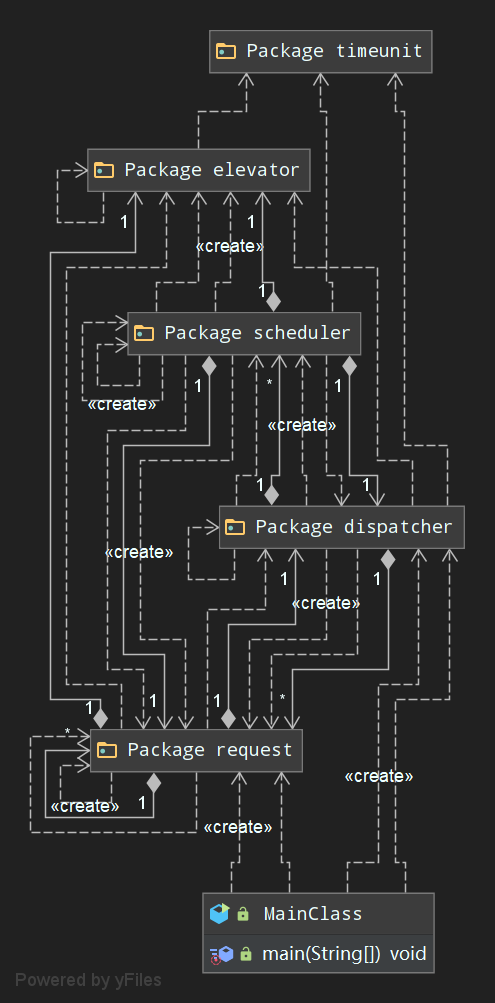
从UML图可以很直接地看出来整个系统的模拟思路:通过分包策略,让输入(request)、分配(dispatcher)、调度(scheduler)、电梯本身(elevator)、时间控制单元(timeunit)之间实现“透明调度”。所谓“透明调度”和工厂模式有异曲同工之妙,只要保证包与包之间的调用接口不变,那么内部实现可以任意改变。也正是因为这个原因,三次作业的类图均遵循了上图的包模式。说完架构,下面分别分析三次作业的代码质量评估。
第一次作业
第一次作业要求我们实现一个可捎带的单电梯模拟系统。
UML图如下
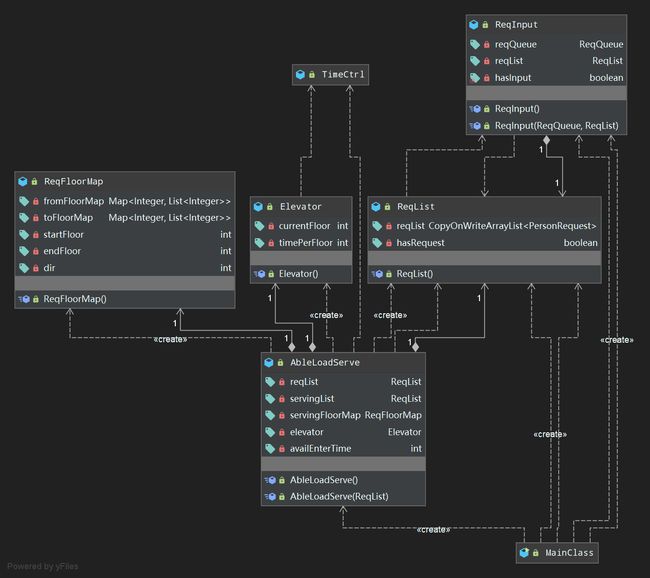
- 代码结构
结构可以大致分为三层,输入->调度->电梯运转,之所以把电梯运转单独拆出来,是因为电梯只有上下的功能,其他的带有判断逻辑的“自主意识”都在调度器中实现。
- 复杂度分析
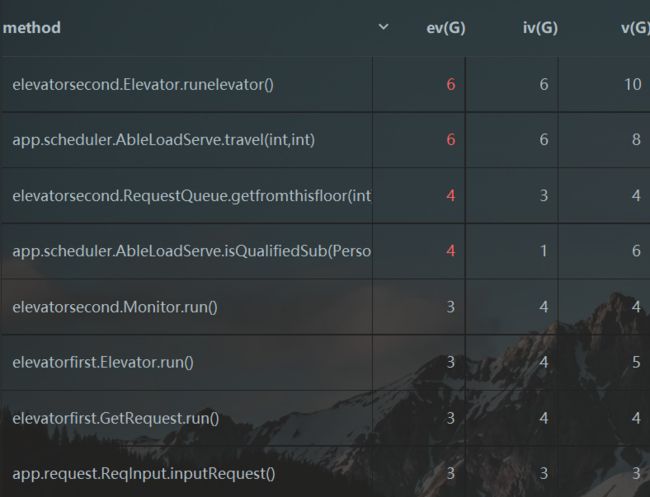
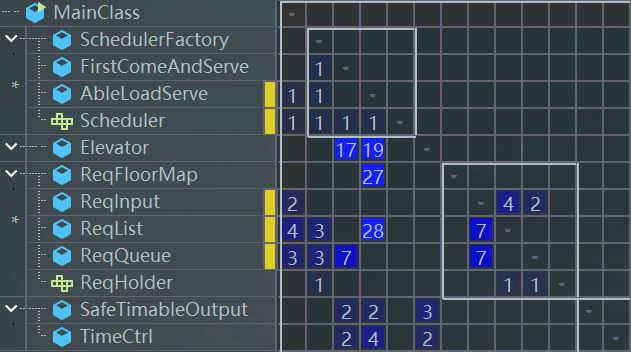
从反馈结果可以看出,由于把所有的判断逻辑都放进了调度器,造成了调度器的复杂度过高。在其他方法中,还是比较好的体现了“高内聚低耦合”的设计思想,均没有较高的复杂度。
第二次作业
第二次作业要求我们实现可稍带多电梯调度程序,并且能够自定义电梯数量。
UML图如下
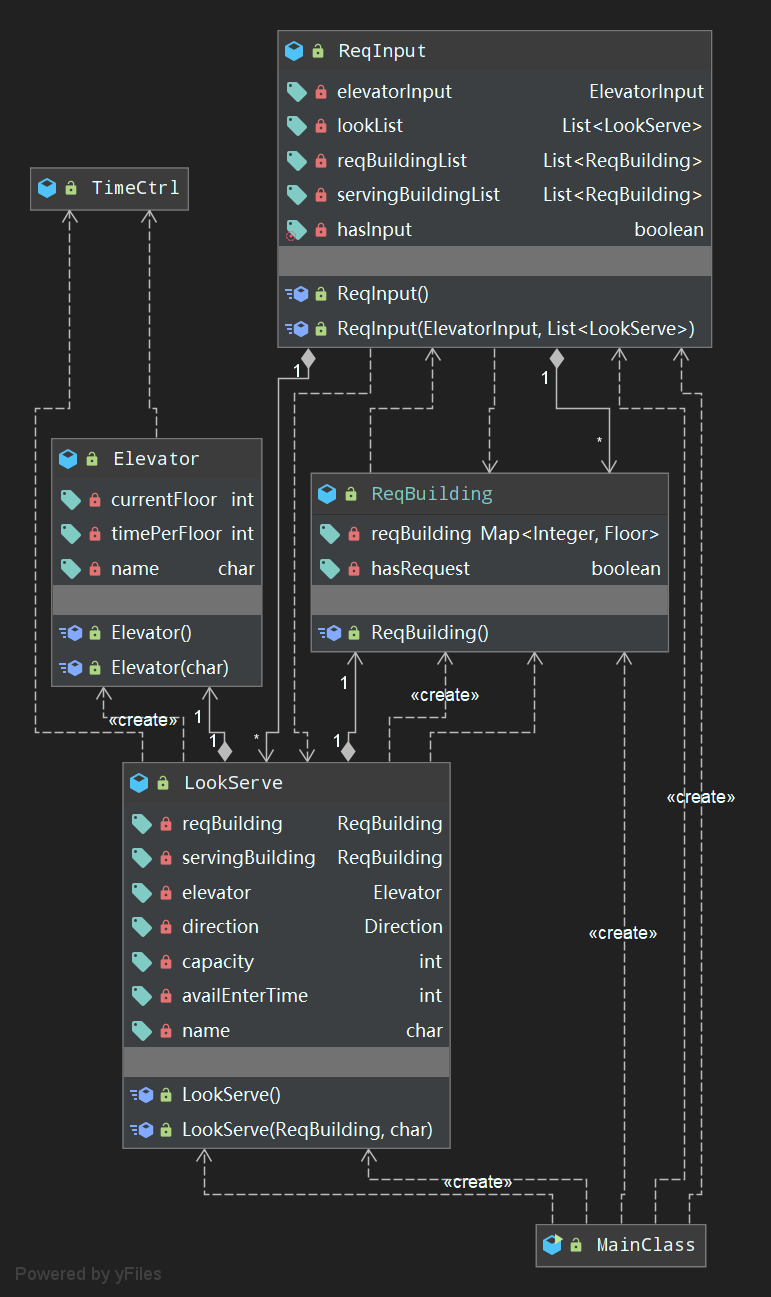
- 代码结构
代码架构基本延续了第一次的设计风格,虽然更换了调度策略,但是可以发现UML图的三层结构几乎没有变化。
- 复杂度分析

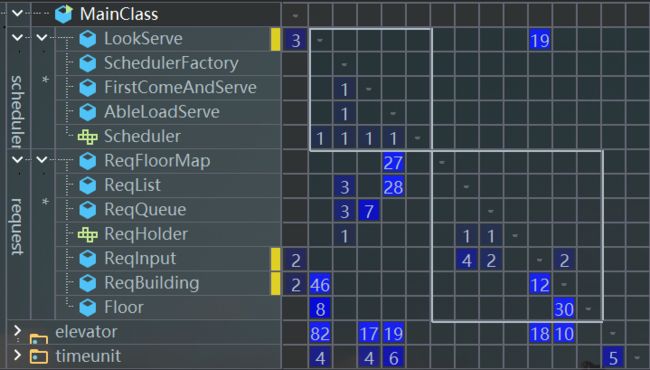
从反馈结果可以看出,由于这一次的多电梯要求,我把请求的输入和分配都放在了输入层,导致复杂度相比于第一次有所上升。现在回看起来,输入逻辑和分配逻辑完全可以分开实现,这样就可以保证输入类的“单责性”。
第三次作业
第三次作业要求我们实现可稍带的特殊电梯调度,并且可以动态改变电梯的数量。
UML图如下
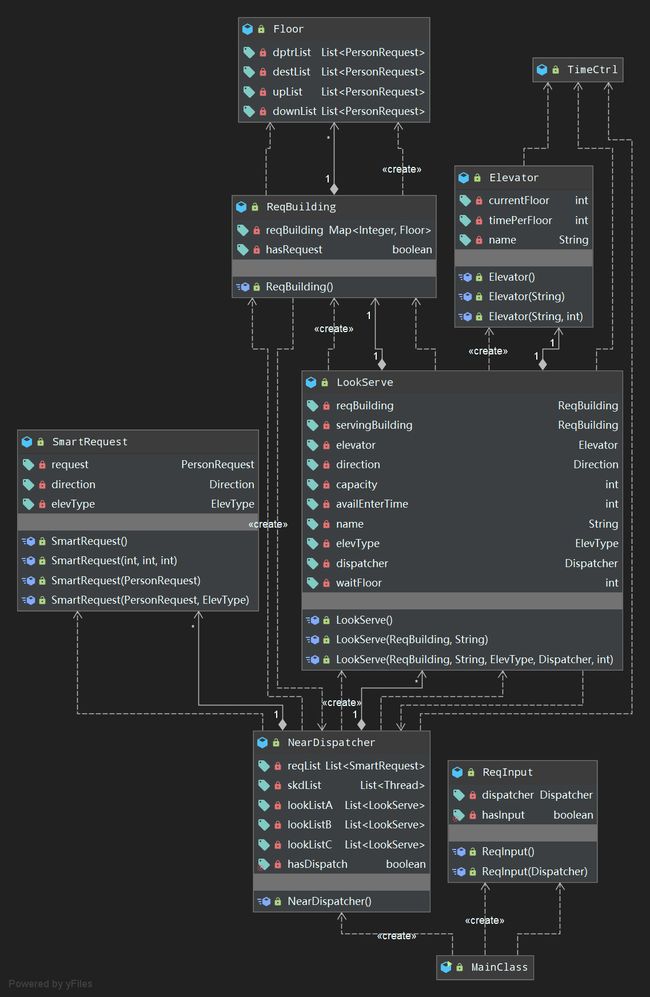
- 代码结构
代码架构基本延续了第一次的设计风格,在输入层增加了Dispatcher来实现分配逻辑。
- 复杂度分析
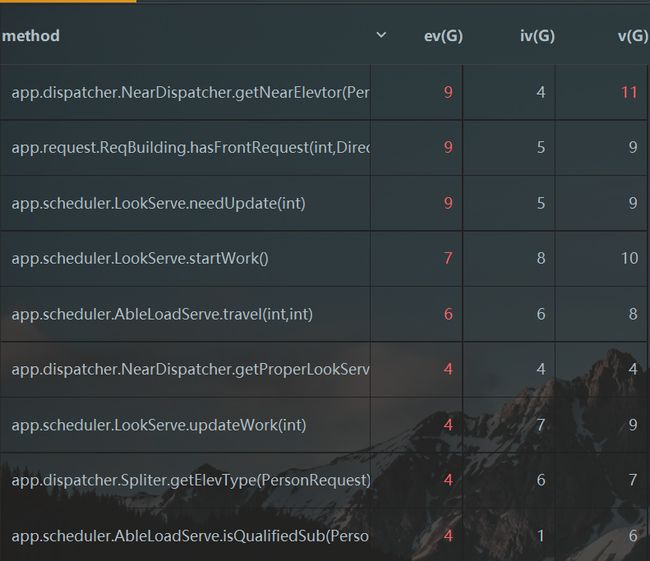
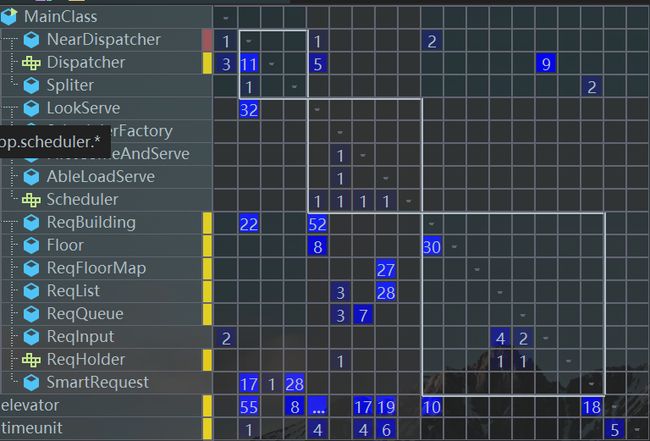
从反馈结果可以看到,由于Dispatcher的出现,原本复杂度很高的输入和调度层都有所改变,但是由于分配策略过于复杂,导致Dispatcher的复杂度变得很高,可以考虑再次切分分配策略:比如将一部分状态分析的方法放进调度器中直接实现一个反馈接口交给分派器。
SOLID Principle
S:单一功能原则O:开闭原则L:里氏替换原则I:接口隔离原则D:依赖反转原则
逐一分析,单一功能原则在每一次的迭代中都有不同程度的提升,比如Input和Dispatcher的分离;开闭原则体现得比较明显,因为更新调度器时除非采用不同的线程管理方式,其余部分都不用更改;里氏替换原则在本单元中不好展现,毕竟都没有继承关系。;接口隔离原则在一定程度上有助于实现前面提到的开闭原则;依赖反转原则是本单元让我体会最深刻的原则之一,因为先写上层架构,同时为下层留好待实现接口的方式,可以在开发过程中合并很多不必要的方法或者变量,同时更能够体现层次化思想。(感觉有点像先写评测机再做开发)
时序图(Sequence Diagram)

评测相关
详情见这里(https://www.cnblogs.com/silencejiang/p/12701979.html)
重难点聚焦
从三次开发和互测的过程来看,问题主要都在CPU时间上。这个问题之所以能够获得如此“殊荣”,主要是以下两个原因:
- 本地测试CPU时间
(啥玩意儿?) - 不只polling会导致过高的CPU时间,就算用
wait-notify,要是没操作好,结果是一样的。
对于第一点,在和大家的交流以及经过了学长的指点后,发现这个问题对win用户确实很不友好——在linux下使用time系统调用可以轻松地实现上述操作。但是,我们有万能的python——在time库中有一个神奇的函数process_time(),根据官方文档是可以实现和前者一样的功能的。但是,由于这个函数的subprocess的兼容性并不好,最后还是选择了前者。(I am so into Linux)
对于第二点,因为最开始设计的结束方式是在程序结尾统一notifyAll(),这样会导致程序和polling无异,CPU时间过高也就出现了。
Hack所用的策略
主要有两种方式:
- 使用完成作业时有意义的样例进行测试
- 利用评测机自己生成数据
评测机简要介绍
这是评测机的working directory
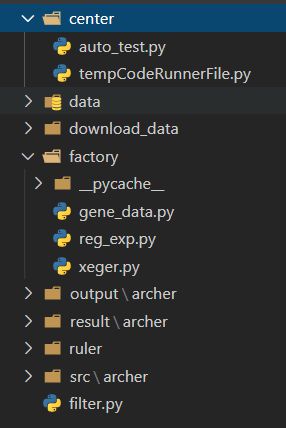
-
center:存放评测的核心控制代码,用于组织编译->运行->反馈功能 -
data:存放自动生成的数据 -
download_data:存放测试中出现问题的数据,可以用于回归测试。 -
factory:存放数据生成代码 -
output:存放各个测试代码的输出 -
result:存放各个测试代码的结果 -
ruler:存放标程 -
src:存放源码 -
filter.py:用于格式化数据以提交
本单元的评测机延续了上一单元的架构,但是加入了多线程评测和JAR包评测机制。原因很简单,多线程可以提高评测的速度,JAR包评测可以提高对不同架构程序评测的兼容性。
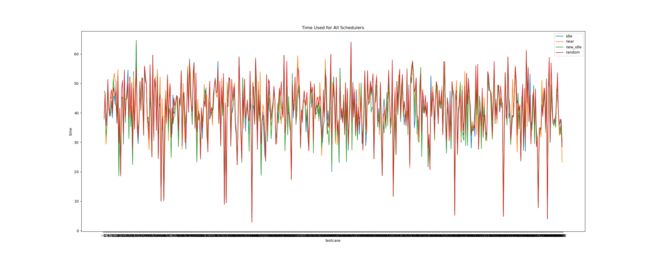
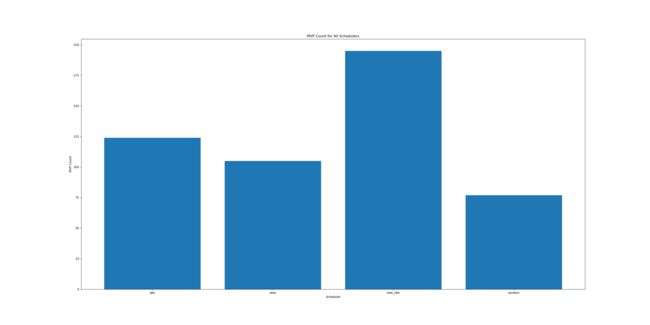
值得一提的是,本次加入了运行结果的可视化分析,分别是:
-
运行时间走势
-
在所有数据里取得最优解的次数
-
平均调度时间及其方差和标准差
(标准差在该情境下和方差等价)
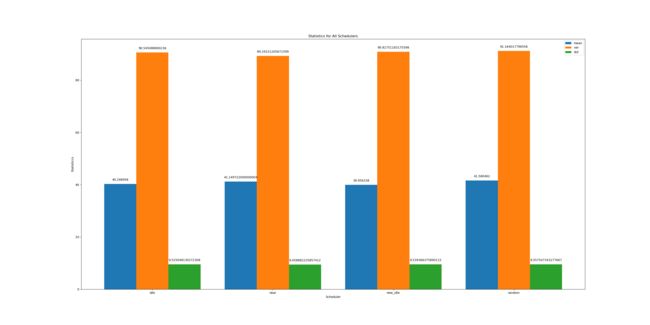
通过可视化分析,我逐渐明白一个道理:生活中的最优解用大数据的思想来探寻,比起挠头冥想会不会更轻松一点呢?
重构策略
在三次作业的完成过程中,我都是先确定好架构再开始完成的,所以没有遇到需要从头开始重构的情况。
但是值得一提的是,由于优化需求,每次都利用了上文提到的可视化思路进行策略的选择,因此调度策略在三次作业中都有或多或少的改变。同时,接口一致性保证了除了调度器之外的部分不需要进行逻辑上、架构上的修改。
课程体验感受
这一单元的迭代开发让我初步接触了现代软件开发的基本功:多线程。
总的来说体验良好,这种让计算机硬件发挥它最大作用的感觉非常棒。同时,也让我开始重新审视那些我自以为已经拿在手上的工具,比如Python.以前从来没有使用过Python的多线程模块,这次为了开发评测机就小有涉及;之前和matplotlib只是点头之交,现在逐渐觉得自己还要领会的东西真是数不胜数,期待未来的路上还会出现的小确幸吧。
最后一定要说的是:谢谢讨论区里的老师、助教、同学,是大家让我真正领会了一句很久以前看见的话:
一个人可以走得很快,但一群人才能走得更远。