第三单元总结
1.JML语法基础与工具
(1)JML表达式
JML的表达式是对Java表达式的扩展,新增了一些操作符和原子表达式。同样JML表达式中的操作符也有优先级的概念。
1 原子表达式
\result表达式:表示一个非void类型的方法执行所获得的结果,即方法执行后的返回值。
\old(expr)表达式:用来表示一个表达式expr在相应方法执行前的取值。该表达式涉及到评估expr中的对象是否发生变化,遵从Java的引用规则,即针对一个对象引用而言,只能判断引用本身是否发生变化,而不能判断引用所指向的对象实体内容是否发生变化。
\not_assigned(x,y,...)表达式:用来表示括号中的变量是否在方法执行过程中被赋值。如果没有被赋值,返回为true,否则返回false。
\not_modified(x,y,...)表达式:与上面的\not_assigned表达式类似,该表达式限制括号中的变量在方法执行期间的取值未发生变化。
\type(type)表达式:返回类型type对应的类型(Class),如type(boolean)为Boolean.TYPE。TYPE是JML采用的缩略表示,等同于Java中的java.lang.Class。
\typeof(expr)表达式:该表达式返回expr对应的准确类型。如\typeof(false)为Boolean.TYPE。
2 量化表达式
\forall表达式:全称量词修饰的表达式,表示对于给定范围内的元素,每个元素都满足相应的约束。
\exists表达式:存在量词修饰的表达式,表示对于给定范围内的元素,存在某个元素满足相应的约束。
\sum表达式:返回给定范围内的表达式的和。
\product表达式:返回给定范围内的表达式的连乘结果。
\max表达式:返回给定范围内的表达式的最大值。
\min表达式:返回给定范围内的表达式的最小值。
\num_of表达式:返回指定变量中满足相应条件的取值个数
3 集合表达式
集合构造表达式:可以在JML规格中构造一个局部的集合(容器),明确集合中可以包含的元素。
操作符
JML表达式中可以正常使用Java语言所定义的操作符,包括算术操作符、逻辑预算操作符等。此外,JML专门又定义了如下四类操作符。
(1) 子类型关系操作符:E1<:E2,如果类型E1是类型E2的子类型(sub type),则该表达式的结果为真,否则为假。
(2) 等价关系操作符:b_expr1<==>b_expr2或者b_expr1<=!=>b_expr2。
(3) 推理操作符:b_expr1>b_expr2或者b_expr2<b_expr1。
(4) 变量引用操作符:除了可以直接引用Java代码或者JML规格中定义的变量外,JML还提供了几个概括性的关键词来引用相关的变量。\nothing指示一个空集;\everything指示一个全集,即包括当前作用域下能够访问到的所有变量。
(2)方法规格
方法规格的核心内容包括三个方面,前置条件、后置条件和副作用约定。其中前置条件是对方法输入参数的限制,如果不满足前置条件,方法执行结果不可预测,或者说不保证方法执行结果的正确性;后置条件是对方法执行结果的限制,如果执行结果满足后置条件,则表示方法执行正确,否则执行错误。副作用指方法在执行过程中对输入对象或this对象进行了修改(对其成员变量进行了赋值,或者调用其修改方法)。
- 前置条件通过requires子句来表示:requires P;。其中requires是JML关键词,表达的意思是“要求调用者确保P为真”。
- 后置条件通过ensures子句来表示:ensures P;。其中ensures是JML关键词,表达的意思是“方法实现者确保方法执行返回结果一定满足谓词P的要求,即确保P为真”。
- 副作用指方法在执行过程中会修改对象的属性数据或者类的静态成员数据,从而给后续方法的执行带来影响。从方法规格的角度,必须要明确给出副作用范围。
(3)类型规格
指针对Java程序中定义的数据类型所设计的限制规则,一般而言,就是指针对类或接口所设计的约束规则。从面向对象角度来看,类或接口包含数据成员和方法成员的声明及或实现。
- 不变式(invariant)是要求在所有可见状态下都必须满足的特性,语法上定义invariant P,其中invariant为关键词,P为谓词。
- 状态变化约束constraint:对象的状态在变化时往往也许满足一些约束,这种约束本质上也是一种不变式。JML用constraint来对前序可见状态和当前可见状态的关系进行约束。
- 方法与类型规格的关系:大部分情况下,一个类有几种不同类别的方法:静态初始化、有状态静态方法、有状态构造方法、有状态非静态方法。
(4)工具
- OpenJML: 对JML进行规范性检查
- JMLUnitNg: 结合OpenJml可实现对代码的自动化测试。
2.SMT solver
openJML的配置令人绝望,配置方法参考了学长的博客:
https://www.cnblogs.com/lutingwang/p/openjml_basic.html
但在idea中仍然出现了无法解决的各种警告,最后使用eclipse勉强能够看。但似乎openJML对很多规格不支持,对这次程序本身没有任何帮助。。。
3.JMLUnitNG测试
JMLUnitNG使用过程中也是遇到了各种问题,主要是jdk版本不对,和测试文件中jml规格的问题,好像很多规格不支持。。。。
使用步骤:
- 将JMLUnitNG和openjml的jar包放入同一个文件夹中
- 将魔改后的测试文件也放入同一个文件夹中(不进行魔改会出各种难以解决的bug)
- 部署JMLUnitNg,需要执行以下步骤:
java -jar jmlunitng.jar test/Group.java
javac -cp jmlunitng.jar test/*.java
java -jar openjml.jar -rac test/Group.java test/Person.java
java -cp jmlunitng.jar test.Group_JML_Test
在神仙舍友帮助下,搞了搞MyGroup:
Passed: <>.addRelation(-2147483648, -2147483648, -2147483648)
Passed: <>.addRelation(0, -2147483648, -2147483648)
Passed: <>.addRelation(2147483647, -2147483648, -2147483648)
Passed: <>.addRelation(-2147483648, 0, -2147483648)
Passed: <>.addRelation(0, 0, -2147483648)
Passed: <>.addRelation(2147483647, 0, -2147483648)
Passed: <>.addRelation(-2147483648, 2147483647, -2147483648)
Passed: <>.addRelation(0, 2147483647, -2147483648)
Passed: <>.addRelation(2147483647, 2147483647, -2147483648)
Passed: <>.addRelation(-2147483648, -2147483648, 0)
Passed: <>.addRelation(0, -2147483648, 0)
Passed: <>.addRelation(2147483647, -2147483648, 0)
Passed: <>.addRelation(-2147483648, 0, 0)
Passed: <>.addRelation(0, 0, 0)
这里展示出来的都是通过的,没通过的都是带有空指针的奇怪数据,这里不做展示。
可以看到JMLUnitNG自动生成样例集中在各种边界数据上,对正常数据反而没有测试。因此可以说这个工具目前还是太过鸡肋。希望能尽快支持更多规格,对测试数据的生成能够更加优化。
4.作业构建策略
本单元实现的是一个社交网络系统,可以抽象成图的问题。person是节点,relaition是边,整个network是完整的图,而group则是子图。三次作业功能逐渐复杂化,但是都是基于图的一些问题。
第一次作业
第一次作业难度不大;基本没有很复杂的方法,基本都是按照jml规格原封不动的来写,也没有考虑容器的使用、时间复杂度等问题。
这一部分最难的函数isCircle采用了dfs的方法解决:
public void findWay(int id1, int id2, ArrayList personList) {
if (getPerson(id1).isLinked(getPerson(id2))) {
symbol = true;
} else {
MyPerson p1 = (MyPerson) getPerson(id1);
personList.add(p1);
Iterator iterator = p1.getAcquaintance().keySet().iterator();
while (iterator.hasNext()) {
Person tmp = iterator.next();
if (!personList.contains(tmp)) {
findWay(tmp.getId(), id2, personList);
}
}
}
}
但在后面看来这样解决真的很笨。。。
UML类图:
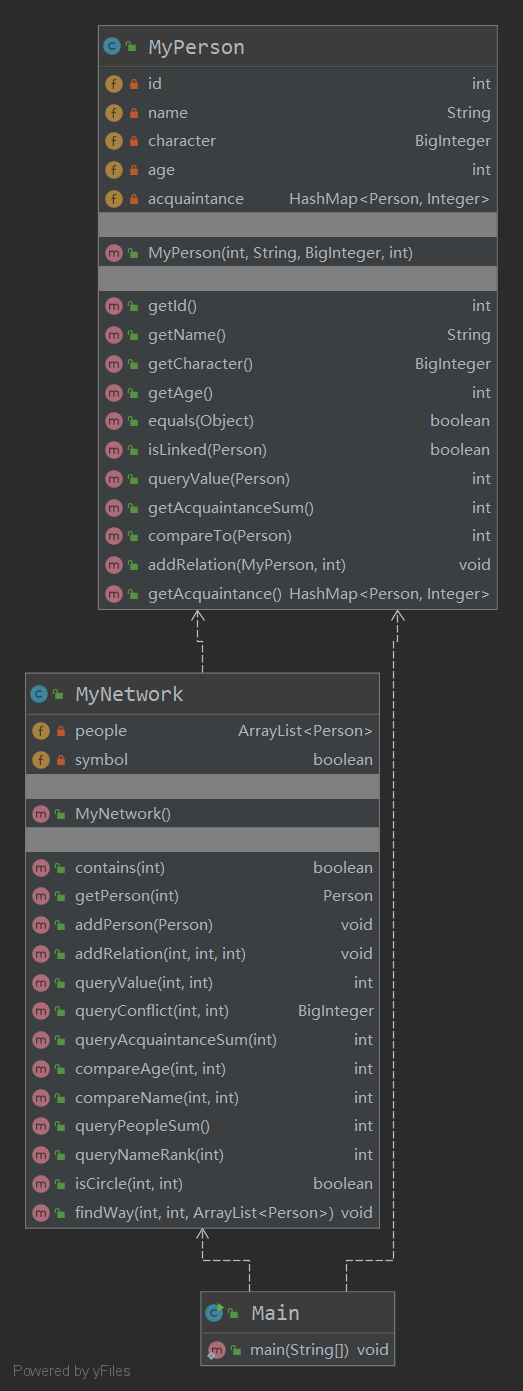
第二次作业
第二次作业增加了group类,在Group类中增加了很多方法,一开始写的时候还是根据jml规格来写。后来发觉这样的话肯定会超时,便在group类中加了一些类变量,并修改了Group里的addPerson方法:
public void addPerson(Person person) {
for (Person p : people) {
if (person.isLinked(p)) {
relationSum += 2;
valueSum += 2 * person.queryValue(p);
}
}
people.add(person);
size++;
ageSum += person.getAge();
relationSum++;
if (size == 1) {
conflictSum = people.get(0).getCharacter();
} else {
conflictSum = conflictSum.xor(people.get(size - 1).getCharacter());
}
}
把group中要计算的各种量在添加人的时候就计算好,这样节省了很多时间。同时将netWork中的isCircle改成了bfs防止爆栈。
public boolean isCircle(int id1, int id2) throws PersonIdNotFoundException {
if (contains(id1) && contains(id2)) {
if (id1 == id2) {
return true;
}
Queue personQueue = new LinkedList<>();
personQueue.add(getPerson(id1));
ArrayList personList = new ArrayList<>();
while (personQueue.size() > 0) {
MyPerson p = (MyPerson) personQueue.poll();
personList.add(p);
for (Person q : p.getAcquaintance().keySet()) {
if (q.getId() == id2) {
return true;
}
if (!personList.contains(q)) {
personQueue.add(q);
}
}
}
return false;
} else {
throw new PersonIdNotFoundException();
}
}
UML类图:
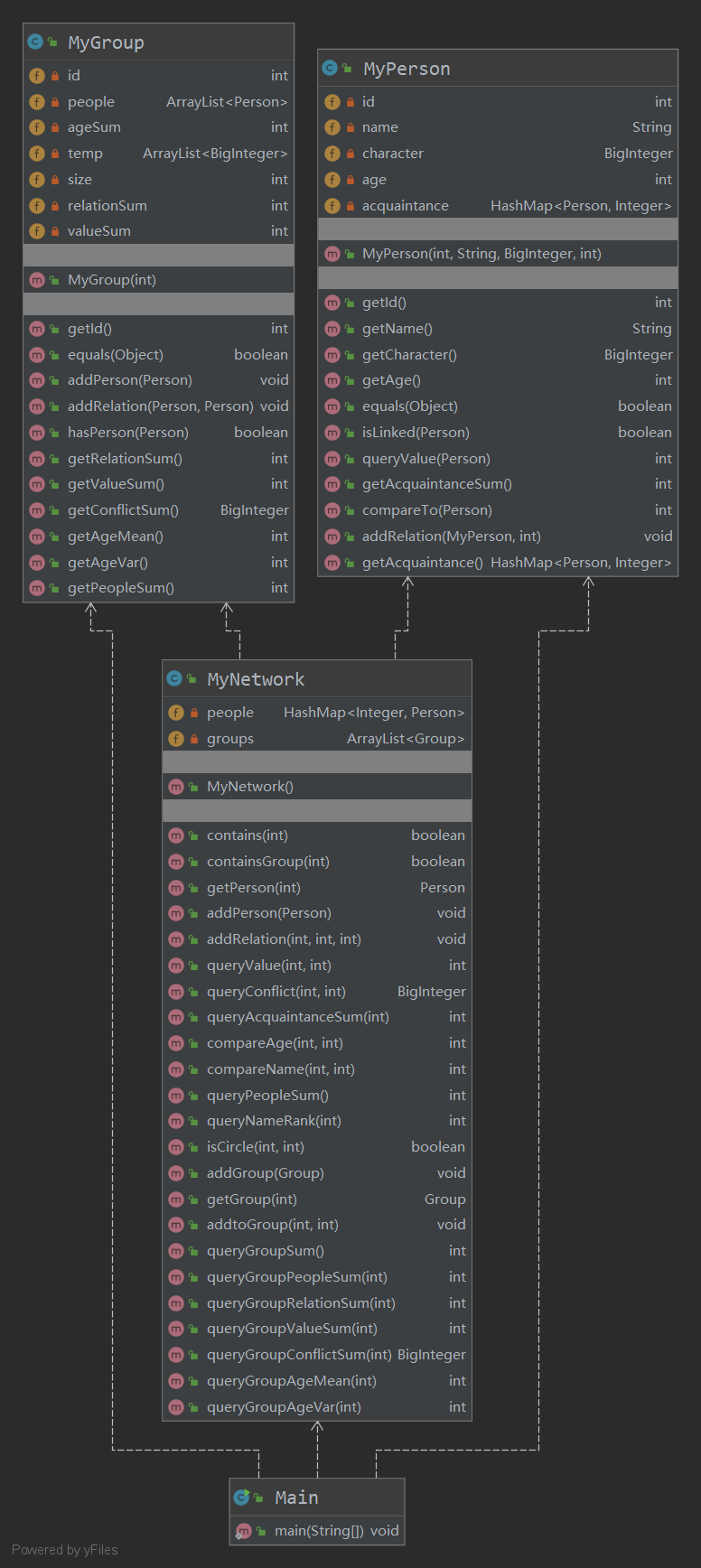
第三次作业
第三次作业新增函数不多,但是难度很大,难度集中在qbs,qmp,qsl中。
为了快速实现qps,特在netWork中增加了blocks变量。用来保存每个人对应的块号。blocks在addPerson与addRelation的时候进行维护。这样一来,isCircle不需要复杂的dfs和bfs来实现,而只需要在blocks中查询两人块号是否相同即可。
对于qmp,使用了常规的迪杰克斯拉算法(并没有用堆优化),强测的时候过然tle了。
对于qsl,是花费了我最多时间的函数。一开始就是简单的使用了两次dfs,后来自己发觉出来问题,但没有什么好的办法,于是硬着头皮学习了tarjan算法,也算是掌握了一种新的算法:
public void tarjan(int id1, int fatherId) {
MyPerson person = (MyPerson) getPerson(id1);
nodeNum++;
dfn.put(person.getId(), nodeNum);
low.put(person.getId(), nodeNum);
for (int id : person.getAcquaintance().keySet()) {
if (blocks.get(id1).equals(blocks.get(id))) { //同一块中
if (dfn.get(id) == -1) {
stack.push(new Edge(id1, id));
tarjan(id, person.getId());
low.put(id1, Math.min(low.get(id1), low.get(id)));
if (low.get(id) >= dfn.get(id1)) {
ArrayList edgeList = new ArrayList<>();
ArrayList idList = new ArrayList<>();
while (!stack.isEmpty()) {
Edge edge = stack.pop();
edgeList.add(edge);
if (edge.equals(new Edge(id1, id))) {
break;
}
}
for (Edge e : edgeList) {
if (!idList.contains(e.getBegin())) {
idList.add(e.getBegin());
}
if (!idList.contains(e.getEnd())) {
idList.add(e.getEnd());
}
}
bcc.add(idList);
}
} else if (dfn.get(id) < dfn.get(id1) && id != fatherId) {
stack.push(new Edge(id1, id));
low.put(id1, Math.min(low.get(id1), dfn.get(id)));
}
}
}
}
(关于点双连通分量这里采用了边入栈的方法,网上说点入栈会存在问题,但是具体原因没有太理解。)
UML图:
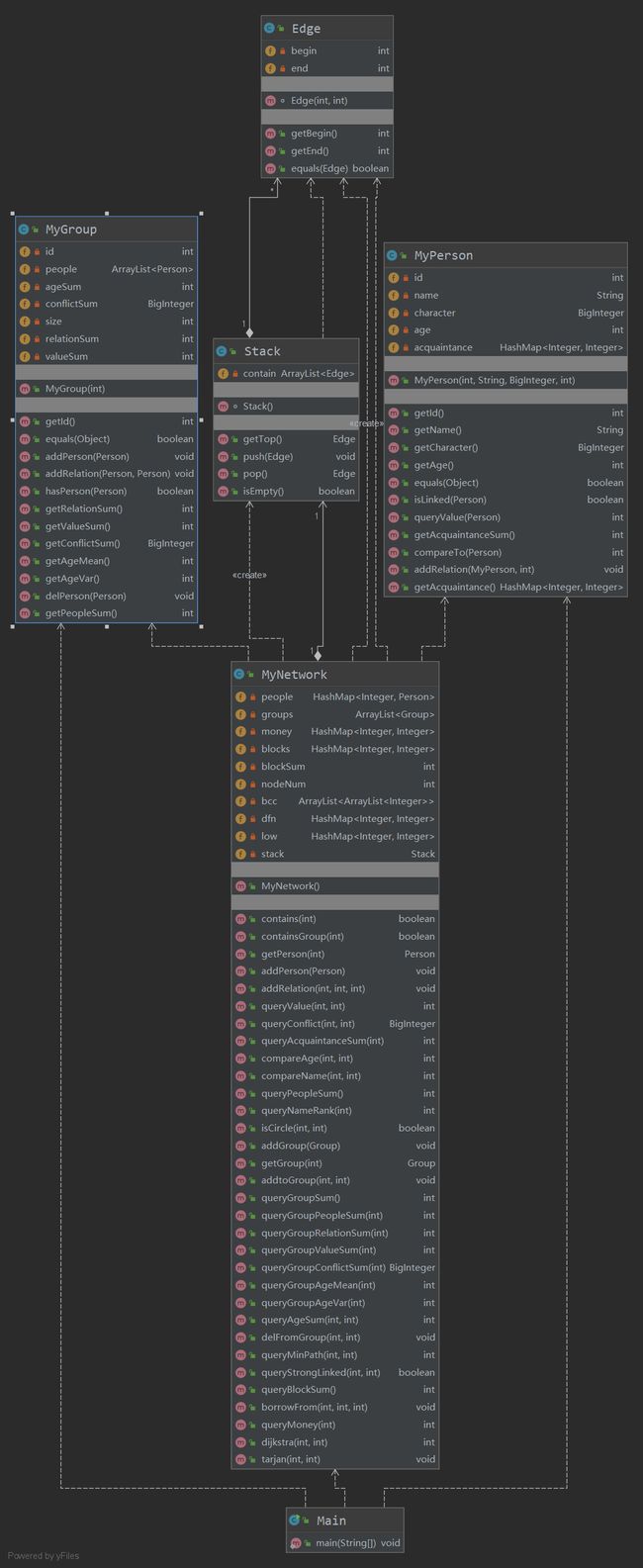
5.bug分析
第一次作业
由于第一次作业难度不大而没有仔细对着规格进行检查,第一次作业爆了0。错误原因有二,第一就是很多人都烦的,isCircle中没有特判id相同的情况,另外一个是一处异常抛出的时候条件写错(具体位置忘记了)。
第二次作业
经历了第一次的挫折,第二次在写完之后进行了相对详尽的检查。但最终还是存在一个错误,在addtoGroup之中有一个抛出异常的条件里把id1,id2弄反了。
第三次作业
第三次作业又出现了很多错误,包括一个异常抛出的条件写错,自己新增的变量block的块号设置的不好出现重复,以及迪杰克斯拉算法没有堆优化出现tle。觉得这么多错还能50分简直是个奇迹。。。
6.总结与感想
之前从来没有听说过规格这种东西,在这单元的学习之后算是对它有了一个初步认识。规格是对程序的一种理想约束。规格撰写者并不考虑程序内部的具体执行,而是像黑盒一样给出宏观的功能。而代码编写者在功能实现上有充足的自由发挥空间,来优化时间空间复杂度。我认为jml确实需要一套完善的工具链,这样才能最大程度的实现其功能,而我们目前并没有这样的条件,因此会感觉到有点鸡肋。
关于作业,这单元出现了本学期第一次爆零,的确是因为自己轻敌导致的。之后两次很多较难实现的算法也算是对数据结构和离散数学的一种复习。总而言之,这单元收获还是很丰富的。