一、基于度量来分析自己的程序结构
第一次作业
第一次作业中,我主要把程序分为了三个层次:MainClass - Polynomial - Monomial,其中多项式之间通过x或者数字后紧接的加减符号进行分割,之后将各个项通过正则表达式进行判断,分为如下五类:常数项、只包含指数、只包含系数、包含系数和指数、只包含系数为±1且省略。分类之后通过乘号的位置可以很方面的提取出系数和指数部分。
我将每一项保存在一个指数和项映射的TreeMap中,将 TreeMap 的 key 值设置为指数有助于之后合并同类项。
这一次作业相对来说比较基础,更多的是对容器的选择和 BigInteger 的使用,在程序的设计方面并没有很麻烦的地方。
第一次作业的UML图如下所示,可见整个程序的类不多,在设计上也较多偏向于面向过程的结构。

第一次作业代码行数:
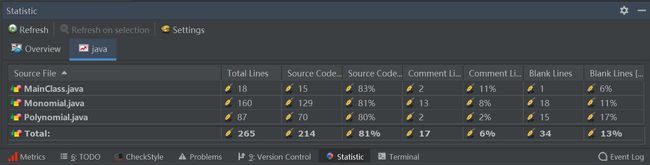
第一次作业复杂度分析:
第二次作业
第二次作业中,我仍然将程序分为了Expression - Term - Factor 三个层次,虽然每个类的名称有所改变,但是层次架构和第一次作业还是一致的。
在 Factor 这一个层次中,我将 Factor 这个类设置为了抽象类,并且在此基础上产生了常数项、幂函数项、Sin函数、Cos函数四个子类,每个类都有不同的求导和转化成字符串的方法,当 Expression 和 Term 需要求导或者转化成字符串输出时,只要通过调用子类中的相关方法即可。
跟第一次作业还略有不同的是保存Term的容器的 key 从单个的Index转变成了包含幂函数、Sin、Cos三个函数的Index的类,还是为了方便合并同类项。
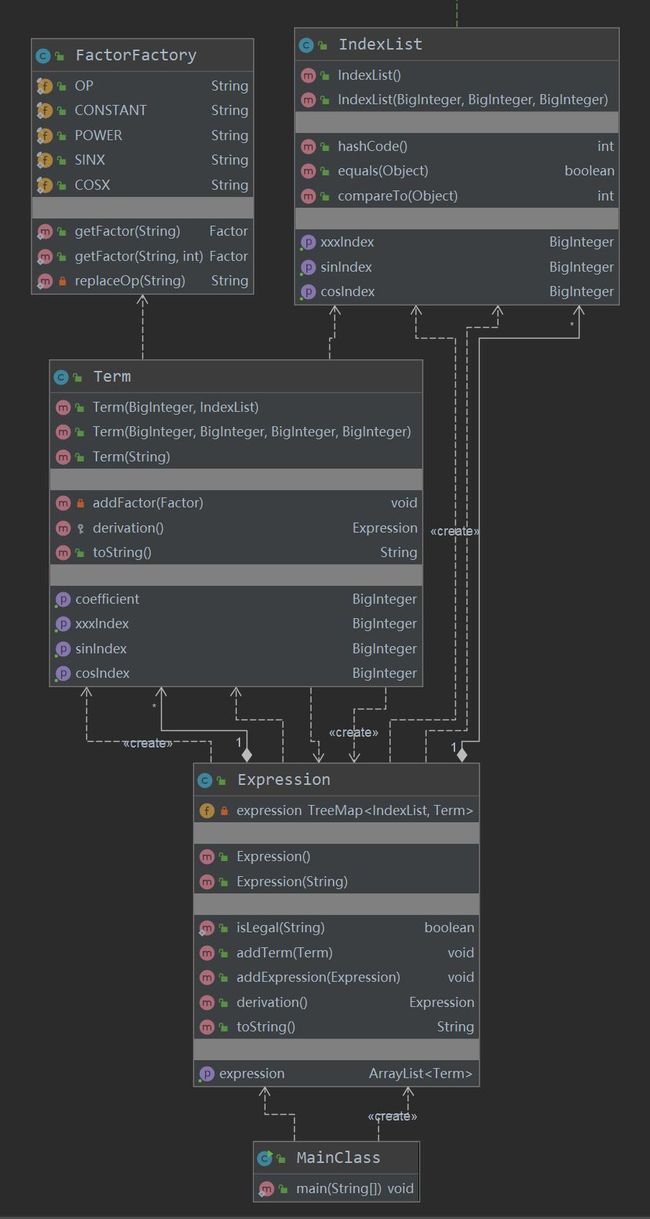
第二次作业UML图关于整体框架部分如下:
第二次作业中关于 Factor 部分的类定义和创建,我尝试使用了工厂模式,相关的UML图如下:
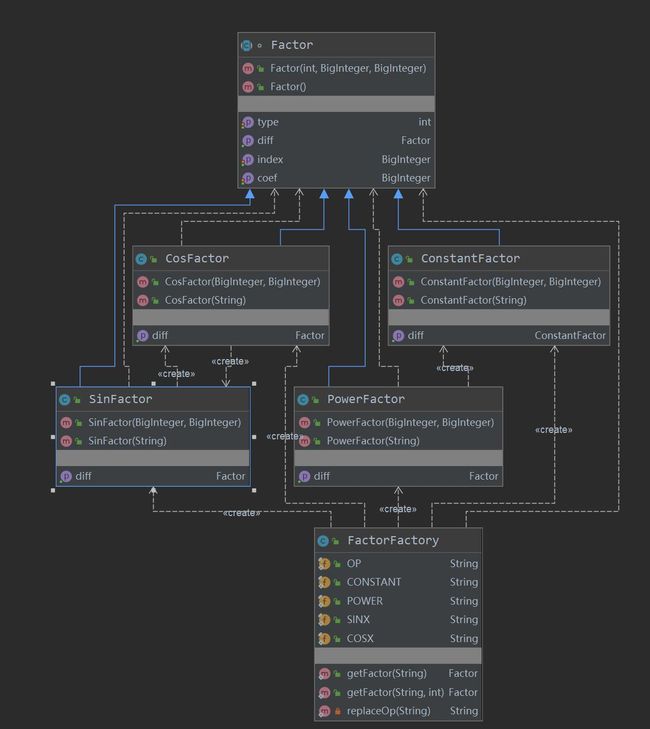
在 FactorFactory 这个类中,我尝试使用了正则表达式结合工厂模式对因子进行归一化处理。
第二次作业代码行数如下:
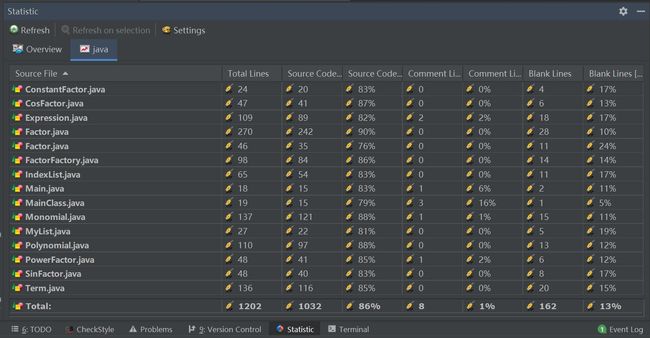
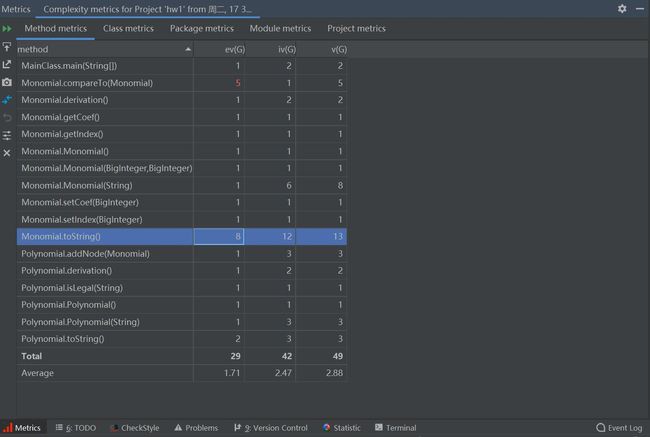
第二次作业的Metrics图如下:
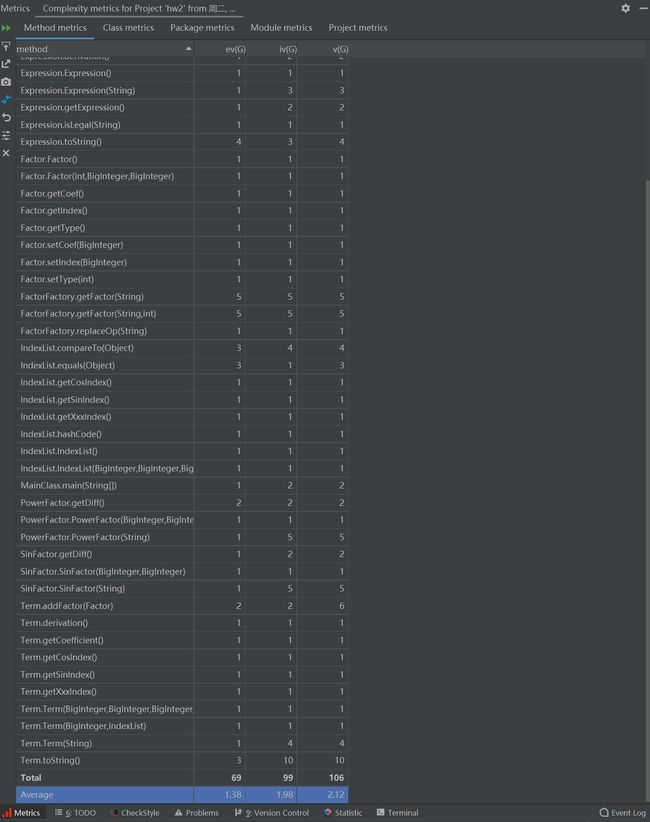
由于第二次作业中的类和方法比较多,可以简单地看下类的复杂度:
第三次作业
第三次作业是本单元中最难的一关,主要难度在于嵌套等规则的加入,使得原来的求导方法以及分割方法在这一次作业中全部不适用了。
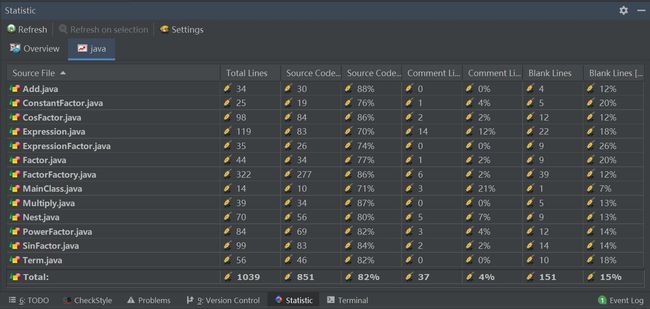
第三次作业代码行数如下:
第三次作业整体框架的UML图如下:
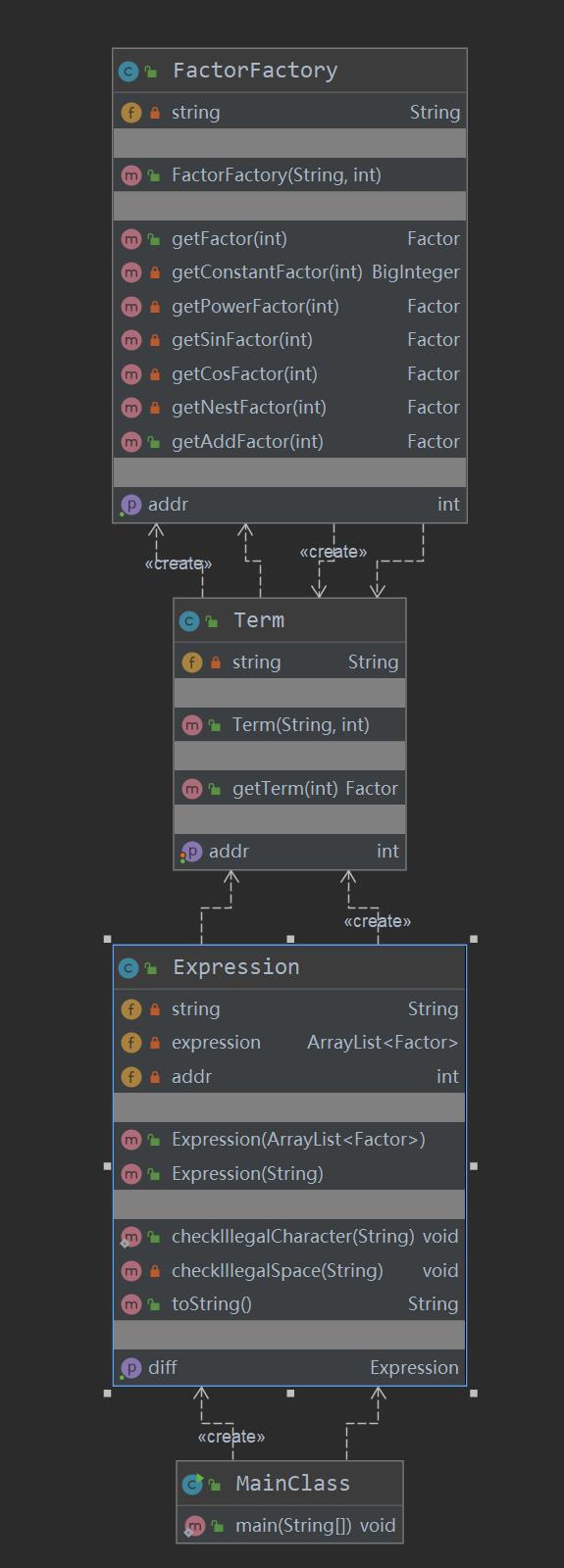
Factor 相关类的具体构建如下UML图:
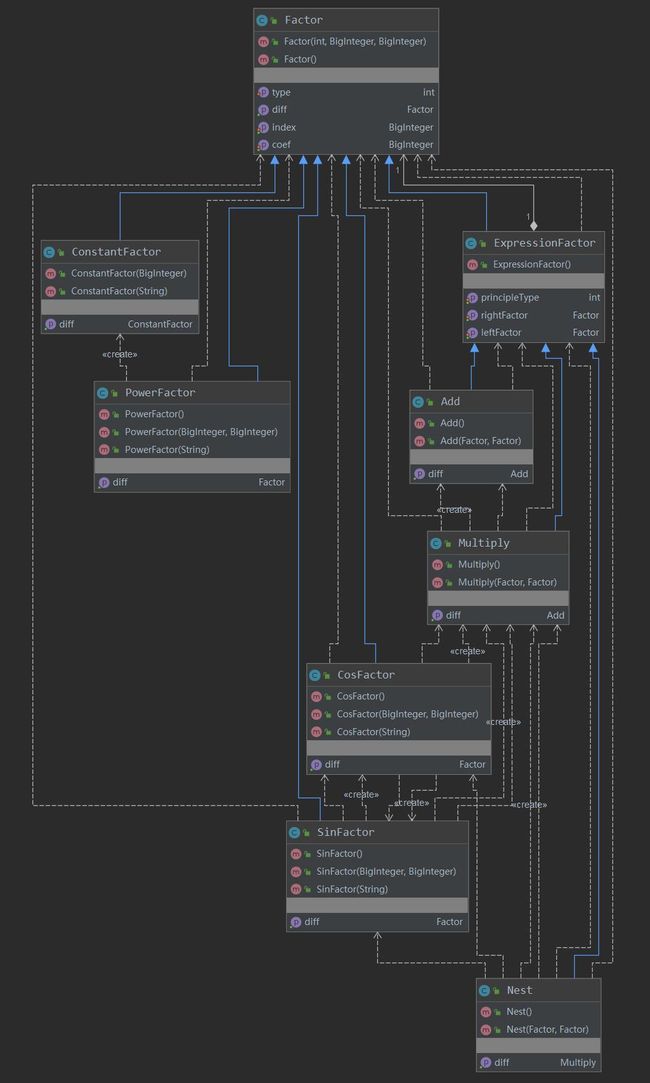
与前两次不同,在第三次作业中,新加入了关于运算规则的 Factor 类,他们都继承自 ExpressionFactor 类下,分别有Add、Multiply、Nest三个子类,并且每个都有对应的求导方法,便于对表达式的处理。
第三次作业的Metrics图如下:
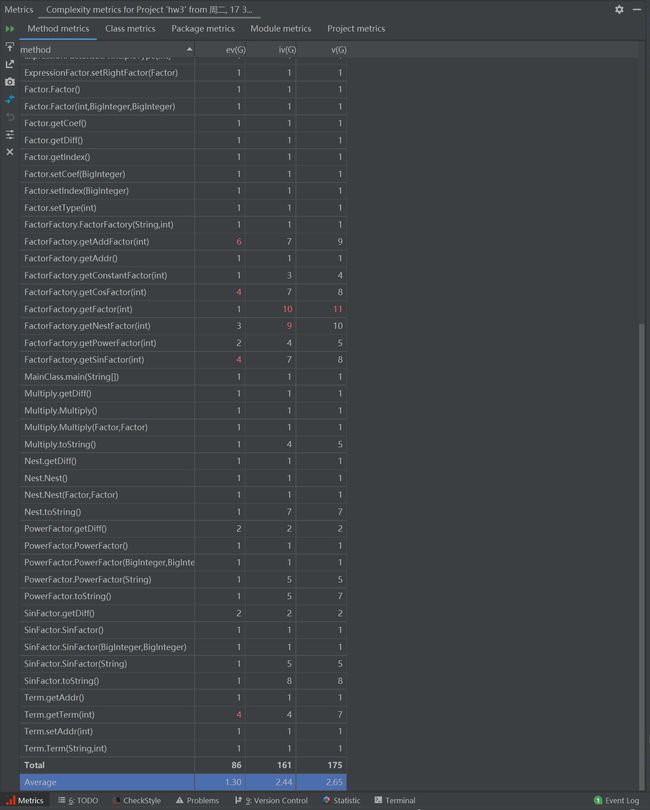
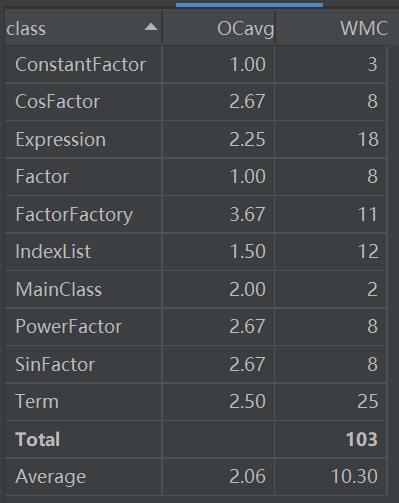
由于第三次作业中类和方法过多,对于类的复杂度分析可以更直观地体现其中的关系:
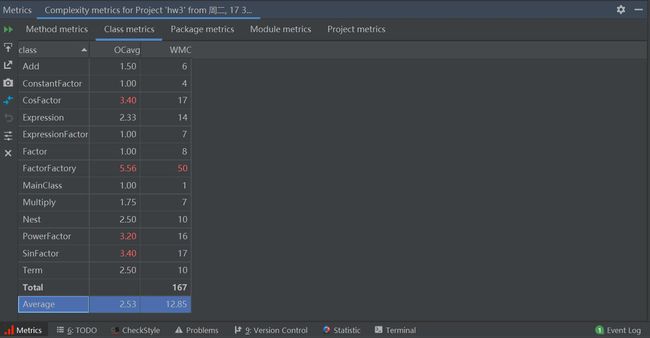
我们可以发现,由于SinFactor、CosFactor、PowerFactor由于在嵌套以及纯因子中使用十分频繁,导致该类复杂度开始飘红。
二、分析自己程序的bug
在第一次作业中由于程序相对而言较为简单,所以在公测和互测中都没有发现bug。
第二次作业中,我的主要问题在于空格的处理,尤其是 WF 相关要求的加入,不能像第一次作业那样简单地删除所有的空格并且对连续出现的符号进行合并,这也导致了我的程序在判断一些非法空格时考虑得不够周密,导致出现了一些bug。
第三次作业中,我的主要问题在于符号的处理,由于第三次作业加入了嵌套括号等内容,所以在符号处理上会变得更加复杂,比如括号外符号和因子前的符号的合并。
三、分析自己发现别人程序bug所采用的策略
测试主要分为手动测试和自动测试两部分。
手动测试也分为黑箱测试和白箱测试两种。黑箱测试是在还没看过代码的情况下,对一些常见出错以及一些边界情况进行检测,比如空字符串等情况。然后是白箱测试,就是阅读同学代码后有针对性地进行测试。
除了手动测试之外,自动测试无疑是效率更高的测试方法。利用Python的自动化正则表达式生成器,可以进行大规模的测试。虽然自动化测试在覆盖度上并不能做到很广,测试数据的针对性也不是很高。但是在自动化测试的大规模数据的测试下,程序的正确性还是有一定保证的。
四、应用对象创建模式来重构
从第二次作业开始,我开始使用工厂模式的创建模式。
在我的设计中,我希望利用表达式构建出一棵表达式树,其中规则相关的 Factor 作为分支节点而前两次作业中就有的函数 Factor 则作为叶节点。
现在想来,在设计的时候应该把工厂也分成多个子工厂更加方便,在我第三次作业中使用的还是单一工厂模式,所以 FactorFactory 身兼多任,就难免出现内部复杂度过高的问题,这也不方便后续的优化和测试。
五、对比和心得体会
第一单元的学习已经接近尾声,从第一次作业中最基础的系数和指数,到第三次作业中的各种复杂的嵌套,从一开始披着面向对象外皮的面向过程程序,到越来越有层次化的组织架构,慢慢从面向过程步入了面向对象的殿堂。
跟优秀的展示代码对比后,虽然我的思路大体一致,但是在一些细节设计上还是有一定的差距,比如因子的 Clone,字符串的预处理,以及类的划分和代码的组织方式。
回顾这个单元的学习,我觉得我最大的问题还是对代码测试的积极性不足。太过于依赖中测数据进行debug,有点为了完成任务才debug,没有那种为了自己的代码臻于完美而不断优化的积极性。这也导致了我在第二次和第三次作业的互测中,都被找出了不止一处错误。关于测试,我还要在自己的代码中注重模块化测试的方法。而不是只有对程序的整体性测试。
除了要提高测试的积极性之外,在之后的学习中我还要注意积累Java自带常用类的相关使用方法。
此外,我还要多阅读他人优秀的代码,从而学习更加优秀的构造组织方法以丰富自己的思路。