BUAA_OO_2020_UNIT3_Summary
本单元在阅读并理解JML规格的基础上,完成一个简单社交网络系统的迭代开发,该系统为实时在线系统,输入给出指令,需要及时给出正确的输出。训练重点为对规格的理解,数据结构和算法的选择,程序复杂度和时间的控制。
一、JML理论基础与应用工具链梳理
JML是一种类似于javadoc的,通过注释的方式对java代码规格进行规范的一种形式化语言。例如对类中的成员变量的规范描述,对类的功能的特征的规范描述,以及对类中各种方法的使用条件、正确执行结果、副作用等的一系列规范化的描述。与自然语言描述不同的是,JML具有严格的形式化描述,它引入了离散数学中的谓词等的概念以及java语法中的部分运算符等,对代码规格进行数学化的、精确的描述。
在我看来,JML最大的好处在于,给代码设计者、实现者和使用者提供了一份严格的逻辑化的规约。设计者需要使用JML语言给出正确的规格设计;实现者按照JML规格,在充分理解的前提下,给出符合JML规格的代码实现;使用者在使用时,给出JML规格所规定的前置条件,则可得到JML描述的正确结果。此外,JML数学化的规范描述保证了它是一种无二义性的语言,即不会产生类似自然语言中的歧义问题。
JML的核心在于用表达式给出对数据规格、方法规格、类型规格的描述,下面简单梳理JML语法
- 注释结构:块注释为
/* @ annotation @*/,行注释为//@annotation - 原子表达式:
\result:表示方法执行后的返回值,类型为方法声明中所定义的返回值类型,通常采用\result == xxx的形式表示返回值\old(exp):表示表达式exp在方法执行前的值。注意对于对象引用变量,只能判断引用本身是否发生变化,而不能判断所指向的对象实体是否发生变化,因此在使用时一般将整个表达式括起来\not_assigned(x)、\not_modified(x):判断括号中的变量在方法执行过程中是否没有被赋值、改变,一般用于后置条件约束\nonnullelements(container):约束container中存储的对象不含nulltype(type)、typeof(exp):返回类型type、表达式exp对应的类型(Class)
- 量化表达式:
\forall:类似于全程量词,表示范围内的每个元素都满足约束。使用形式为(\forall T x; P(x); R(x)),其中:x为元素,P(x)为范围的表示,R(x)为应满足的约束条件\exists:类似于存在量词,表示范围内存在某个元素满足约束,使用形式与\forall相同\sum、\product、\max、\min等:返回给定范围内表达式的和、连乘结果、最大值、最小值。使用形式为\sum T x; P(x); exp(x),其中x为范围内变量,P(x)表示范围约束,exp(x)为求和、积、最大值、最小值的表达式\num_of:返回指定范围内满足约束的变量取值个数,使用形式同\forall,在语义上(\num_of T x; P(x); R(x))等同于(\sum T x; P(x)&&R(x); 1)
- 操作符:
- 子类型关系
<:,例如Integer.TYPE<:Object.TYPE - 等价关系
<==>, <=!=>:表示左右两个表达式相等或不等 - 推理关系
==>, <==:语义与离散数学中的蕴涵关系相同 - 变量引用:可直接引用java或规格中定义的变量,此外还有
\nothing表示空集,即没有变量;\everything表示全集,即能访问到的所有变量
- 子类型关系
- 数据规格:
/*@spec_public@*/:用来注释类的私有成员变量,表示在规格中是外部可见的- 此外,规格中所定义的public变量都是表示规格中外部可见,实际实现代码时不需要按照public来实现
- 方法规格:
requires:表示前置条件,是对方法输入参数的限制。后接谓词P,方法调用者需要保证P恒真。多个requires子句为并列关系,需要全部满足。若参数不满足前置条件,则方法执行结果不可预测ensures:表示后置条件,是对方法执行结果的约束。后接谓词P,方法实现者需要保证P恒真,否则方法执行错误assignable和modifiable:表示副作用,是对方法执行过程中对对象和类属性修改的限制,前者表示可赋值,后者表示可修改,一般可交换使用,限定范围常用变量名,或\everything和\nothingpure:表示被修饰的方法为轻量级的纯访问性方法,没有副作用。此外,若在方法规格中调用其他方法,只能调用pure修饰的方法public normal_behavior:表示接下来的部分为方法正常功能行为的规格描述public exceptional_behavior:表示接下来的部分为方法异常行为的规格描述signals:在异常行为规格中声明抛出的异常,使用形式为signals (Exception e) exp,即表达式exp满足时,抛出异常esignals_only:signals子句的简化版,后接异常类型,表示在满足异常行为规格的前置条件下直接抛出相应异常
also:分割多种行为(正常or异常)规格的关键词。此外,重写方法在补充规格时,需要在补充的规格前使用also
- 类型规格:
invariant:不变式,表示类和对象在所有可见状态下都应该满足的约束条件,即方法执行前后,都要保证不变式的满足constraint:状态变化约束,表示有副作用的方法,在执行前后对类和对象属性改变的约束条件
此外,JML有着许多应用工具链,其完整链接为:http://www.eecs.ucf.edu/~leavens/JML//download.shtml
下面梳理一些可用的工具链:
- OpenJml:使用SMT Solver检查程序是否满足所设计的规格,下载地址为:http://www.openjml.org/;此外可在Eclipse中安装插件结合使用,安装地址为:http://jmlspecs.sourceforge.net/openjml-updatesite/
- JMLUnitNG:根据规格自动化生成测试样例,进行单元测试,下载地址为:http://insttech.secretninjaformalmethods.org/software/jmlunitng/
二、部分工具链的部署与验证
1. SMT Solver
使用的命令:
java -jar .\openjml.jar -exec .\Solvers-windows\z3-4.3.2.exe -esc .\src\Person.java
效果如下:
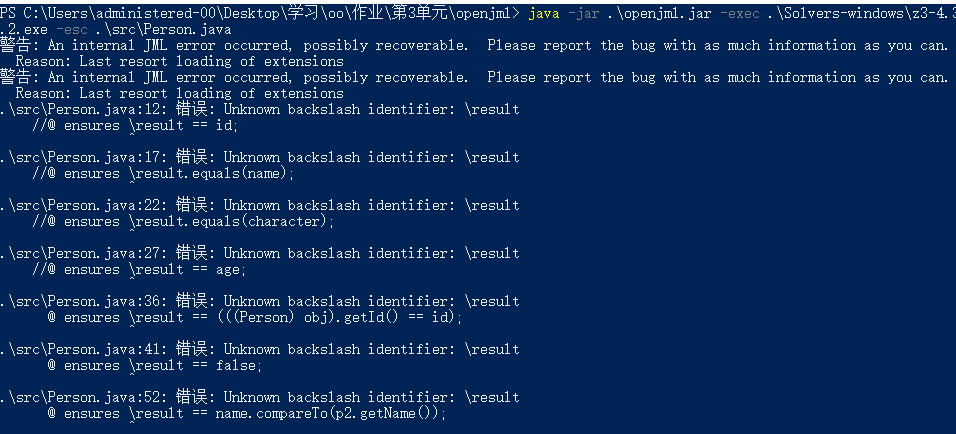
会出现很多莫名错误与异常,而且似乎不能识别\result,经多种方法尝试后均无果,遂放弃
2. JMLUnitNG
部署过程如下:
-
下载包并导入到项目文件,官网地址为:http://insttech.secretninjaformalmethods.org/software/jmlunitng/
-
在idea自带的终端输入命令:
java -jar xxx\jmlunitng.jar -d ./test ./src,注意jmlunitng包地址为绝对路径 -
命令执行结束后,会自动生成测试代码。需要将test文件夹通过Mark Directory as -> Test Sources Root设置为测试文件夹,否则测试文件无法运行。成功后的test目录如下图

-
运行上图中的MyGroup_JML_Test中的main函数,结果如下(截取部分)
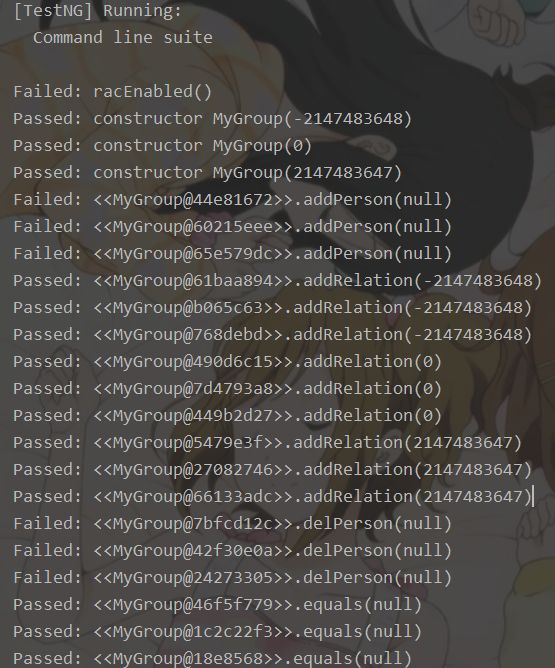
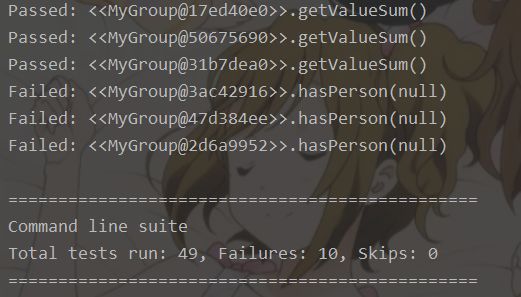
简要分析:可以看到,jmlunitng主要针对极端情况进行了一些数据的生成与测试,如参数为int型则测试0、INT_MAX、INT_MIN,参数为对象则测试null,因此覆盖度与可靠性远不如junit与黑盒测试,但是可以作为极端情况的检测
三、作业分析
HW9
1. 设计策略
-
架构设计:总体上按照规格实现相应的接口。
- 关于数据存储方面,全部采用HashMap
- 对于社交网络图中的边,即Person间的关系,抽象为类
Relation,存储与Person有关系的其他Person及对应的value,并提供get方法(代码如下)。同时在Person中用HashMap存储,id作为key值
public class Relation { private Person person; private int value; public Relation(Person person, int value) { this.person = person; this.value = value; } public Person getPerson() { return person; } public int getValue() { return value; } } - 关于数据存储方面,全部采用HashMap
-
方法实现:
- isCircle方法使用bfs实现,并用HashSet作为标记数组使用,存储Person的id值(初始化为空,将标记点加入set,判断某Person是否标记只需判断其id值是否在set中)
- isLinked方法注意自己与自己判断也是返回true,要认真阅读规格
- 其余方法按照规格描述实现即可,注意由于使用了HashMap,因此所有的contains类、get类和其他查询类方法可直接使用HashMap的containsKey和get方法实现
-
复杂度分析:isCircle复杂度为遍历图的复杂度O(N+M),queryNameRank复杂度为O(N),其余方法复杂度均为O(1),简单计算后可得满足时间限制条件
2. 代码度量
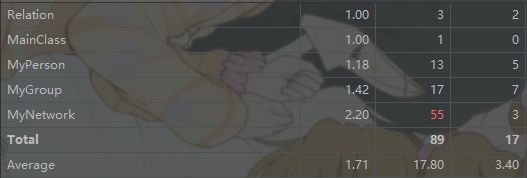
- UML类图:结构较为简单

- Metrics:MyNetwork类由于方法数较多,因此方法总复杂度较大,而平均复杂度则由于每个方法实现较为简单从而较小

HW10
1. 设计策略
-
架构设计:基本沿用HW9的架构,数据存储上同样采用HashMap
-
方法实现:
-
isCircle方法改用并查集实现,并用HashMap存储根节点,key与value分别是该节点与其祖先节点的id;在MyNetwork类中,通过路径压缩的getRootId方法与addRelation时的union操作,维护该map。
-
Group中的一系列查询方法,通过维护缓存变量实现(维护代码如下)。
- getRelationSum与getValueSum,返回相应的缓存变量relationSum与valueSum,在加人与加关系时均需要更新。前者需要遍历组中所有人,判断是否有关系并更新;后者是NetWork对已在组中的两人加关系时,需要遍历所有组并对同时包含这两人的组更新缓存(需要牺牲封闭性,通过非Override方法实现)。注意不同点间的边需要统计两次,自环只需统计一次。
- getConflictSum:返回缓存量conflictSum即可,初始化为
BigInteger.ZERO(利用0 xor A = A的性质),加人时按照定义更新即可 - getAgeMean与getAgeVar:通过缓存量ageSum与ageSquareSum(分别表示年龄和与年龄平方和)计算得到结果,在加人时需要更新。计算通过数学公式,注意精度需与规格保持一致,以及除0问题
public void addPerson(Person person) { this.ageSum += person.getAge(); this.ageSquareSum += person.getAge() * person.getAge(); this.conflictSum = this.conflictSum.xor(person.getCharacter()); for (Map.Entry -
其余方法沿用HW9的方式,按照规格实现即可
-
-
复杂度分析:
- isCircle使用并查集,复杂度降低到O(α)(α $\le$3)
- Group中一系列查询方法(以及Network中对应的询问方法),由于直接返回缓存量或通过缓存量计算得出,复杂度为O(1)
- addPerson:由于需要更新缓存量,总复杂度为O(qN^2)(q为组数,N为组中人数),由于数据限制,\(q\le10\)且\(N\le1111\),因此不会超时
- 其他方法最高复杂度为O(N),经简单计算可得,在HW10的数据规模下不会超时
2. 代码度量
- UML类图:结构与HW9类似,增加了Group接口和MyGroup类

- Metrics:MyNetwork同样由于方法数太多而总复杂度较高,其平均复杂度与其他类的复杂度均较低
HW11
1. 设计策略
- 架构设计:基本沿用HW10的设计,同时将图有关算法抽象出来,设计为单独的类,并统一置于graph包中管理,使得MyNetwork的各种方法实现调用相关对象的相关方法即可,极大地减小了MyNetwork类的复杂度,最终该类只有300行左右
- 方法实现:
- delFromGroup:调用Group中的delPerson方法,注意该方法在实现时,需要与addPerson相同,对缓存量进行更新
- queryMinPath,采用堆优化的迪杰斯特拉算法,并使用内置小顶堆的java容器PriorityQueue,存储二元量
- queryStrongLinked,采用tarjan算法求无向图中的点双连通分量的方法实现。同样使用HashMap和HashSet容器用作各种数组;此外用HashSet存储求出的点双连通分量内的点,并用ArrayList存储点数超过2的set。查询时先将图用tarjan计算一遍,然后查询ArrayList中是否有包含目标两点的set,是则返回true,否则返回false
- queryBlockSum,在并查集中维护成员变量blockSum的值,初始化为0,加点时加一,成功合并原来两个不同的集合后减一,则该值即为图中连通块的数目,返回即可
- 其余方法实现沿用HW10的策略,或按照规格实现
- 复杂度分析:
- addPerson与delPerson调用次数由于删人的存在,不受限于组人数;但由于总指令不超过3000条,因此仍然不会超时
- queryMinPath:堆优化后一次调用的复杂度为O(ElogE)(E为总边数,不超过3000),虽然指令数未作限制,经计算后仍不会超时(若使用朴素的dij算法而不堆优化,则会有ctle的可能)
- queryStrongLinked:本质为将图dfs遍历一边,因此复杂度为O(V+E),加上指令条数的限制,因此不会超时(此外若采用删点法,虽然复杂度为O(qN^2),但由于q\(\le20\),所以也不会超时)
- 其余方法复杂度最高为O(N),在HW11的数据规模下不会超时
2. 代码度量
- UML类图:引入了图算法类,整体架构较为清晰
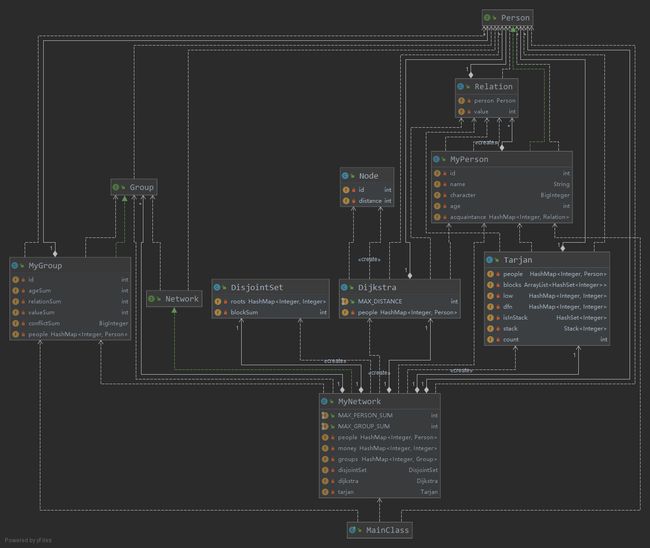
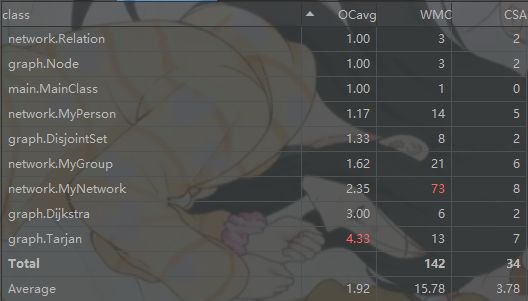
- Metrics:Dijkstra和Tarjan由于算法较为复杂而平均复杂度较高,其余类平均复杂度较低(MyNetwork仍然由于方法太多而总复杂度飘红,说明实现时架构设计仍然存在问题,应使该类功能更加分散)
四、测试与bug
1. bug
- 自测:HW11中处理qsl时,原本用并查集存储点双连通分量,后来发现这种做法会将不同的、但有一交点的两个点双连通分量(如下图)合并,产生bug。后改用方法为:每找到一个点双连通分量,就new一个HashSet去存储,然后将点数大于2的set存进list。询问时遍历所有点双连通分量,查询目标两点是否在其中。

- 公测:三次公测(中测 + 强测)均未出现bug
- 互测:三次互测均未被hack出bug
2. 互测hack
- hack策略:本单元由于架构较为统一,因此都是阅读代码,分析出错误后,构造特定的hack数据精准打击(HW10中此法收获颇丰);对于找到了错误但难以手动构造测试用例的(如超时,递归中有问题的点),则针对有问题方法对应的指令,自动化生成大量数据去对拍,从而hack
- hack成果:
- HW9:较为简单,大家都tql,未发现bug
- HW10:阅读代码后收获颇丰(有点好奇是怎么过强测的)
- 两人qgrs和qgvs使用双重遍历法,很容易构造超时的数据
- 一人的ar逻辑有问题,在id1 == id2且该人存在的情况下,没有按规格直接return,而是将自己加入自己的熟人圈,此后qv一下自己与自己便能hack
- 一人atg最后的EqualPersonIdException异常抛出条件有问题,id2是组号,但没有使用containsGroup(id2)而使用了contains(id2),导致在组id与人id不同时,重复atg不会报异常
- 一人isCircle使用bfs算法,却未对询问同一点的极端情况做处理,用
qci 1 1便能hack - 一人qgrs和qgvs使用缓存法,但是在对组里已存在两人加关系时未更新缓存量。
- HW11:qsl判断直接相连两点的处理方法有问题,使用bfs从出发点遍历,找到目标点2次即判断为true,但对点做标记时有缺漏,产生bug
3. 自动化测试
-
数据生成:
- 由于指令具有层次性,因此使用java语言编写自动化生成强测数据的程序。
- 数据生成的主要策略是:初始化图 + 大量询问。即通过ap, ag, atg, ar指令初始化图,然后构造大量的随机或指定询问指令。
- 程序中包含多种数据生成模式,随机询问模式或针对某一指令的大量询问模式,并用HashMap容器管理。
- 程序通过输入获取模式字符串,然后生成想要的数据。
- 将程序打包成jar包以供测试平台使用
-
自动化黑盒测试平台:
- 基于python构建自动化测试平台
- 通过API,在程序中使用命令行指令运行上述数据生成jar包,并通过stdin的输入获得想要的数据,通过输出重定向将数据导入到指定文件
- 将对拍的程序打包成jar包,同样通过API使用命令行运行程序,并输入重定向为上述生成的数据文件,输出重定向到指定的输出文件,并通过
time.clock()方法统计粗略的运行时间并打印 - 对上一步中的时间做判断,并记录超时数据点。对于未超时数据,通过
filecmp.cmp()方法进行对拍;并将有差异的结果通过第三方库difflib中的方法,导出到html文件,以较直观的形式呈现出来,便于分析比对。 - 测试效果如下(截取部分):

- 此外自动化测试平台还可用于互测
五、心得体会
本单元体验极佳,首次全满分无bug
对于JML的感受是,一种极其严格的形式化描述语言,严格到可能一个功能简单的方法,需要花费甚至长于代码本身的篇幅是进行规格描述。这种严格的规格设计虽然不方便,但带来的好处也是明显的,即为设计者、实现者、使用者提供了一份类似于合同的规约,能够更好的交接工作,发现错误并及时修改以及迭代开发,从而提高代码质量。此外,严格的语法使得自动化检查等工具链的产生与开发有了可能,使得未来或许能够通过程序检测来确认代码实现是否符合规格设计。
在阅读规格实现代码时,理解到:规格只是设计者的思路,而实现者需要充分理解规格的内涵所在,而不能仅仅着眼于其外在形式。即,实现函数时,不能完全按照规格的描述机械化地实现,而应在充分理解规格的基础上,在保证正确性的同时,需要兼顾可扩展性、效率、性能等因素,最终给出灵活的代码实现。这才是规格的意义所在,它只是用来描述功能、架构这一层次的语言,而底层的代码实现不能被规格锁束缚。
当然,灵活实现的前提是仔细阅读规格并保证正确性,尤其是细节,否则可能出现HW9中漏判isCircle(id, id)这种极端数据的bug
对于规格的书写,目前理解并不深刻。但可以感受到,程序的大致框架也就随之确定。比如本单元三次作业的迭代开发,虽然有各种具体实现,但架构都是基于Person -> Group -> Network的框架的。因此,一个好的规格设计,能够带来好的架构设计,可以保证代码的质量。当然,在实现时也不能被这个框架完全限制,可以在其基础上进行更加灵活的架构设计,比如将算法独立出来设计为单独的类,提供方法供外部调用。如此便可提高代码的可扩展性和复用性。