python的bs的简单实例爬取58同城手机信息
58同城我所爬的地址

import re
import urllib
from bs4 import BeautifulSoup
def gethtml(url):
page= urllib.urlopen(url)
html=page.read()
return html
html=gethtml("http://zjk.58.com/shouji/?PGTID=0d000000-0000-0ab0-fc5a-bd32d8a09b17&ClickID=1&qq-pf-to=pcqq.group")
soup=BeautifulSoup(html)
print(soup.prettify())一段小代码输出58的网址代码方便查看
翻阅BS文档,查找出来俩个方法在标题上试了试
title=soup.find_all("a",class_="t")
for tlt in title:
print tlt.get_text()
print "\n"索尼sw2便宜出150
三星s5手机盒
出售3个月的vivo x6s 64g 土豪金
在保国行iphone6splus玫瑰金16G
vivo y928
苹果6p
成功。。。
继续观察网址源代码
想把内容结合起来,一起输出
网上借鉴别人的方法,需要借助一个列表来循环
def get_xinxi(body):
finall=[]#接受所有需要爬下来的内容
for content in body:#在每一个记录里找到所要爬下来的内容
word=[]#定义一个列表,用来把需要爬下来的内容记录
a=content.find('a').get_text()
word.append(a)
word.append('\n')
f=content.find('span').get_text()
word.append(f)
word.append('\n')
b=content.find('span',class_="desc").get_text()
word.append(b)
word.append('\n')
c=content.find('span',class_="fl")
i=c.find_all('span')
for n in i :
word.append(n.get_text())
word.append('\n')
d=content.next_sibling.next_sibling.next_sibling
e=d.next_sibling.find('p',class_="name_add").get_text()
word.append(e)
word.append("\n\n\n")
finall.append(word)#将每次循环所得一个记录的所有内容获取
return finall千辛万苦,各种方法什么子节点 兄弟节点都用上,终于把所有信息都放到列表里了,可是问题也来了
当把列表信息写入文本时,一直报错
‘ascii’ codec can’t encode character
类型不合适,再次翻找
最后在这里找到了答案
#coding=utf-8
__author__ = 'kongmengfan123'
import urllib
import time
from bs4 import BeautifulSoup
def gethtml():
for i in range(1,13):#得到前12页
url = 'http://zjk.58.com/shouji/pn%d/'%i
page = urllib.urlopen(url)
html=page.read()
time.sleep(1)
soup=BeautifulSoup(html,'html.parser')
body=soup.find_all('td',class_='t')#观察发现每一个记录都在一个body内
finall=get_xinxi(body)
write_xinxi(finall)
def get_xinxi(body):
finall=[]#接受所有需要爬下来的内容
for content in body:#在每一个记录里找到所要爬下来的内容
word=[]#定义一个列表,用来把需要爬下来的内容记录
a=content.find('a').get_text()
word.append(a)
word.append('\n')
f=content.find('span').get_text()
word.append(f)
word.append('\n')
b=content.find('span',class_="desc").get_text()
word.append(b)
word.append('\n')
c=content.find('span',class_="fl")
i=c.find_all('span')
for n in i :
word.append(n.get_text())
word.append('\n')
d=content.next_sibling.next_sibling.next_sibling
e=d.next_sibling.find('p',class_="name_add").get_text()
word.append(e)
word.append("\n\n\n")
finall.append(word)#将每次循环所得一个记录的所有内容获取
return finall
def write_xinxi(finall):
for shouji in finall:#将所得内容写入文本中
for xinxi in shouji:
show.write(xinxi.encode('utf-8'))
show=open('58tongcheng.txt','w')
gethtml()
show.close()
最后爬下来前12页的
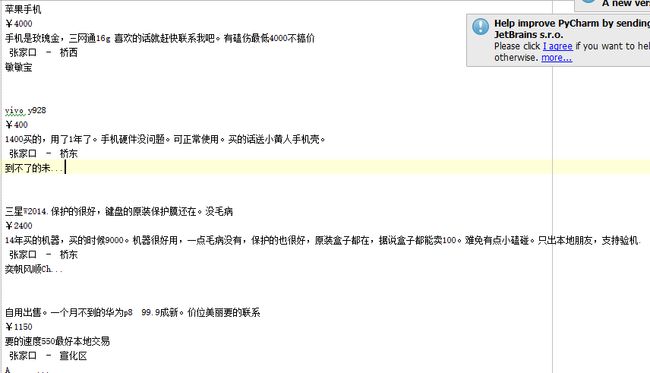
Ps(开始的时候可以先爬一页的东西对代码进行调整,当内容满意的时候,在把其写入页数的循环里)