优化sql方案
优化sql方案
为什么使用索引:
1、索引大大减少了存储引擎需要的扫描数据量
2、帮助我们进行排序避免使用的临时表
3、把随机IO变为顺序IO
索引是不是越多越好:
1、索引增加写入的成本
2、太多索引会增加查询优化器的选择时间
索引是在存储引擎层的作用:
B-tree索引的特点:
1、常见索引,默认的索引,叶子键遍历
2、以B+树的结构存储数据
3、能加快数据的查询速度
4、适合进行范围查找
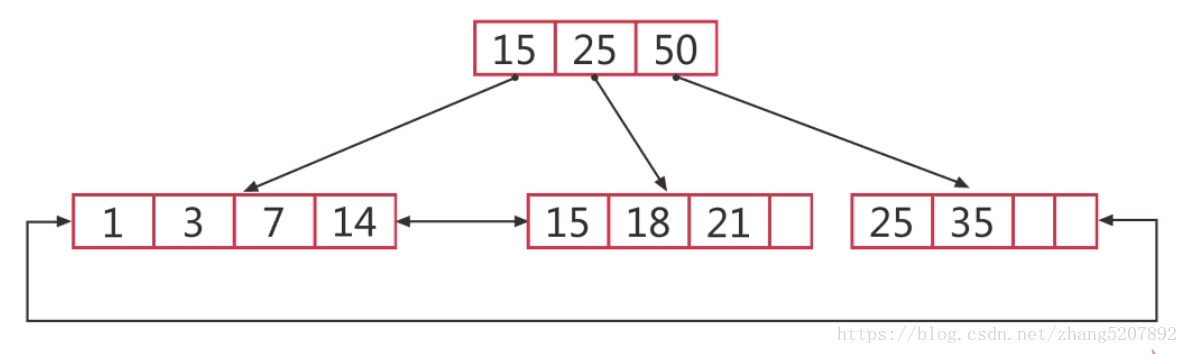
什么情况下可以使用B树索引:
1、全值匹配的查询
2、匹配最左前缀的查询–联合索引,日期和某个字段
3、匹配列前缀查询例如 order link “984%”
4、匹配范围值查询-order>’987897’ and order <’999978’
5、精确匹配左前列并范围匹配另外一列
5、只访问索引的查询
6、order by也可以使用B树索引
B树索引的限制:
1、如果不是按照索引的最左列开始查找,则无法使用索引
2、使用索引的时候不能跳过索引中的列
3、NOT in和 <>操作无法使用索引的
4、如果查询中有某个列的范围查询,则其右边所有列都无法使用索引
Hash索引的特点:
需要进行两次查询,先查HASH码,再找到相关的行数据,因为存储在内存中,所以并不影响
1、Hash索引是基于HASH表实现的,只有查询条件精确匹配HASH索引中的所有列时,才能使用到HASH索引(也就是只能用到等值查询,范围查询不能用到)
2、对于HASH索引中的所有列,存储引擎都会为每一行计算一个HASH码,HASH索引中的存储就是HASH码
HASH索引的限制:
1、HASH索引必须使用二次查找
2、HASH索引无法用于排序
3、HASH索引无法用于范围查找
4、HASH索引部分查询
5、不要使用到选择性很差的字段(例如男女性别),造成大量HASH重复,身份证重复比较少可以建立HASH索引
6、根据第5条明白存在HASH冲突
HASH在innodb是自适应的
HASH在innodb是自适应的,查看是否开启自适应
mysql> show variables like ‘innodb_adaptive_hash_index’;
索引优化策略:
1、索引列不能使用表达式或者函数
例如:select …. from product where to_days(a_day)-to_days(b_day)<=30
使用到了to_days函数,是不行的
改下为 select …. from product a_day<=data_add(current_date,interval 30 day )
2、前缀索引和索引列的选择性—字符串很长的情况下,会降低索引的效果,字符串前缀建立索引

sql:create INDEX index_name ON table(col_name(n));
索引的选择性是不重复的索引值和表的记录数的比值(唯一性约高,选择性也就越高)
3、联合索引
如何选择索引列的顺序
1、经常会被使用到的列优先放最左边,如果是选择性很差的列不要放最左列
2、选择性高的列优先
3、宽度小的列优先
覆盖索引:包含了所有的值的索引叫做覆盖索引,不当是where里的值,order包含的也算在内。
覆盖索引是联合索引的一个延伸与优化,查询的列都包含在索引中。
优点:
1、可以优化缓存,减少磁盘IO操作
2、可以减少随机IO,可变随机IO操作改变为顺序IO操作
3、可以避免对Innodb主键索引的二次查询
4、可以避免myisam表进行系统调用
不能使用覆盖索引:
1、有的存储引擎不支持覆盖索引
2、不支持HASH索引的使用
3、查询中使用了太多的列(*查询)
4、不能使用双%%的like查询
使用索引来优化查询:
1、使用索引扫描来优化排序,通过排序操作
按照索引顺序扫描数据:
1、索引列的顺序和order by子句的顺序完全一致
2、索引中所有列的方向(升序,降序)和order by 子句完全一致
3、order by 中的字段 全部在关联表中的第一张表中
利用索引优化锁:
1、索引可以减少锁定的行数
2、索引可以加速处理速度,同时也加快锁的释放
索引的维护与优化:
1、删除重复和冗余的索引:例如单独一个索引和联合索引一起的建立
2、某个列建立了主键索引和唯一索引和索引
检查索引重复的工具:
pt-duplicate-key-checker
查找未被使用过的索引:
sql语句:
SELECT
object_schema,
object_name,
index_name,
b.TABLE_ROWS
FROM
performance_schema.table_io_waits_summary_by_index_usage a
JOIN information_schema.tables b ON a.OBJECT_SCHEMA = b.TABLE_SCHEMA
AND a.OBJECT_NAME = b.TABLE_NAME
WHERE
index_name IS NOT NULL
AND count_star = 0
ORDER BY
object_schema,
object_name
然后删除从不使用的索引
更新索引统计信息及减少索引碎片:
执行sql命令:analyze table table_name 使用不当会造成锁表
如何获取有性能问题的SQL:
通过慢查询日志获取存在的性能的sql
什么是覆盖索引
https://blog.csdn.net/jh993627471/article/details/79421363
「Using where; Using index」区别是什么
using index 是覆盖索引,说明你的查询语句可以只通过查询索引里的信息就能得到结果。using where 则表示需要查询磁盘里存储的数据,速度会慢很多
得出结果:
Using index不读数据文件,只从索引文件获取数据
Using where过滤元组和是否读取数据文件或索引文件没有关系