DataX学习笔记
1.dataX是什么
(1) 定义:DataX是阿里巴巴内被广泛使用的异构数据源离线数据同步工具/平台,实现包括 MySQL、Oracle、SqlServer、Postgre、HDFS、Hive、ADS、HBase、OTS、ODPS 等各种异构数据源之间高效的数据同步功能。
(2) 技术支持:
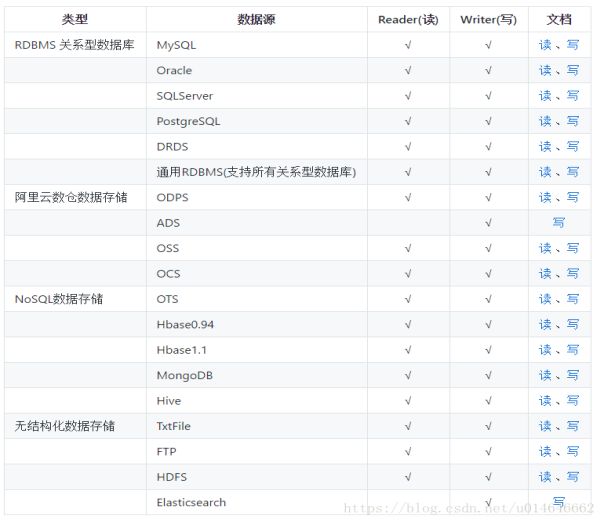
(3) 设计理念:为了解决异构数据源同步问题,DataX将复杂的网状的同步链路变成了星型数据链路,DataX作为中间传输载体负责连接各种数据源。当需要接入一个新的数据源的时候,只需要将此数据源对接到DataX,便能跟已有的数据源做到无缝数据同步。

(4) 核心架构:

·结构模式
Job:一道数据同步作业
Splitter:作业划分模块,将一个大任务分解成多个可以并发的小任务。
Task:数据同步作业切分后的小任务。
Reader:数据读入模块,负责运行切分后的小任务,将数据从源头装载入DataX。
Channel:这个是指定并发数量的。
Writer:数据写出模块,负责将数据从DataX导入至目的数据地
·详情描述
DataX完成单个数据同步的作业,称之为job。DataX接收到一个job后,将启动一个进程来完成整个作业同步过程。DataX Job模块是单个作业的中枢管理节点,承担了数据清理、子任务切分(将单一作业计算转化为多个子Task)、TaskGroup管理等功能。 DataXJob启动后,会根据不同的源端切分策略,将Job切分成多个小的Task(子任务),以便于并发执行。Task便是DataX作业的最小单元,每一个Task都会负责一部分数据的同步工作。切分多个Task之后,DataX Job会调用Scheduler模块,根据配置的并发数据量,将拆分成的Task重新组合,组装成TaskGroup(任务组)。每一个TaskGroup负责以一定的并发运行完毕分配好的所有Task,默认单个任务组的并发数量为5。每一个Task都由TaskGroup负责启动,Task启动后,会固定启动Reader—>Channel—>Writer的线程来完成任务。
2.datax为什么要用
数据导入时:针对离线数据,当数据量很大或表非常多时,建议使用DataX。
DataX本身作为数据同步框架,将不同数据源的同步。并且抽象为:从源头数据源读取数据的Reader插件,以及向目标端写入数据的Writer插件,理论上DataX框架可以支持任意数据源类型的数据同步工作。同时DataX插件体系作为一套生态系统, 每接入一套新数据源该新加入的数据源即可实现和现有的数据源互通(简而言之:就是把数据从一个数据源导入另一个数据源)。
可以增大DataX本身的并发,并提高运行DataX的任务机数量,来达到高并发,从而实现快速迁移。
3.datax怎么用
3.1 dataX配置文件
文件名:test.json


什么是job:一种作业配置文件(json格式)
整个配置文件是一个job的描述;
job下面有两个配置项,content和setting,其中content用来描述该任务的源和目的端的信息,setting用来描述任务本身的信息;
content又分为两部分,reader和writer,分别用来描述源端和目的端的信息;
本例中由于源和目的都是mysql,所以类型为mysqlreader和mysqlwriter。同时预迁移表的jdbcUrl,table以及列名和分区信息都要一一填写清楚。(不同类型对应reader和writer里面的字段不一样)
setting中的speed项表示同时起20个并发去跑该任务。
经试验:如果指定reader和writer都指定了具体的字段,那么字段名称,字段类型(varchar转数字类型会提示脏数据),字段顺序(不一致数据会错乱),请确认保持一致。
3.2 运行Datax任务
运行Datax任务即(json文件)很简单,只要执行python脚本即可。
python /home/admin/datax3/bin/datax.py test.json
注意:运行datax的前置条件,需要安装python,并且需要配置python的环境变量。
<1> python下载
地址:https://pan.baidu.com/s/1CTN4ghBN4bRLjn3TqIwIKA 提取码:9527
<2> datax下载
地址:https://pan.baidu.com/s/15t2DDHgg2JXkJJPNFC46KA 提取码:9527
<3> python配置环境变量:
https://jingyan.baidu.com/article/c33e3f483ab7d4ea14cbb548.html
<4> 运行文件出现中文乱码:控制台出现乱码:直接输入CHCP 65001回车
4.datax的特点
·支持sql-server / oracle / mysql 等jdbc支持的数据库之间互导
·支持数据库与solr(Solr是一个独立的企业级搜索应用服务器,它对外提供类似于Web-service的API接口)搜索引擎之间互导
·采用http协议传送数据,在网络环境复杂和连接不稳定的情况下能正常工作,也可以扩展成集群、转发、负载均衡等
·网络不稳定、数据库连接不稳定的情况下,有重连、重试机制
·复杂的数据处理和异构,自定义Query-SQL和Insert/Delete/Update-SQL
·分布式事务、数据一致性保护。导入错误的情况下,两边数据都不会发生更改
·在工作异常的情况下,可以发送短信或邮件通知
·可以通过http网页形式随时查看工作状态和cpu 内存使用情况,方便监控
·在异构的数据库/文件系统之间高速交换数据
·采用Framework + plugin架构构建,Framework处理了缓冲,流控,并发,上下文加载等高速数据交换的大部分技术问题,提供了简单的接口与插件交互,插件仅需实现对数据处理系统的访问
·运行模式:stand-alone(独立运行)
·数据传输过程在单进程内完成,全内存操作,不读写磁盘,也没有IPC(inter-Process Communication,进程间通信)
·开放式的框架,开发者可以在极短的时间开发一个新插件以快速支持新的数据库/文件系统。
5.DataX配置定时任务
参考:https://blog.csdn.net/weixin_38175358/article/details/86496741
6.DataX调优
参考: https://www.cnblogs.com/hit-zb/p/10940849.html
7.部分插件使用相关链接
Datax的github地址:https://github.com/alibaba/DataX
MysqlReader插件文档:https://github.com/alibaba/DataX/blob/master/mysqlreader/doc/mysqlreader.md
MysqlWriter插件文档:https://github.com/alibaba/DataX/blob/master/mysqlwriter/doc/mysqlwriter.md
OracleReader插件文档:https://github.com/alibaba/DataX/blob/master/oraclereader/doc/oraclereader.md
OracleWriter插件文档:https://github.com/alibaba/DataX/blob/master/oraclewriter/doc/oraclewriter.md
其他参考博客:
- Datax介绍:https://blog.csdn.net/a870542373/article/details/86474585
- Datax介绍:https://blog.csdn.net/burpee/article/details/53734393
- Datax优点总结:https://zhuanlan.zhihu.com/p/81817787
见识浅薄,不断更新中~~~