使用HBase API删除数据的时候需要注意的地方有很多,需要分成几种情况进行分别的讨论,进行删除操作之前,首先需要构建删除对象,即org.apache.hadoop.hbase.client包下的Delete,然后根据实际情况进行具体的操作,下面一一介绍:
1、只传rowKey
rowKey这个参数可以在构建Delete对象的时候,作为构造方法的参数传进去。这种情况相当于HBase Shell操作下的deleteall命令,会将指定rowKey下的所有列族以及所有列的所有版本数据都删除,最终做的标记类型也是DeleteFamily。示例如下,我们客户端,只传rowKey值1004,调用API执行删除操作。
删除之前:
 删除之后:
删除之后:

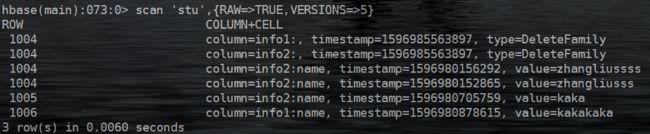
会发现,rowKey=1004的所有列族的数据都被删除了,其中删除所做的标记类型为DeleteFamily
API的代码如下:
public static void deleteData(String tableName,String rowKey,String cf,String cn) throws IOException { //1.获取表对象 Table table = connection.getTable(TableName.valueOf(tableName)); //2.构建删除对象 Delete delete = new Delete(Bytes.toBytes(rowKey)); //3.执行删除操作 table.delete(delete); //4.关闭连接 table.close(); }
2、传入rowKey和Column Family
传入rowKey和列族,则会将指定的rowKey和列族下的所有版本的数据都给删除掉,案例实操:
删除之前,rowKey=1005的对应的数据有两个列族info1和info2,同时info1下含有两个列sex和addr,sex列下含有两个版本的数据:

调用API进行删除,删除操作执行之后:


可以判断,传入rowKey和列族之后,会删除指定的rowKey和列族下对应的所有列,以及列的所有版本的数据,同时删除标记是DeleteFamily。对应的代码如下:
public static void deleteData(String tableName,String rowKey,String cf,String cn) throws IOException { //1.获取表对象 Table table = connection.getTable(TableName.valueOf(tableName)); //2.构建删除对象 Delete delete = new Delete(Bytes.toBytes(rowKey)); //2.2删除指定的列族 delete.addFamily(Bytes.toBytes(cf)); //3.执行删除操作 table.delete(delete); //4.关闭连接 table.close(); }
3、传入rowKey、列族以及列名
在此种情况下,向Delete对象添加列名的方法有两种:addColumn()和addColumns()。
(1)addColumns()
/** * Delete all versions of the specified column. * @param family family name * @param qualifier column qualifier * @return this for invocation chaining */ public Delete addColumns(final byte [] family, final byte [] qualifier) { addColumns(family, qualifier, this.ts); return this; }
观察源码的注释可以知道,该方法的作用是删除指定列的所有版本的数据,同时它还有一个重载的方法,多了一个参数,这个参数是时间戳参数,作用是删除所有小于等于指定列的指定时间戳的所有版本的数据
/** * Delete all versions of the specified column with a timestamp less than * or equal to the specified timestamp. * @param family family name * @param qualifier column qualifier * @param timestamp maximum version timestamp * @return this for invocation chaining */ public Delete addColumns(final byte [] family, final byte [] qualifier, final long timestamp) { if (timestamp < 0) { throw new IllegalArgumentException("Timestamp cannot be negative. ts=" + timestamp); } List| list = familyMap.get(family); if (list == null) { list = new ArrayList | (); } list.add(new KeyValue(this.row, family, qualifier, timestamp, KeyValue.Type.DeleteColumn)); familyMap.put(family, list); return this; } |
实操一下:
删除之前,对于rowKey=1010这一行数据,其info2列族下,phone对应的列,含有两个版本的数据:
![]()
执行删除操作:

![]()
可以看到,所有版本的数据都被删除了。这是没有指定时间戳的情况,下面来看一下指定时间戳的情况,我们重新向1010这一行put两个不同版本的数据:
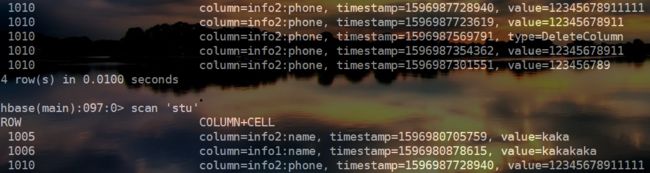
其中,时间戳最大的那个版本的数据的时间戳的值为1596987728940,较小的值为1596987723619。我们插入列的时候,传入一个介于以上两个版本数据的时间戳值之间的时间戳1596987728940。然后执行删除操作,结果如下:

发现时间戳较大的那个数据还存在,但是小于传入的时间戳值的那个数据被删除了。
![]()
该方法删除数据的时候,标记的删除类型也是DeleteFamily。代码如下:
public static void deleteData(String tableName,String rowKey,String cf,String cn) throws IOException { //1.获取表对象 Table table = connection.getTable(TableName.valueOf(tableName)); //2.构建删除对象 Delete delete = new Delete(Bytes.toBytes(rowKey)); delete.addColumns(Bytes.toBytes(cf),Bytes.toBytes(cn),1596987728939l); //3.执行删除操作 table.delete(delete); //4.关闭连接 table.close(); }
(2)addColumn()
该方法添加指定的列,然后执行删除操作,是存在较大的争议的,它的作用是删除指定列的最新版本的那一条数据而非全部,同时也可以传入要删除的指定的时间戳。先来看一下它的源码:
/** * Delete the latest version of the specified column. * This is an expensive call in that on the server-side, it first does a * get to find the latest versions timestamp. Then it adds a delete using * the fetched cells timestamp. * @param family family name * @param qualifier column qualifier * @return this for invocation chaining */ public Delete addColumn(final byte [] family, final byte [] qualifier) { this.deleteColumn(family, qualifier, this.ts); return this; }
带有时间戳参数的源码:
/** * Delete the specified version of the specified column. * @param family family name * @param qualifier column qualifier * @param timestamp version timestamp * @return this for invocation chaining */ public Delete addColumn(byte [] family, byte [] qualifier, long timestamp) { if (timestamp < 0) { throw new IllegalArgumentException("Timestamp cannot be negative. ts=" + timestamp); } List| list = familyMap.get(family); if(list == null) { list = new ArrayList | (); } KeyValue kv = new KeyValue(this.row, family, qualifier, timestamp, KeyValue.Type.Delete); list.add(kv); familyMap.put(family, list); return this; } |
先来看一下注释说的,第一个方法的功能就是删除指定列的最新版本的数据,其中还说这个方法在服务器端是一个比较昂贵的调用,它会先执行get方法获取最新版本的时间戳,然后将delete标记添加到这个最新的时间戳上。这就相当于标记了指定列最新版本的数据是被删除的了。第二个方法会传入一个时间戳参数,然后作用是删除指定列的指定版本的数据。那我们来案例实操一下:
我们先put两条数据到表中,其中rowKey=1011,列族为info1,列名为name,列的版本数为1:

![]()
执行完成之后,结果如下:

![]()
会发现,时间戳最大的那个数据被删除了,但是执行scan操作,原先时间戳较小的那个数据显示出来了,其中删除标记是Delete,删除标记对应的时间戳正是原先最大的那个时间戳。这是在两个put的数据都在内存中的时候所出现的情况,那我们再进一步进行一种实验,调用API执行删除操作放在put数据并进行刷写到磁盘之后,我们再次put两条数据,然后执行flush操作:
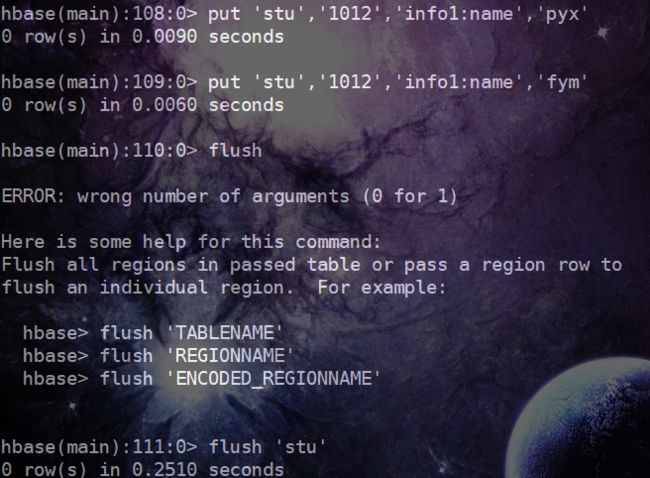
调用API执行删除操作,然后使用scan命令查看数据:
删除操作的api代码:
public static void deleteData(String tableName,String rowKey,String cf,String cn) throws IOException { //1.获取表对象 Table table = connection.getTable(TableName.valueOf(tableName)); //2.构建删除对象 Delete delete = new Delete(Bytes.toBytes(rowKey)); //2.1设置删除的列 delete.addColumn(Bytes.toBytes(cf),Bytes.toBytes(cn)); //3.执行删除操作 table.delete(delete); //4.关闭连接 table.close(); }
查询结果:

发现1012对应的数据没了,也就是说在设计表的时候,某个列的最大版本数,被设置为了1,然后当我们多次对这个列put数据的时候,如果这些数据都还在内存中,那我们使用addColumn方法指定删除的列族和列名的时候,会删除时间戳最大的那一条数据,然后第二大的时间戳对应的那一条数据对显示出来。如果在put多条数据和调用API删除数据的过程之间发生了刷写数据到磁盘的过程(自动或者手动),那么就不会产生上面的现象。
当然,以上现象都是针对设计表的时候,最大版本数为1的情况,如果设计表的时候,设置了列的最大版本数大于1,那么put多条数据之后,然后刷写到磁盘,使用addColumn方法指定列和列族删除数据,最后进行scan扫描的时候还是会有这个列的其他版本的数据显示出来。
第二种重载的方法,传入指定的时间戳,这个方法也只是将指定的时间戳标记为delete,如果指定列没有对应时间戳的数据,则不会删除任何数据,除非插入的数据的时间戳和指定的时间戳相同,否则是不会删除数据。
对于addColumn方法应该谨慎使用为好,因为会造成数据不一致的情况发生,比如我们对某个列put了多条数据,在刷写之前,调用API进行了删除操作,然后执行了刷写,这是磁盘中保存的这一列的数据是时间戳较小的那个版本的数据。如果,put了多条数据,刷写操作在删除操作之前,那么最终磁盘中该列是没有数据的(针对列的最大版本数为1的情况),这就造成了数据不一致的情况。
一定要注意,这种方法,标记的时间戳不是专门为这次删除操作生成的时间戳,而是先去获取指定列的所有版本中最新版本的时间戳,然后将这个时间戳标记为delete,这是本质。