从一件数据清洗的小事说起
写
在前面
“转载自公众号:大猫的R语言课堂
村长,数据科学、指弹吉他及录音工程爱好者,浙大金融学博士在读,在data.table包和MongoDB的使用上有较多经验。
问
题:从一段json清晰代码说起
笔者某一日在R语言中文社区某一群里面发现了水友提出的一个问题,处理一个比较奇葩的数据清洗问题,先来看数据结构:

这是一个类json格式嵌套的数据,其中存在两个变量,第一个变量是cusnum作为序号,第二个是一个类json的嵌套变量,里面以类jsno格式嵌套了很多变量。
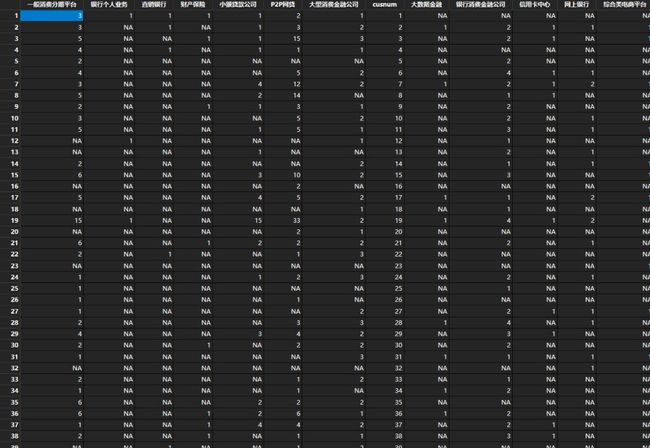
需要将这个数据集转换成如下格式:
进
展
“如果你以为这一期我们会非常正经的讲一个技术问题,那么你错了!!!233333333!!!
”在这个时候,群里的大佬开始了扶贫工作,为萌新们开启了超人模式,直接上传dplyr代码到男性交友平台(github),代码如下:
library(jsonlite)
library(dplyr)
library(stringr)
library(purrr)
library(forcats)
library(tidyr)
library(readr)
json %>%
mutate(var = str_replace_all(var, '""', '\"')) %>%
mutate(var = map(.x = var, .f = jsonlite::fromJSON)) %>%
unnest() %>%
as_tibble() %>%
print %>%
write_excel_csv('tmp.csv')
笔者那天下午也觉得没处理过这种类型的数据,就琢磨了一下,于是也用data.table写了一段代码:
library(data.table)
library(jsonlite)
library(stringr)
flat.json <- json[, var := str_replace_all(var, '""', '\"')
][, {
I <- list()
for (i in 1:.N) {
I[[i]] <- c(fromJSON(var[i]), cusnum = cusnum[i])
}
rbindlist(I, fill = T)
}] %>% fwrite("flat.json.csv")
还就此测试了一下二者的性能:图一为大佬代码的运行时间,图二为笔者代码运行时间


笔者的代码还是要比大佬写的快了不少。
而接下来发生在群里的事情是这样的:
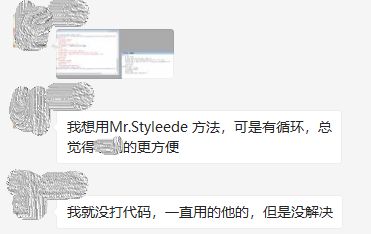

怎么说呢,大姐,我知道你是大佬的邪教粉,但是你真的对力量一无所知。“For循环很慢”只是一种很不科学的说法,就好比有人说CD的音质硬是要比Hi-res音轨要好,Win7的兼容性比Win10好。很多人只知道这种说法,但并不知道背后的原因。实际上,for循环“只会在不恰当使用时”降低性能。
然而大佬毕竟是大佬,用科学的态度做了实验并给出了结论:
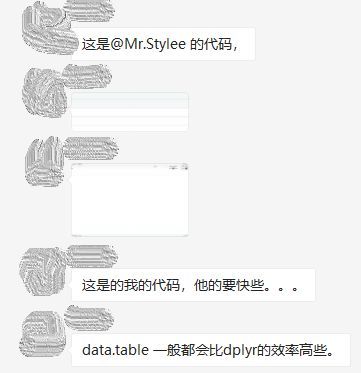
其实这一期这么扯淡的讲这么多事情,只是为了说明一点,data.table真的有很好的性能,尤其在处理海量数据方面(在分组特别多的时候,相比dplyr和pandas有2x~10x的提升,来自官方文档)。编程的效率最重要的来自于框架,框架如果一开始就不那么有效率,再怎么改进都是有限的。
那么data.table的框架优秀在哪儿呢?
data.table之所以比dplyr要快,在于两者设计的哲学不同。dplyr的哲学和Linux类似:每个组件就做好一件事,当把所有组件拼在一起之后就是一个全功能的包了。这个理论利弊共存。从好处来说,因为每个组件只做一件事(比如group、mutate),所以在开发的时候耦合度低,容易开发维护,而且对于使用者来说也“更容易学习”。然而,他的弊端也是非常明显的,首先是效率不高。毕竟,局部最优不等于全局最优(关于背后原理此处省略一万字)。其次,由于dplyr把原本是一个整体的数据处理需求拆分成了很多“步”,导致代码会比较冗长。相较之下,data.table则通过把数据处理中最常见的“选取行”、“修改列”、“分组”三大操作通过dt[i,j,by]的语法统一了一起来。
关于如何学习data.table包,大家可以查看本公众号前几期的文章。R语言的data.table包是一个被大多数人远远低估的存在,在这里想强烈推荐给大家!!如果大家对于上面的代码有兴趣的话,也欢迎后台提问~

往期精彩:
【推荐】在R中无缝集成Github云端代码托管
还在用tm?你OUT啦!

公众号后台回复关键字即可学习
回复 爬虫 爬虫三大案例实战
回复 Python 1小时破冰入门
回复 数据挖掘 R语言入门及数据挖掘
回复 人工智能 三个月入门人工智能
回复 数据分析师 数据分析师成长之路
回复 机器学习 机器学习的商业应用
回复 数据科学 数据科学实战
回复 常用算法 常用数据挖掘算法