Linux之Shell 操作实用技巧
目录
1.Shell 操作日期时间
1.1. 显示系统当前日期时间
1.2.设置系统日期时间
1.3.日期计算
1.4.自定义日期格式
1.5. 有用小技巧
2.高级文本处理命令
2.1.wc
2.2.sort
2.3.uniq
2.4.cut
2.5.grep(文本生成器)
2.6.sed(流编辑器)
2.7.awk(报表生成器)
2.8.find
3.Shell 操作字符串
3.1.字符串截取
3.2.字符串替换
3.3.获取字符串长度
4. Shell脚本自动安装MySQL
1.Shell 操作日期时间
linux 系统为我们提供了一个命令 date,专门用来显示或者设置系统日期时间的。
语法格式:date [option]... [+format] 或者 date [-u | -utc | -universal] [MMDDhhmm[[CC]YY][.ss]]
常用的可选项有:
--help:显示辅助信息
--version:显示date命令版本信息
-u:显示目前的格林威治时间
-d:做日期时间相关的运算
--date='-dateStr':做日期时间的相关运算
1.1. 显示系统当前日期时间
[root@hadoop ~]# date
[root@hadoop ~]# date '+%Y-%m-%d %H:%M:%S'
1.2.设置系统日期时间
[root@hadoop ~]# date -s "2017-01-01 01:01"
[root@hadoop ~]# date --set="2017-01-01 01:01"
1.3.日期计算
有时候,我们操作日期时间,经常会要获取前几天或后几天的时间,那么date命令给我们提供了实现这个功能的可选项 '-d' 和 '--date' ,请看下面的例子:
先看 '-d':
##获取下一天的时间
##获取上一天的时间
##获取下一月的时间
##获取上一月的时间
##获取下一年的时间
##获取上一年的时间
##获取下一周、下周一、下周四的日期时间
**********************************
##获取下一天的时间
[root@hdp1 ~]# date -d next-day '+%Y-%m-%d %H:%M:%S'
2017-05-07 02:11:13
[root@hdp1 ~]# date -d 'next day' '+%Y-%m-%d %H:%M:%S'
2017-05-07 02:19:24
[root@hdp1 ~]# date '+%Y-%m-%d %H:%M:%S' -d tomorrow
2017-05-07 02:20:28
##获取上一天的时间
[root@hdp1 ~]# date -d last-day '+%Y-%m-%d %H:%M:%S'
2017-05-05 02:22:34
[root@hdp1 ~]# date '+%Y-%m-%d %H:%M:%S' -d yesterday
2017-05-05 02:22:59
##获取下一月的时间
[root@hadoop ~]# date -d next-month '+%Y-%m-%d %H:%M:%S'
##获取上一月的时间
[root@hadoop ~]# date -d last-month '+%Y-%m-%d %H:%M:%S'
##获取下一年的时间
[root@hadoop ~]# date -d next-year '+%Y-%m-%d %H:%M:%S'
##获取上一年的时间
[root@hadoop ~]# date -d last-year '+%Y-%m-%d %H:%M:%S'
##获取下一周、下周一、下周四的日期时间
[root@hadoop ~]# date -d next-week '+%Y-%m-%d %H:%M:%S'
[root@hadoop ~]# date -d next-monday '+%Y-%m-%d %H:%M:%S'
[root@hadoop ~]# date -d next-thursday '+%Y-%m-%d %H:%M:%S'
那么类似的,其实,last-year,last-month,last-day,last-week,last-hour,last-minute,last-second都有对应的实现。相反的,last对应next,自己可以根据实际情况灵活组织
接下来,我们来看 '--date' ,它帮我实现任意时间前后的计算,来看具体的例子:
##获取一天以后的日期时间
[root@hdp1 ~]# date '+%Y-%m-%d %H:%M:%S' --date='1 day'
2017-05-07 02:27:57
[root@hdp1 ~]# date '+%Y-%m-%d %H:%M:%S' --date='-1 day ago'
2017-05-07 02:28:06
##获取一天以前的日期时间
[root@hdp1 ~]# date '+%Y-%m-%d %H:%M:%S' --date='-1 day'
2017-05-05 02:28:38
[root@hdp1 ~]# date '+%Y-%m-%d %H:%M:%S' --date='1 day ago'
2017-05-05 02:28:50
上面的例子显示出来了使用的格式,使用精髓在于改变前面的字符串显示格式,改变数据,改变要操作的日期对应字段,除了天也有对应的其他实现:year,month,week,day,hour,minute,second,monday(星期,七天都可)
1.4.自定义日期格式
date 能用来显示或设定系统的日期和时间,在显示方面,使用者能设定欲显示的格式,格式设定为一个加号后接数个标记,其中可用的标记列表如下:
使用范例如下:
[root@hdp1 ~]# date '+%Y-%m-%d %H:%M:%S'
2018-10-31 23:49:00
日期方面:
%a : 星期几 (Sun..Sat)
%A : 星期几 (Sunday..Saturday)
%b : 月份 (Jan..Dec)
%B : 月份 (January..December)
%c : 直接显示日期和时间
%d : 日 (01..31)
%D : 直接显示日期 (mm/dd/yy)
%h : 同 %b
%j : 一年中的第几天 (001..366)
%m : 月份 (01..12)
%U : 一年中的第几周 (00..53) (以 Sunday 为一周的第一天的情形)
%w : 一周中的第几天 (0..6)
%W : 一年中的第几周 (00..53) (以 Monday 为一周的第一天的情形)
%x : 直接显示日期 (mm/dd/yyyy)
%y : 年份的最后两位数字 (00.99)
%Y : 完整年份 (0000..9999)
时间方面:
%%: 打印出%
%n : 下一行
%t : 跳格
%H : 小时(00..23)
%k : 小时(0..23)
%l : 小时(1..12)
%M : 分钟(00..59)
%p : 显示本地AM或PM
%P : 显示本地am或pm
%r : 直接显示时间(12 小时制,格式为 hh:mm:ss [AP]M)
%s : 从 1970 年 1 月 1 日 00:00:00 UTC 到目前为止的秒数
%S : 秒(00..61)
%T : 直接显示时间(24小时制)
%X : 相当于%H:%M:%S %p
%Z : 显示时区
若是不以加号作为开头,则表示要设定时间,而时间格式为 MMDDhhmm[[CC]YY][.ss]
MM 为月份
DD 为日
hh 为小时
mm 为分钟
CC 为年份前两位数字
YY 为年份后两为数字
ss 为秒数
例子:
[root@hdp1 ~]# date "050602032017.55"
Sat May 6 02:03:55 CST 2017
[root@hdp1 ~]# date '+%Y-%m-%d %H:%M:%S'
2018-10-31 23:49:00
1.5. 有用小技巧
##获取相对某个日期前后的日期
##把时间中无用的0去掉,比如01:02:25 变成 1:2:25
##显示文件最后被更改的时间
##求两个字符串日期之间的相隔的天数
##shell 中加减指定时间单位
***************************************************************
##获取相对某个日期前后的日期
[root@hdp1 ~]# date '+%Y-%m-%d %H:%M:%S' -d '2018-11-1 -2 week'
2018-10-18 00:00:00
##把时间中无用的0去掉,比如01:02:25 变成 1:2:25
[root@hdp1 ~]# date '+%Y-%m-%d %-H:%-M:%-S' -d '2018-11-1 01:02:03 -1 day'
2018-11-02 10:2:3
##显示文件最后被更改的时间
[root@hdp1 ~]# date '+%Y-%m-%d %-H:%-M:%-S' -r ./a.sh
2018-10-31 23:0:53
##求两个字符串日期之间的相隔的天数
[root@hdp1 ~]# echo "($(date +%s)-$(date +%s -d '1994-02-06'))/60/60/24" | bc
9034
##shell 中加减指定时间单位
[root@hdp1 ~]# A=$(date '+%Y-%m-%d')
[root@hdp1 ~]# B=$(date '+%Y-%m-%d' -d 'A +48 hours')
[root@hdp1 ~]# echo $B
2018-11-04
[root@hdp1 ~]# B=`date +%Y-%m-%d -d "A +48 hours"`
[root@hdp1 ~]# echo $B
2018-11-04
[root@hdp1 ~]# B=`date +%Y-%m-%d -d "$A +48 hours"`
[root@hdp1 ~]# echo $B
2018-11-03
2.高级文本处理命令
2.1.wc
功能:统计文件行数、字节、字符数
常用选项:
-l:统计多少行
-w:统计字数
-c:统计文件字节数,一个英文字母1字节,一个汉字占2-4字节(根据编码)
-m:统计文件字符数,一个英文字母1个字符,一个汉字占1字节
-L:统计最长行的长度,也可以统计字符串长度
--help:显示帮助信息
--version:显示版本信息
一个汉字到底占几个字节?
占2个字节:〇
占3个字节:基本等同于GBK,含21000多个汉字
占4个字节:中日韩超大字符集里面的汉字,有5万多个
一个utf8数字占1个字节
一个utf8英文字母占1个字节
示例:
##统计文件信息
##统计字符串长度
##统计文件行数
##统计文件字数
****************************************************
##统计文件信息
[root@hdp1 ~]# wc wc.txt
9 9 65 wc.txt
分别是:行数、单词数、字节数、文件名
##统计字符串长度
[root@hdp1 ~]# echo "dafasdfa" | wc -L
8
##统计文件行数
[root@hdp1 ~]# wc -l wc.txt
9 wc.txt
##统计文件字数
[root@hdp1 ~]# wc -w wc.txt
9 wc.txt
2.2.sort
功能:排序文本,默认对整列有效
常用可选项:
-f:忽略字母大小写,就是将小写字母视为大写字母排序
-M:根据月份比较,比如JAN、DEC
-h:根据易读的单位大小比较,比如2K、1G
-g:按照常规数值排序
-n:按照字符串数值比较
-r:倒序排序
-k:pos1,pos2 根据关键字排序,在从第位置1开始,位置2结束
-t:指定分割符
-u:去重重复行
-o:将结果写入文件
准备数据:
aaa:10:1.1
ccc:20:3.3
bbb:40:4.4
eee:40:5.5
ddd:30:3.3
bbb:40:4.4
fff:30:2.2
示例:
[linux@linux ~]$ cat sort.txt ## 准备排序文件,查看该内容
aaa:10:1.1
ccc:20:3.3
bbb:40:4.4
eee:40:5.5
ddd:30:3.3
bbb:40:4.4
fff:30:2.2
[linux@linux ~]$ sort sort.txt ## 直接排序,把整行当做一列字符串,字典顺序
aaa:10:1.1
bbb:40:4.4
bbb:40:4.4
ccc:20:3.3
ddd:30:3.3
eee:40:5.5
fff:30:2.2
[linux@linux ~]$ sort -nk 2 -t : sort.txt ## 以:作为分隔符,取第二个字段按照数值进行排序
aaa:10:1.1
ccc:20:3.3
fff:30:2.2
ddd:30:3.3
bbb:40:4.4
bbb:40:4.4
eee:40:5.5
[linux@linux ~]$ sort -nk 2 -u -t : sort.txt ## 和上一个不一样的是-u为了去重,根据排序列去重的
aaa:10:1.1
ccc:20:3.3
ddd:30:3.3
bbb:40:4.4
多列排序:以:分隔,按第二列数值排倒序,第三列正序
[linux@linux ~]$ sort -n -t: -k2,2r -k3 sort.txt ????
bbb:40:4.4
bbb:40:4.4
eee:40:5.5
fff:30:2.2
ddd:30:3.3
ccc:20:3.3
aaa:10:1.1
2.3.uniq
取出重复行,只会统计相邻。
常用选项:
-c:打印出现次数
-d:只打印重复行
-u:只打印不重复行
-D:只打印重复行,并且把所有重复行打印出来
-f N:比较时跳过前N列
-i:忽略大小写
-s N:比较式跳过前N个字符
-w N:对每行第N个字符以后内容不做比较
准备数据:
abc
xyz
cde
cde
xyz
abd
示例1:
[linux@linux ~]$ uniq uniq.txt ## 直接去重,只能在相邻行去重
abc
xyz
cde
xyz
abd
[linux@linux ~]$ sort uniq.txt | uniq ## 先给文件排序,然后去重
abc
abd
cde
xyz
[linux@linux ~]$ sort uniq.txt | uniq -c ## 打印每行重复次数
1 abc
1 abd
2 cde
2 xyz
[linux@linux ~]$ sort uniq.txt | uniq -u -c ## 打印不重复行,并给出次数
1 abc
1 abd
[linux@linux ~]$ sort uniq.txt | uniq -d -c ## 打印重复行,并给出次数
2 cde
2 xyz
[linux@linux ~]$ sort uniq.txt | uniq -w 2 ## 以开头前两个字符为判断标准去重
abc
cde
xyz
示例2:
先准备两个文件:a.txt 和 b.txt
文件内容分别为:
[root@hdp1 ~]# cat a.txt
a
b
c
d
[root@hdp1 ~]# cat b.txt
b
c
d
e
f
需求:
##求两个文件的交集:
[root@hdp1 ~]# cat a.txt b.txt | sort | uniq -d -c
##求两个文件的并集:
[root@hdp1 ~]# cat a.txt b.txt | sort | uniq
##求a.txt和b.txt的差集
[root@hdp1 ~]# cat a.txt b.txt b.txt | sort | uniq -u
##求b.txt和a.txt的差集
[root@hdp1 ~]# cat b.txt a.txt a.txt | sort | uniq -u
2.4.cut
cut命令可以从一个文本文件或文本流中提取文本列。
cut语法:
cut -d'分隔字符' -f fields ##用于有特定分分隔字符
cut -c 字符区间 ##用于排列整齐的信息
选项与参数:
-d:后面接分隔符,与-f一起使用
-f:依据-d的分隔符将一段信息分割成为字段,用-f取出第几段的意思
-c:按照字符截取
-b:按照字节截取
例子1:
首先看PATH变量:
[root@localhost ~]# echo $PATH
/usr/local/sbin:/usr/local/bin:/sbin:/bin:/usr/sbin:/usr/bin:/root/bin
##将PATH变量取出,找出第五个路径
[root@localhost ~]# echo $PATH | cut -d ':' -f 5
/usr/sbin
##将PATH变量取出,找出第三和第五个路径,以下三种方式都OK
[root@localhost ~]# echo $PATH | cut -d ':' -f 3,5
[root@localhost ~]# echo $PATH | cut -d : -f 3,5
[root@localhost ~]# echo $PATH | cut -d: -f3,5
/sbin:/usr/sbin
##将PATH变量取出,找出第三到最后一个路径
[root@localhost ~]# echo $PATH | cut -d ':' -f 3-
/sbin:/bin:/usr/sbin:/usr/bin:/root/bin
##将PATH变量取出,找出第一到第三,还有第五个路径
[root@localhost ~]# echo $PATH | cut -d ':' -f 1-3,5
/usr/local/sbin:/usr/local/bin:/sbin:/usr/sbin
例子2:
##先准备已空格分开的这么段数据:
黄渤 huangbo 18 jiangxi
徐峥 xuzheng 22 hunan
王宝强 wangbaoqiang 44 liujiayao
##获取中间的年龄:
[root@localhost ~]# cut -f 3 -d ' ' cut.txt
18
22
44
##获取第二个字符到第五个字符之间的字符:
[root@localhost ~]# cut -c 2-5 cut.txt
渤 hu
峥 xu
宝强 w
##获取第四个字节到第六个字节中的字符:
[root@hadoop ~]# cut -b 4-6 cut.txt
渤
峥
宝
2.5.grep(文本生成器)
grep是一种强大的文本搜索工具,它能使用正则表达式搜索文本,并把匹配的行统计出来。
命令:grep [选项] [-color=auto] "搜索字符串" filename
常用选项:
-c:统计符合条件的字符串出现的总行数
-E:支持扩展正则表达式
-i:忽略大小写
-n:在显示匹配到的字符串前面加上行号
-v:显示没有“搜索字符串”内容的那一行
-l:列出文件内容中有搜索字符串的文件名称
-o:只输出文件中匹配到的部分
-color=auto:将匹配到的字符串高亮起来
基本使用:
##查询包含hadoop的行
[root@localhost ~]# grep hadoop /etc/passwd
hadoop:x:500:504:hadoop01:/home/hadoop:/bin/bash
## 寻找当前路径下所有txt当中内容那些是带了huangbo字符串的
[root@localhost ~]# grep huangbo ./*.txt
./mazhonghua.txt:my name is huangbo is is huangbo
./sutdent.txt:huangbo 18 jiangxi
高级使用:
准备数据:
[root@hdp1 ~]# cat grep.txt
huangbo is shuaige
huangxiaoming is shuaige
liuyifei is meinv
hello world hello tom hello kitty
#how old are you
#one two three four five six seven eight nine ten
##统计出现某个字符串的行的总行数
[root@hdp1 ~]# grep -c 'hello' grep.txt
1
[root@hdp1 ~]# grep -c 'is' grep.txt
3
[root@hdp1 ~]# grep -c hello grep.txt
1
[root@hdp1 ~]# grep -c is grep.txt
3
##查询不包含is的行
[root@hdp1 ~]# grep -v 'is' grep.txt
hello world hello tom hello kitty
#how old are you
#one two three four five six seven eight nine ten
##正则表达包含huang
[root@hdp1 ~]# grep '.*huang.*' grep.txt
huangbo is shuaige
huangxiaoming is shuaige
##输出匹配行的前后N行(会包括匹配行)
使用-A参数输出匹配行的后一行:grep -A 1 "huangxiaoming" grep.txt
使用-B参数输出匹配行的前一行:grep -B 1 "huangxiaoming" grep.txt
使用-C参数输出匹配行的前后各一行:grep -C 1 "huangxiaoming" grep.txt
正则表达式:
#正则表达式:点代表任意一个字符
[root@hdp1 ~]# grep 'h.*p' /etc/passwd
#正则表达式:以hadoop开头
[root@hdp1 ~]# grep '^hdp01' /etc/passwd
#正则表达式:以hadoop结尾
[root@hdp1 ~]# grep 'hdp01$' /etc/passwd
#正则表达式:以h或r开头
[root@hdp1 ~]# grep '^[hr]' /etc/passwd
#不以h和r开头
[root@hdp1 ~]# grep '^[^hr]' /etc/passwd
#不以h到r开头
[root@hdp1 ~]# grep '^[^h-r]' /etc/passwd
正则表达式的简单规则:
. : 任意一个字符
a* : 任意多个a(零个或多个a)
a? : 零个或一个a
a+ : 一个或多个a
.* : 任意多个任意字符
\. : 转义.
o\{2\} : o重复两次
[A-Z]:A-Z任意一个字符
[ABC]:ABC中任意一个字符
##查找不是以#开头的行
[root@localhost ~]# grep -v '^#' grep.txt
[root@localhost ~]# grep -v '^#' grep.txt | grep -v '^$'
2.6.sed(流编辑器)
sed叫做流编辑器,在shell脚本和Makefile中作为过滤——使用非常普遍,也就是把前一个程序的输出引入sed的输入,经过一些列编辑命令转换成另一种格式输出。sed是一种在线编辑器,它一次处理一行内容,处理时,把当前处理的行存储在临时缓冲区中,称为模式空间,接着用sed命令处理缓冲区中的内容,处理完成后,把缓存区的内容送我屏幕。接着处理下一行,这样不断重复,直到文件末尾。文件的内容并没有改变,除非你使用重定向存储输出。
选项:
-n:一般sed命令会把所有数据输出到屏幕,如果加入-n选项的话,则只会把经过sed命令处理的行输出到屏幕。
-e:多点编辑,允许对输入数据应用多条sed命令编辑
-i:用sed的修改结果直接修改读取数据的文件,而不会由屏幕输出。
动作:
a:追加,在当前行后添加一行或多行
c:行替换,用c后面的字符串填好原数据行
d:行删除命令,前面跟数字指定删除的行
i:插入,在当前行前插入一行或多行
p:打印,输出指定的行
s:字符串替换,用一个字符串替换另一个字符串。格式为 '行范围 s/旧字符串/新字符串/g' (如果不加g的话,则表示只替换每行第一个匹配的字符串)
1、删除:d命令
#删除sed.txt文件的第二行。
sed '2d' sed.txt
#删除sed.txt文件的第二行到末尾所有行。
sed '2,$d' sed.txt
#删除sed.txt文件的最后一行。
sed '$d' sed.txt
删除sed.txt文件所有包含test的行。
sed '/test/d ' sed.txt
删除sed.txt文件所有包含字母的行。
sed '/[A-Za-z]/d ' sed.txt
2、整行替换:c命令
#将第二行替换成hello world
sed '2c hello world' sed.txt
3、字符串替换:s命令
## 如果没有g标记,则只有每行第一个匹配的hello被替换成hi。
sed 's/hello/hi/g' sed.txt
## 此种写法表示只替换每行的第2个hello为hi
sed 's/hello/hi/2' sed.txt
## 此种写法表示只替换每行的第2个以后的hello为hi(包括第2个)
sed 's/hello/hi/2g' sed.txt
## -n选项和p表示只打印那些发生替换的行。如果某一行开头的hello被替换成hi就打印它。
sed -n 's/^hello/hi/p' sed.txt
## 打印输出sed.txt中的第2行和第4行
sed -n '2,4p' sed.txt
## &符号表示追加一个串到找到的串后。所有以192.168.0.1开头的行都会被替换成它自已加 -localhost,变成192.168.0.1-localhost。第三句表示给IP地址添加中括号
sed -n 's/hello/&-hi/gp' sed.txt
sed 's/^192.168.0.1/&-localhost/' sed.txt
sed 's/^192.168.0.1/[&]/' sed.txt
## liu被标记为\1,所以liu会被保留下来(\1 == liu)
## ling被标记为\2,所以ling也会被保留下来(\2 == ling)
## 所以最后的结果就是\1tao\2ss == "liu" + "tao" + "ling" + "ss"
此处切记:\1代表的是被第一个()包含的内容,\1代表的是被第一个()包含的内容,……
上面命令的意思就是:被括号包含的字符串会保留下来,然后跟其他的字符串比如tao和ss组成新的字符串liutaolingss
sed -n 's/\(liu\)jialing/\1tao/p' sed.txt
sed -n 's/\(liu\)jia\(ling\)/\1tao\2ss/p' sed.txt
## 不论什么字符,紧跟着s命令的都被认为是新的分隔符,所以,"#"在这里是分隔符,代替了默认的"/"分隔符。表示把所有hello替换成hi。
sed 's#hello#hi#g' sed.txt
## 所有在模板today和hello所确定的范围内的行都被打印。都找第一个,也就是说,从第一个today到第一个hello
sed -n '/today/,/hello/p' sed.txt
## 打印从第五行开始到第一个包含以hello开始的行之间的所有行。
sed -n '5,/^hello/p' sed.txt
sed -n '/^hello/,8p' sed.txt
## 对于模板today和hello之间的行,每行的末尾用字符串www替换。
sed '/today/,/hello/s/$/www/' sed.txt
## 对于模板today和hello之间的行,每行的开头用字符串www替换。
sed '/today/,/hello/s/^/www/' sed.txt
## 将以字母开头的行中的数字5替换成five
sed '/^[A-Za-z]/s/5/five/g' sed.txt
4、多点编辑:e命令
## -e允许在同一行里执行多条命令。
## 如例子所示,第一条命令删除1至5行,第二条命令用hello替换hi。
## 命令的执行顺序对结果有影响。如果两个命令都是替换命令,那么第一个替换命令将影响第二个替换命令的结果。
sed -e '1,5d' -e 's/hello/hi/' sed.txt
## 一个比-e更好的命令是--expression。它能给sed表达式赋值。
sed --expression='s/hello/hi/' --expression='/today/d' sed.txt
5、从文件读入:r命令
## file里的内容被读进来,显示在与hello匹配的行下面,如果匹配多行,则file的内容将显示在所有匹配行的下面。
sed '/hello/r file' sed.txt
6、写入文件:w命令
## 在huangbo.txt中所有包含hello的行都被写入file里。
sed -n '/hello/w file' sed.txt
7、追加命令:a命令
## '--->this is a example'被追加到以hello开头的行(另起一行)后面,sed要求命令a后面有一个反斜杠。
sed '/^hello/a\\--->this is a example' sed.txt
8、插入:i命令
## 如果test被匹配,则把反斜杠后面的文本插入到匹配行的前面。
sed '/test/i\\some thing new -------------------------' sed.txt
9、下一个:n命令
## 如果hello被匹配,则移动到匹配行的下一行,替换这一行的aa,变为bb,并打印该行
## 替换下一行的第一个aa
sed '/hello/{n; s/aa/bb/;}' sed.txt
## 替换下一行的全部aa
sed '/hello/{n; s/aa/bb/g;}' sed.txt
10、退出:q命令
sed '10q' sed.txt
## 打印完第10行后,退出sed。
## 同样的写法:
sed -n '1,10p ' sed.txt
2.7.awk(报表生成器)
Awk是一个强大的处理文本的编程语言工具,其名称得自于它的创始人Alfred Aho、Peter Weinberger和Brian Kernighan 姓氏的首个字母,相对于grep的查找,sed的编辑,awk在其对数据分析并生成报告时,显得尤为强大。AWK 提供了极其强大的功能:可以进行样式装入、流控制、数学运算符、进程控制语句甚至于内置的变量和函数。简单来说awk就是扫描文件中的每一行,查找与命令行中所给定内容相匹配的模式。如果发现匹配内容,则进行下一个编程步骤。如果找不到匹配内容,则继续处理下一行。
1、假设last -n 5的输出如下:
[root@localhost ~]# last -n 5
root pts/0 192.168.123.1 Wed Dec 28 01:55 still logged in
reboot system boot 2.6.32-573.el6.x Tue Dec 27 04:25 - 03:11 (22:46)
root pts/1 192.168.123.1 Tue Dec 27 02:00 - 02:00 (00:00)
root pts/1 192.168.123.1 Tue Dec 27 01:59 - 02:00 (00:00)
root pts/0 192.168.123.1 Tue Dec 27 01:59 - down (00:16)
2、只显示五个最近登录的账号:
[root@localhost ~]# last -n 5 | awk '{print $1}'
root
reboot
root
root
root
awk工作流程是这样的:读入有'\n'换行符分割的一条记录,然后将记录按指定的域分隔符划分域,填充域,$0则表示所有域,$1表示第一个域,$n表示第n个域。默认域分隔符是"空白键" 或 "[tab]键",所以$1表示登录用户,$3表示登录用户ip,以此类推
3、显示/etc/passwd的账户:
[root@localhost ~]# cat /etc/passwd |awk -F ':' '{print $1}'
root
bin
daemon
adm
lp
这种是awk+action的示例,每行都会执行action{print $1}。-F指定域分隔符为':'
4、显示/etc/passwd的账户和账户对应的shell,而账户与shell之间以tab键分割
[root@localhost ~]# cat /etc/passwd |awk -F ':' '{print $1"\t"$7}'
root /bin/bash
bin /sbin/nologin
daemon /sbin/nologin
adm /sbin/nologin
lp /sbin/nologin
5、BEGIN and END 关键字
如果只是显示/etc/passwd的账户和账户对应的shell,而账户与shell之间以逗号分割,而且在所有行添加列名name,shell,在最后一行添加"blue,/bin/nosh"。
cat /etc/passwd |awk -F ':' 'BEGIN {print "name,shell"} {print $1","$7} END {print "blue,/bin/nosh"}'
cat /etc/passwd | awk -F ':' 'BEGIN {print "name \t shell"} {print$1"\t"$7} END {print "blue,/bin/bash"}'
name,shell
root,/bin/bash
daemon,/bin/sh
....
blue,/bin/nosh
awk工作流程是这样的:先执行BEGIN,然后读取文件,读入有/n换行符分割的一条记录,然后将记录按指定的域分隔符划分域,填充域,$0则表示所有域,$1表示第一个域,$n表示第n个域,随后开始执行模式所对应的动作action。接着开始读入第二条记录••••••直到所有的记录都读完,最后执行END操作。
6、搜索/etc/passwd有root关键字的所有行
awk -F: '/root/' /etc/passwd
root:x:0:0:root:/root:/bin/bash
这种是pattern的使用示例,匹配了pattern(这里是root)的行才会执行action(没有指定action,默认输出每行的内容)。
搜索支持正则,例如找root开头的: awk -F: '/^root/' /etc/passwd
搜索/etc/passwd有root关键字的所有行,并显示对应的shell
awk -F ':' '/root/{print $7}' /etc/passwd
/bin/bash
这里指定了action{print $7}
6、awk常见内置变量
FILENAME:awk浏览的文件名
FNR:浏览文件的记录数,也就是行数。awk是以行为单位处理的,所以每行就是一个记录
NR:awk读取文件每行内容时的行号
NF:浏览记录的域的个数。可以用它来输出最后一个域
FS:设置输入域分隔符,等价于命令行-F选项
OFS:输出域分隔符
统计/etc/passwd:文件名,每行的行号,每行的列数,对应的完整行内容
awk -F ':' '{print "filename:" FILENAME ",linenumber:" NR ",columns:" NF ",linecontent:"$0}' /etc/passwd
awk -F':' '{print "filename:" FILENAME ",linenumber:" NR ",colums:" NF "linecotent:" $0}' /etc/passwd
filename:/etc/passwd,linenumber:3,columns:7,linecontent:bin:x:2:2:bin:/bin:/bin/sh
filename:/etc/passwd,linenumber:4,columns:7,linecontent:sys:x:3:3:sys:/dev:/bin/sh
使用printf替代print,可以让代码更加简洁,易读
awk -F ':' '{printf("filename:%s,linenumber:%s,columns:%s,linecontent:%s\n",FILENAME,NR,NF,$0)}' /etc/passwd
指定输入分隔符,指定输出分隔符:
awk 'BEGIN {FS=":"; OFS="\t"} {print $1, $2}' /etc/passwd
sshd x
tcpdump x
linux x
8、实用例子
A:打印最后一列:
awk -F: '{print $NF}' /etc/passwd
awk -F: '{printf("%s\n",$NF);}' /etc/passwd
B:统计文件行数:
awk 'BEGIN {x=0} {x++} END {print x}' /etc/passwd
C:打印9*9乘法表:
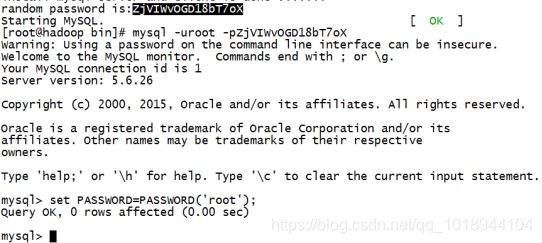
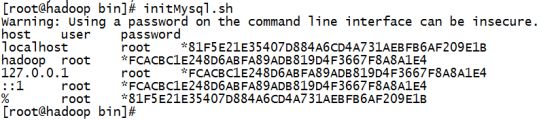
awk 'BEGIN{for(n=0;n++<9;){for(i=0;i++ awk 'BEGIN {for(i=1;i<=9;i++){for(j=1;j<=i;j++){printf i"*"j"="i*j" ";}print ""}}' awk 'BEGIN {for(i=9;i>=1;i--){for(j=i;j>=1;j--){printf i"*"j"="i*j" ";}print ""}}' D:计算1-100之和: echo "sum" | awk 'BEGIN {sum=0;} {i=0;while(i<101){sum+=i;i++}} END {print sum}' 9、更多详细用法参见官网:http://www.gnu.org/software/gawk/manual/gawk.html 功能: 搜索文件目录层次结构 格式: find path -option actions find <路径> <选项> [表达式] 常用可选项: -name 根据文件名查找,支持('* ' , '? ') -type 根据文件类型查找(f-普通文件,c-字符设备文件,b-块设备文件,l-链接文件,d-目录) -perm 根据文件的权限查找,比如 755 -user 根据文件拥有者查找 -group 根据文件所属组寻找文件 -size 根据文件小大寻找文件 -o 表达式 或 -a 表达式 与 -not 表达式 非 示例: ## 准备的测试文件 [linux@linux txt]$ ll total 248 -rw-rw-r--. 1 linux linux 235373 Apr 18 00:10 hw.txt -rw-rw-r--. 1 linux linux 0 Apr 22 05:43 LINUX.pdf -rw-rw-r--. 1 linux linux 3 Apr 22 05:50 liujialing.jpg -rw-rw-r--. 1 linux linux 0 Apr 22 05:43 mingxing.pdf -rw-rw-r--. 1 linux linux 57 Apr 22 04:40 mingxing.txt -rw-rw-r--. 1 linux linux 66 Apr 22 05:15 sort.txt -rw-rw-r--. 1 linux linux 214 Apr 18 10:08 test.txt -rw-rw-r--. 1 linux linux 24 Apr 22 05:27 uniq.txt ## 查找文件名txt结尾的文件 [linux@linux txt]$ find /home/linux/txt/ -name "*.txt" /home/linux/txt/uniq.txt /home/linux/txt/mingxing.txt /home/linux/txt/test.txt /home/linux/txt/hw.txt /home/linux/txt/sort.txt ## 忽略大小写查找文件名包含linux [linux@linux txt]$ find /home/linux/txt -iname "*linux*" /home/linux/txt/LINUX.pdf ## 查找文件名结尾是.txt或者.jpg的文件 [linux@linux txt]$ find /home/linux/txt/ \( -name "*.txt" -o -name "*.jpg" \) /home/linux/txt/liujialing.jpg /home/linux/txt/uniq.txt /home/linux/txt/mingxing.txt /home/linux/txt/test.txt /home/linux/txt/hw.txt /home/linux/txt/sort.txt 另一种写法:find /home/linux/txt/ -name "*.txt" -o -name "*.jpg" 使用正则表达式的方式去查找上面条件的文件: [linux@linux txt]$ find /home/linux/txt/ -regex ".*\(\.txt\|\.jpg\)$" /home/linux/txt/liujialing.jpg /home/linux/txt/uniq.txt /home/linux/txt/mingxing.txt /home/linux/txt/test.txt /home/linux/txt/hw.txt /home/linux/txt/sort.txt ## 查找.jpg结尾的文件,然后删掉 [linux@linux txt]$ find /home/linux/txt -type f -name "*.jpg" -delete [linux@linux txt]$ ll total 248 -rw-rw-r--. 1 linux linux 235373 Apr 18 00:10 hw.txt -rw-rw-r--. 1 linux linux 0 Apr 22 05:43 LINUX.pdf -rw-rw-r--. 1 linux linux 0 Apr 22 05:43 mingxing.pdf -rw-rw-r--. 1 linux linux 57 Apr 22 04:40 mingxing.txt -rw-rw-r--. 1 linux linux 66 Apr 22 05:15 sort.txt -rw-rw-r--. 1 linux linux 214 Apr 18 10:08 test.txt -rw-rw-r--. 1 linux linux 24 Apr 22 05:27 uniq.txt Linux中操作字符串,也是一项必备的技能。其中尤以截取字符串更加频繁,下面为大家介绍几种常用方式,截取字符串。 1、#截取,删除左边字符串(包括制定的分隔符),保留右边字符串 预先定义一个变量:WEBSITE='http://hadoop//centos/huangbo.html' [root@hadoop ~]# echo ${WEBSITE##*//} 结果:centos/huangbo.html 2、##截取,删除左边字符串(包括指定的分隔符),保留右边字符串,和上边一个#不同的是,它一直找到最后,而不是像一个#那样找到一个就满足条件退出了。 [root@hadoop ~]# echo ${WEBSITE##*//} 结果:centos/huangbo.html 3、%截取,删除右边字符串(包括制定的分隔符),保留左边字符串 [root@hadoop ~]# echo ${WEBSITE%//*} 结果:http://hadoop 4、%%截取,删除右边字符串(包括指定的分隔符),保留左边字符串,和上边一个%不同的是,它一直找到最前,而不是像一个%那样找到一个就满足条件退出了。 [root@hadoop ~]# echo ${WEBSITE%%//*} 结果:http: 总结以上四种方式: # 去掉左边,最短匹配模式, ##最长匹配模式。 % 去掉右边,最短匹配模式, %%最长匹配模式 5、从左边第几个字符开始,以及截取的字符的个数 [root@hadoop ~]# echo ${WEBSITE:2:2} 结果:tp 6、从左边第几个字符开始,一直到结束 [root@hadoop ~]# echo ${WEBSITE:2} 结果:tp://hadoop//centos//huangbo.html 7、从右边第几个字符开始,以及字符的个数 [root@hadoop ~]# echo ${WEBSITE:0-4:2} 结果:ht 8、从右边第几个字符开始,一直到结束 [root@hadoop ~]# echo ${WEBSITE:0-4} 结果:html 9、利用awk进行字符串截取 [root@hadoop ~]# echo $WEBSITE | awk '{print substr($1,2,6)}' 结果:ttp:// 10、利用cut进行字符串截取 [root@hadoop ~]# echo $WEBSITE | cut -b 1-4 http [root@hadoop ~]# echo $WEBSITE | cut -c 1-4 http [root@hadoop ~]# echo $WEBSITE | cut -b 1,4 hp [root@hadoop ~]# echo $WEBSITE | cut -c 1,4 hp 11、获取最后几个字符 [root@hadoop ~]# echo ${WEBSITE:(-3)} 结果:tml 12、截取从倒数第3个字符后的2个字符 [root@hadoop ~]# echo ${WEBSITE:(-3):2} 结果:tm 使用格式:${parameter/pattern/string} 例子: ##定义变量VAR: [linux@linux ~]$ VAR="hello tom, hello kitty, hello xiaoming" ##替换第一个hello: [linux@linux ~]$ echo ${VAR/hello/hi} hi tom, hello kitty, hello xiaoming ##替换所有hello: [linux@linux ~]$ echo ${VAR//hello/hi} hi tom, hi kitty, hi xiaoming 在此为大家提供五种方式获取某字符串的长度。 1、使用wc -L命令 [root@hadoop ~]# echo ${WEBSITE} |wc -L 35 2、使用expr的方式去计算 [root@hadoop ~]# expr length ${WEBSITE} 35 3、通过awk + length的方式获取字符串长度 [root@hadoop ~]# echo ${WEBSITE} | awk '{print length($0)}' 35 4、通过awk的方式计算以""分隔的字段个数 [root@hadoop ~]# echo ${WEBSITE} |awk -F "" '{print NF}' 35 5、通过#的方式获取字符串(最简单,最常用) [root@hadoop ~]# echo ${#WEBSITE} 35 安装mysql脚本: #!/bin/bash ## auto install mysql ## 假如是第二次装,那么要先停掉服务,并且卸载之前的mysql service mysql stop EXISTS_RPMS=`rpm -qa | grep -i mysql` echo ${EXISTS_RPMS} for RPM in ${EXISTS_RPMS} do rpm -e --nodeps ${RPM} done ## 删除残留文件 rm -fr /usr/lib/mysql rm -fr /usr/include/mysql rm -f /etc/my.cnf rm -fr /var/lib/mysql ## 从服务器获取安装mysql的rpm包 wget http://linux/soft/MySQL-client-5.6.26-1.linux_glibc2.5.x86_64.rpm wget http://linux/soft/MySQL-server-5.6.26-1.linux_glibc2.5.x86_64.rpm ## 删除之前的密码文件,以免产生干扰 rm -rf /root/.mysql_secret ## 安装服务器 rpm -ivh MySQL-server-5.6.26-1.linux_glibc2.5.x86_64.rpm ## 获取到生成的随机密码 ##PSWD=`cat /root/.mysql_secret | awk -F ':' '{print substr($4,2,16)}'` PSWD=` grep -v '^$' /root/.mysql_secret | awk -F ':' '{print substr($4,2,16)}'` ##PSWD=${PWD:1:16} ## 安装客户端 rpm -ivh MySQL-client-5.6.26-1.linux_glibc2.5.x86_64.rpm ## 然后删除刚刚下下来的rpm包 rm -rf MySQL-client-5.6.26-1.linux_glibc2.5.x86_64.rpm rm -rf MySQL-server-5.6.26-1.linux_glibc2.5.x86_64.rpm ## 提示安装的步骤都完成了。 echo "install mysql server and client is done .!!!!!!" ## 打印出来刚刚生成的mysql初始密码 echo "random password is:${PSWD}" ## 开启mysql服务 service mysql start 手动第一次登陆,然后改掉密码: [root@hadoop bin]# mysql -uroot -pZjVIWvOGD18bT7oX mysql> set PASSWORD=PASSWORD('root'); 现在就可以写脚本链接mysql进行操作了 [root@hadoop bin]# vi initMysql.sh #!/bin/bash mysql -uroot -proot << EOF GRANT ALL PRIVILEGES ON *.* TO 'root'@'%' IDENTIFIED BY 'root' WITH GRANT OPTION; FLUSH PRIVILEGES; use mysql; select host, user, password from user; EOF 2.8.find
3.Shell 操作字符串
3.1.字符串截取
3.2.字符串替换
3.3.获取字符串长度
4. Shell脚本自动安装MySQL