R语言 | 记一次用R语言进行数据分析的经历
利用R语言进行数据分析
- 1 前言
- 2 问题及解决思路和代码
- 2.1 问题1:逻辑判断生成新变量
- 2.1.1 问题描述
- 2.1.2 规则
- 2.1.3 对应的R语言基础
- 2.1.4 伪代码
- 2.1.5 真正的实现
- 2.1.6 分组计算得结果
- 2.2 问题2:正则提取特征+绘制对比箱线图
- 2.2.1 问题描述
- 2.2.2 正则提取1
- 2.2.3 正则提取2
- 2.2.4 绘图
- 参考
1 前言
最近无论是实习还是做项目,更多的都是使用Python来做一些分析,建模的工作,最近刚好用到R语言来解决了几个task,好久没用R语言,导致很多的语法有些生疏,另外一些函数的用法也有些遗忘,所以边写边查浪费了不少时间,于是现在复盘一下整个的工作,优化下代码,另外把常用的代码进行总结整理,方便下次写代码的时候查询,而不是每次都Google半天…
2 问题及解决思路和代码
2.1 问题1:逻辑判断生成新变量
2.1.1 问题描述

而原始数据长啥样呢,见下图:
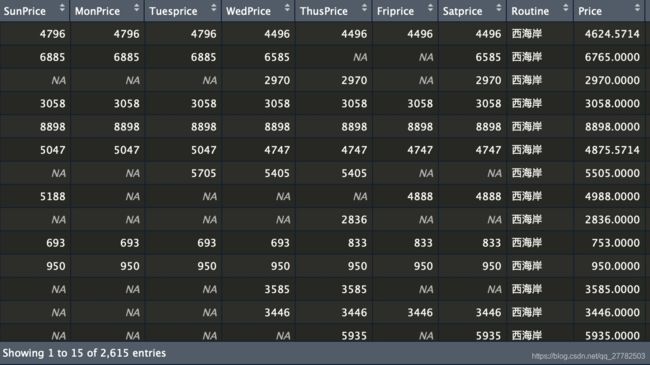
2.1.2 规则
总结一下这个问题:
- 现在的需求就是要新生成一列:Date,生成规则有三种:
- 仅工作日:周一至周五任一不为空且周六周日全为空
- 仅周末:周六周日任一为不空且周一至周五全为空
- 工作日和周末:周一~周五任一非空且周六周日任一非空
2.1.3 对应的R语言基础
针对上述的三种规则,对应到R语言里,就转换为了两个核心问题:如何运用R语言实现→
- 判断一个元素为空或者非空?
- 逻辑符号 且 或 ?
首先第一个问题:
1、R语言判断一个元素为空或者非空:
is.na(x)如果返回True 表示为缺失值 即为空complete.cases(x)如果返回True 表示完整 不为缺失值 即非空
解决了这个问题,那么下面来看下第二个问题:
2、R语言中的逻辑符号
首先记住 以后在R语言里 统一使用下面两种:因为它们是针对标量的!
- 且:&&
- 或:||
梳理一下R语言的逻辑操作符:
- 且:&& 和 &
x <- c( TRUE, FALSE, TRUE )
y <- c( FALSE, TRUE, FALSE )
x & y # 向量的且 如果是向量比较返回多个结果 单个元素比较返回一个结果
x[1] & y[1]
x && y # 标量的且 只支持单个元素比较,如果是向量 只比较第一个元素然后返回结果
x[1] && y[1]
[1] FALSE FALSE FALSE
[1] FALSE
[1] FALSE
[1] FALSE
x | y # 向量的或 如果是向量比较返回多个结果 单个元素比较返回一个结果
x[1] | y[1]
x || y # 标量的或 只支持单个元素比较,如果是向量 只比较第一个元素然后返回结果
x[1] || y[1]
[1] TRUE TRUE TRUE
[1] TRUE
[1] TRUE
[1] TRUE
2.1.4 伪代码
有了上面的R语言基础之后,下面开始写代码!
首先就得弄清楚代码逻辑怎么写,我们一个一个来看!
- 仅工作日:周一至周五任一不为空且周六周日全为空
那么逻辑上就应该是:
(周一非空 或 周二非空 或 周三非空 或 周四非空 或 周五非空)且(周六空 且 周日空)
if((is.na(travel_dat[x, 'Satprice']) && is.na(travel_dat[x, 'SunPrice']))
&& (complete.cases(travel_dat[x,'MonPrice']) || complete.cases(travel_dat[x,'Tuesprice']) || complete.cases(travel_dat[x,'WedPrice'])
|| complete.cases(travel_dat[x,'ThusPrice']) || complete.cases(travel_dat[x,'Friprice'])) ){
travel_dat[x, 'Date'] = '工作日'
}
- 仅周末:周六周日任一为不空且周一至周五全为空
else if((complete.cases(travel_dat[x, 'Satprice']) || complete.cases(travel_dat[x, 'SunPrice']))
&& (is.na(travel_dat[x,'MonPrice']) && is.na(travel_dat[x,'Tuesprice']) && is.na(travel_dat[x,'WedPrice'])
&& is.na(travel_dat[x,'ThusPrice']) && is.na(travel_dat[x,'Friprice']))){
travel_dat[x, 'Date'] = '仅周末'
}
- 工作日和周末:周一~周五任一非空且周六周日任一非空
else if((complete.cases(travel_dat[x, 'Satprice']) || complete.cases(travel_dat[x, 'SunPrice']))
&& (complete.cases(travel_dat[x,'MonPrice']) || complete.cases(travel_dat[x,'Tuesprice']) || complete.cases(travel_dat[x,'WedPrice'])
|| complete.cases(travel_dat[x,'ThusPrice']) || complete.cases(travel_dat[x,'Friprice'])) ){
travel_dat[x, 'Date'] = '工作日和周末'
}
2.1.5 真正的实现
两种思路:
- 第一种是使用for循环,每一行做一个这样的判断 然后赋值到新列上
- 第二种是高效的使用apply函数!
实现1:for循环
代码:
# for循环版本
travel_dat['Date'] = NA # 知识点!如何给一个变量赋予空值!
# travel_dat[1, 'SunPrice']
for (x in 1:dim(travel_dat)[1]) {
if((is.na(travel_dat[x, 'Satprice']) && is.na(travel_dat[x, 'SunPrice']))
&& (complete.cases(travel_dat[x,'MonPrice']) || complete.cases(travel_dat[x,'Tuesprice']) || complete.cases(travel_dat[x,'WedPrice'])
|| complete.cases(travel_dat[x,'ThusPrice']) || complete.cases(travel_dat[x,'Friprice'])) ){
travel_dat[x, 'Date'] = '工作日'
}
else if((complete.cases(travel_dat[x, 'Satprice']) || complete.cases(travel_dat[x, 'SunPrice']))
&& (is.na(travel_dat[x,'MonPrice']) && is.na(travel_dat[x,'Tuesprice']) && is.na(travel_dat[x,'WedPrice'])
&& is.na(travel_dat[x,'ThusPrice']) && is.na(travel_dat[x,'Friprice']))){
travel_dat[x, 'Date'] = '仅周末'
}
else if((complete.cases(travel_dat[x, 'Satprice']) || complete.cases(travel_dat[x, 'SunPrice']))
&& (complete.cases(travel_dat[x,'MonPrice']) || complete.cases(travel_dat[x,'Tuesprice']) || complete.cases(travel_dat[x,'WedPrice'])
|| complete.cases(travel_dat[x,'ThusPrice']) || complete.cases(travel_dat[x,'Friprice'])) ){
travel_dat[x, 'Date'] = '工作日和周末'
}
}
实现的结果为:符合筛选条件!
View(travel_dat[,c(12:18,24)]) # 注意要加上c
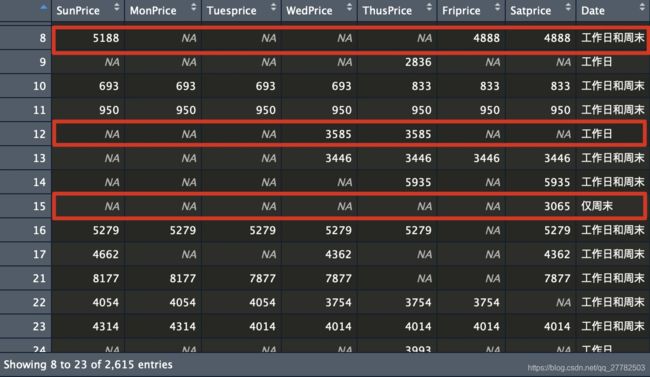
实现2:apply
首先来个apply基础:
x=array(rnorm(12),c(3,4))
x
# 求每一行的均值 即按行操作 1
apply(x, 1, mean)
# 求每一列的均值 即按列操作 2
apply(x, 2, mean)
结果为:
[,1] [,2] [,3] [,4]
[1,] -0.2650878 -1.2321359 0.0336468 -0.3757341
[2,] -0.1651225 -0.2583198 -0.6266415 -1.8395429
[3,] 1.9981034 -0.9932305 -2.3548473 1.8798499
[1] -0.4598278 -0.7224067 0.1324689
[1] 0.5226310 -0.8278954 -0.9826140 -0.1118090
总结:
- apply函数有3个参数:
- 第一个是要操作的对象
- 第二个看按行还是按列操作
- 第三个是操作函数
下面自定义函数run一下:
# 自定义函数
myFun1 = function(x){sum(x[1]^2 + x[2]^3 + x[3]^3 + x[4]^4)}
apply(x, 1, myFun1)
myFun2 = function(x){sum(x[1] - x[2] + x[3])}
apply(x, 2, myFun2)
结果为:
[1] -1.780338 11.214861 2.442234
[1] 1.898138 -1.967047 -1.694559 3.343659
ok,现在有了上面apply的基础了,下面开始将上面for循环代码改写为apply 提高效率。分为两步走:
- 第一步是自定义函数
- 第二步是生成新的列
Datefun = function(x){
# print(x[1])
# print((is.na(x[7]) && is.na(x[1])))
if((is.na(x[7]) && is.na(x[1])) && (complete.cases(x[2]) || complete.cases(x[3]) || complete.cases(x[4])
|| complete.cases(x[5]) || complete.cases(x[6]))){
return('工作日')
}
else if((complete.cases(x[7]) || complete.cases(x[1]))
&& (is.na(x[2]) && is.na(x[3]) && is.na(x[4])
&& is.na(x[5]) && is.na(x[6]))){
return('仅周末')
}
else if((complete.cases(x[7]) || complete.cases(x[1]))
&& (complete.cases(x[2]) || complete.cases(x[3]) || complete.cases(x[4])
|| complete.cases(x[5]) || complete.cases(x[6]))){
return('工作日和周末')
}
}
# 注意 R语言 的if else 语句格式!必须要有括号括起来!
travel_dat['Date'] = apply(travel_dat[,12:18], 1, Datefun)
# 大功告成!注意一定要括号ok!
结果和上面是一模一样的,不再列出。
2.1.6 分组计算得结果
新生成了Date列其实已经成功了90%了,下面就是根据这一列来进行分组计算价格的均值!
同样有两种方法:
法1:使用summarise函数
library(dplyr)
summarise(group_by(travel_dat,Date),mean(Price,na.rm = T))
输出结果为:
# A tibble: 3 x 2
Date `mean(Price, na.rm = T)`
1 仅周末 6929.
2 工作日 5275.
3 工作日和周末 5787.
法2:使用aggregate函数
options(digits=6)
aggregate(travel_dat$Price, by=list(type=travel_dat$Date), mean)
输出结果为:
type x
1 仅周末 6929.40
2 工作日 5275.20
3 工作日和周末 5787.28
2.2 问题2:正则提取特征+绘制对比箱线图
2.2.1 问题描述
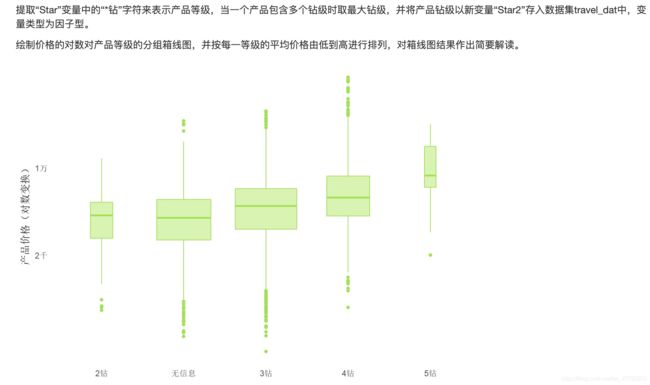
可以看到这个问题首先要对变量Star动刀子!那我们首先来看看这个变量长啥样吧!
根据题意,提取方式的典例应该为下表:
| 样本 | star | star2 |
|---|---|---|
| 1 | 5晚3钻 | 3钻 |
| 2 | 暂无酒店信息 | 无信息 |
| 1 | 3晚4钻,4晚3钻 | 4钻 |
2.2.2 正则提取1
这时候我们首先想到的肯定是正则表达式来提取,没毛病,但之前小编更多的是用Python和正则表达式结合使用,具体见博客:Python | 正则表达式 R语言和正则结合用的少一些,但是本质上正则表达式的写法是一致的,只不过语法上会有些许的差别而已。下面我们就来看看如何在R中使用正则表达式提取字符!
这时候2行代码即可解决问题!
library(stringr)
# 正则匹配所有的钻出来 但是无法取最大
travel_dat$Star00 = str_extract_all(string = travel_dat$Star, pattern = "\\d钻")
head(travel_dat$Star00)
输出结果为:
[[1]]
[1] "3钻"
[[2]]
[1] "3钻"
[[3]]
character(0)
[[4]]
[1] "3钻"
[[5]]
character(0)
[[6]]
[1] "3钻"
其实含钻的信息都被提取出来了,正则的写法也比较简单,就是数字+钻即可!但有2点需要注意:
- 首先Python中如果写这个表达式,应该是
\d钻,而在R语言中要使用两个反斜杠\\d钻所以还是存在细微的差别,关于R语言中正则的语法可参考博文:正则表达式及R字符串处理之终结版 - 其次,在上面注释中我也提到了,现在这样的结果虽然把数字和钻提出来了,但是没法解决返回多个结果的情况!也就是无法直接取最大!
2.2.3 正则提取2
针对上面的问题,该如何解决呢?首先自然的思路是:能不能在写正则表达式的时候就能够取多个数字的最大呢?遗憾的是,小编查了很久的资料没有发现,也欢迎找到的小伙伴在下方留言告诉me~ ok 此路行不通,那有没有其余的路可以走呢?
这么想,如果我基于目前的结果再把数字提取出来,然后再通过某种方式让每一行数字都变为数值型(现在是字符型),再每行取最大!最后就是实现字符串的拼接,即每个数字后面加上“钻”字即可!ok!完美!
# 单独把数字拿出来
travel_dat$Star22 = str_extract_all(string = travel_dat$Star00, pattern = "\\d")
# 自定义函数
Transfun = function(x){
# 实现的功能:每行取最大的数字
return(max(unlist(x)))
}
# 批量实现
travel_dat$Star2 = apply(travel_dat[,c('Star22'),drop=F], 1, Transfun) # 如果只有一列多加一个命令
head(travel_dat$Star2)
这里面有两个坑:
- 首先是正则取出来的结果不是一个向量,而是list,所以要加一个
unlist,可参考:How to coerce a list object to type ‘double’ - 其次就是如果只有一列 然后按行操作apply 需要加上
,drop=F,详情见参考:dim(X) must have a positive length when applying function in data frame
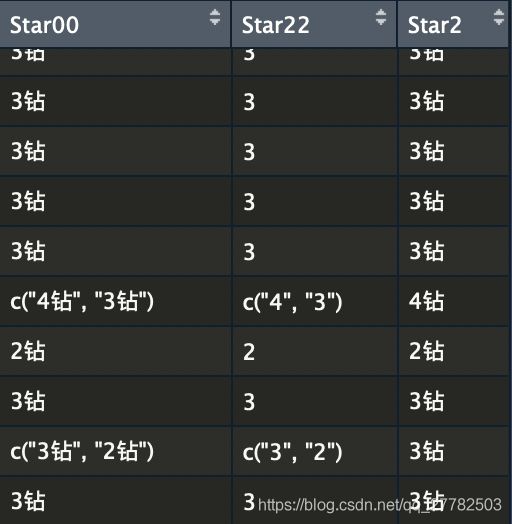
这时候我们得到的结果见下图,可以看到实现了取最大!接下来工作就轻松了!
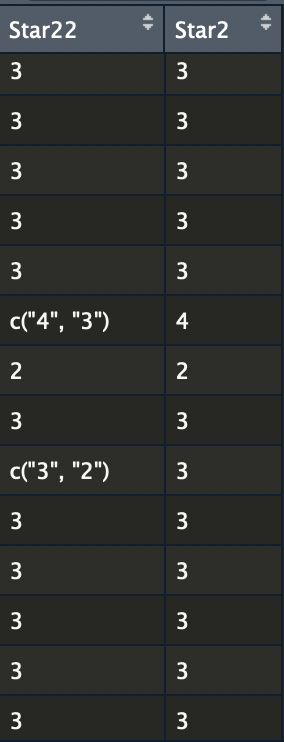
实现字符添加:
# 变换类型为字符型
travel_dat$Star2 = unlist(travel_dat$Star2)
mode(travel_dat$Star2)
# 统一加上‘钻’
travel_dat$Star2 = paste0(travel_dat$Star2, '钻') # 注意past0字符之间无空格 paste有
# 将0进行替换
travel_dat[travel_dat$Star2 == '0钻', 'Star2'] <- '无信息'
现在再来看看数据变成了啥样,已经提取变量ok了!下面就是绘图任务!
2.2.4 绘图
绘图这时候直接贴代码:
# 转化为因子类型
# 先进行排序获取因子的顺序
a = aggregate(travel_dat$Price, by=list(type=travel_dat$Star2), mean) %>% as.data.frame()
a = a[order(a[,2], decreasing = F),]
travel_dat$Star2 <- factor(travel_dat$Star2, levels = a$type)
# 需要ggplot绘制对比箱线图
library(ggplot2)
p<-ggplot(data=travel_dat, aes(x=Star2,y=log(travel_dat$Price),fill=Star2))+
geom_boxplot(show.legend = FALSE, varwidth = T)+
scale_fill_manual(values=c('#CAFF70','#CAFF70','#CAFF70','#CAFF70','#CAFF70'))+
theme(panel.grid.major=element_line(colour=NA), # 去掉网格线
panel.grid.minor=element_line(colour=NA), # 去掉网格线
panel.background = element_blank(), # 不要背景
legend.position = 'none', title = element_text(family = 'STKaiti'), # 设置不要图例
axis.title.x = element_text(family = 'STKaiti'), # 字体大小格式设置
axis.title.y = element_text(family = 'STKaiti', size = 12, face = 'bold'),
axis.text.x = element_text(family = 'STKaiti', size = 12, face = 'bold'))+
labs(x="",y="产品价格(对数变换)", main = "") # 横轴纵轴标题设置
print(p)
结果为:
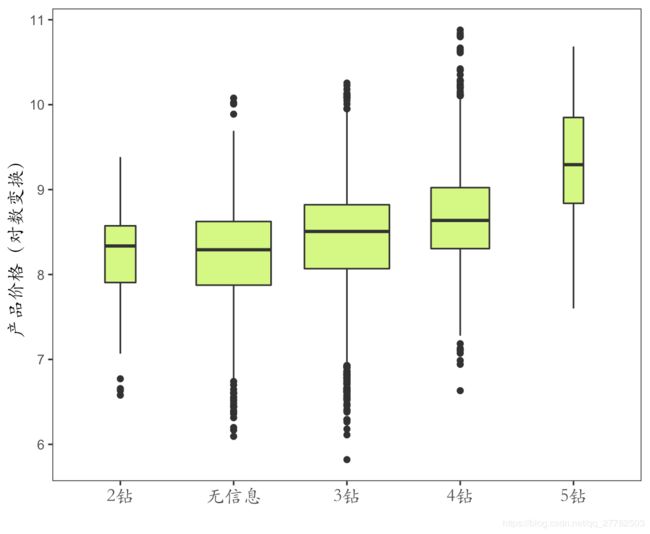
这里面有几个点需要注意:
- ggplot2的语法就是一层一层叠加上去!比较麻烦的是查每个参数的含义。
- 关于R语言里颜色及其对应的代码可以参考:R——颜色篇
- 设置箱子的宽度和样本量保持正比,则加一个参数
varwidth = T
参考
- R的apply函数怎么用?
- R语言 算术和逻辑运算符及数值
- R语言学习笔记:缺失值的判断与处理
- ggplot2画图怎么去掉背景淡灰底色和网格线?
- ggplot2 中去除边框线和背景色的一些操作