网易云音乐歌词分析
网易云音乐歌词分析 - 风挽青个人博客 https://fengwanqing.xin/1137.html
1.环境:python3.6.5 + windows10
2.依赖包: requests(需安装)、fake-useragent(需安装)、matplotlib (需安装) 、scipy==1.2.1(需要指定版本安装)、jieba (需安装) 、wordcloud(需安装)
3.某首歌链接地址(https://music.163.com/#/song?id=412911436)
一、分析网站
1.打开网址,可以看到如下页面

2.F12打开开发者工具
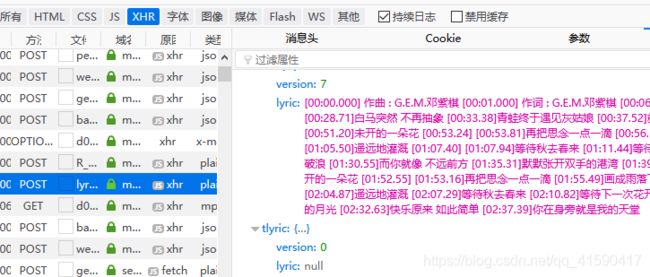
可以看到歌词就保存在ajax请求的一个链接返回数据里面,数据类型是json
二、编写代码
1.base_crawler.py
# codong:utf8
"""
如果报错 fake_useragent.errors.FakeUserAgentError: Maximum amount of retries reached
fake_useragent中存储的UserAgent列表发生了变动,而本地UserAgent的列表未更新所导致的,在更新fake_useragent后报错就消失了。
pip install -U fake-useragent
"""
import requests
import traceback
import csv
import codecs # 可用于python2、python3指定写入或打开文件的编码方式
from fake_useragent import UserAgent # 用来模拟浏览器请求
from multiprocessing.dummy import Pool # 多线程的线程池
import string
import random
import os
ua = UserAgent()
class BaseCrawler(object):
def __init__(self, url):
self.url = url
self.headers = {"User-Agent": ua.random}
def get_web_data(self, method, params="", data="", get_type=1): # 根据请求方式、参数等获取网页数据
try:
response = requests.request(url=self.url, headers=self.headers, method=method, params=params, data=data, timeout=5)
print(response.status_code, response.url)
response.encoding = response.apparent_encoding # 采用网页的编码方式,避免获取的数据乱码
if get_type == 1:
return response.text # 返回文本字符串
else:
return response.json() # 返回json字符串
except:
traceback.print_exc()
return
@staticmethod
def create_random_str(length=12): # 随机生成12位长度的字符串
str_data = string.ascii_letters + string.digits
return "".join(random.sample(str_data, length))
def download_mp4(self, url):
try:
response = requests.get(url, headers=self.headers)
data = response.content # 下载图片、视频都用response.content,表示二进制数据流
if not os.path.exists("mp4"):
os.mkdir("mp4")
filename = os.getcwd()+"/mp4/"+self.create_random_str()+".mp4"
with open(filename, "wb") as f:
f.write(data)
except:
print("download error!!!")
def download(self, urls): # 多线程下载视频,和download_mp4关联
if not isinstance(urls, list):
urls = [urls]
pool = Pool(4)
pool.map(self.download_mp4, urls)
pool.close()
pool.join()
@staticmethod
def write_csv(filename, header, data): # 写入csv表格
f = codecs.open(filename, "w", encoding="gbk")
csv_writer = csv.writer(f, dialect='excel')
csv_writer.writerow(header)
for i in data:
csv_writer.writerow(i)
f.close()
2.cloud_music_lyric_handler.py
# coding:utf8
from base_crawler import BaseCrawler
import traceback
import re
from matplotlib import pyplot as plt
from scipy.misc import imread
import jieba
from wordcloud import WordCloud, ImageColorGenerator
CRAWLER_URL = "http://music.163.com/api/song/lyric"
def parse_web_data():
crawler = BaseCrawler(CRAWLER_URL)
params = {
"id": "412911436",
"lv": 1,
"kv": 1,
"tv": -1
}
webData = crawler.get_web_data("get", params=params, get_type=2) # 获取歌词json数据
try:
lyric_info = webData["lrc"]["lyric"]
reg = ".*?](.*?)\n"
data = re.findall(reg, lyric_info) # 正则匹配查找,结果是列表
data = data[4:] # 去除作曲、作词那些行
text = "".join(data) # 把列表每一句歌词拼凑在一起,用于后面生成词云
return text
except:
traceback.print_exc() # 打印错误
return ""
if __name__ == '__main__':
text = parse_web_data()
三、结果展示

四、jieba分词并生成词云
cloud_music_lyric_handler.py
# coding:utf8
from base_crawler import BaseCrawler
import traceback
import re
from matplotlib import pyplot as plt
from scipy.misc import imread
import jieba
from wordcloud import WordCloud, ImageColorGenerator
CRAWLER_URL = "http://music.163.com/api/song/lyric"
def parse_web_data():
crawler = BaseCrawler(CRAWLER_URL)
params = {
"id": "412911436",
"lv": 1,
"kv": 1,
"tv": -1
}
webData = crawler.get_web_data("get", params=params, get_type=2) # 获取歌词json数据
try:
lyric_info = webData["lrc"]["lyric"]
reg = ".*?](.*?)\n"
data = re.findall(reg, lyric_info) # 正则匹配查找,结果是列表
print(data)
data = data[4:] # 去除作曲、作词那些行
text = "".join(data) # 把列表每一句歌词拼凑在一起
return text
except:
traceback.print_exc() # 打印错误
return ""
def create_word_cloud(text):
if not text:
return
word_generator = jieba.cut(text, cut_all=False) # 分词,返回的是一个迭代器
words_list = list()
for word in word_generator:
if len(word) > 1: # 去掉单字
words_list.append(word)
text = ' '.join(words_list)
back_color = imread('tencent.png') # 解析该图片
wc = WordCloud(
background_color='white', # 背景颜色
max_words=1000, # 最大词数
mask=back_color, # 以该参数值作图绘制词云,这个参数不为空时,width和height会被忽略
max_font_size=100, # 显示字体的最大值
font_path="/Users/tangwenpan/Downloads/simhei.ttf", # 解决显示口字型乱码问题
random_state=42, # 为每个词返回一个PIL颜色
)
wc.generate(text)
image_colors = ImageColorGenerator(back_color) # 基于彩色图像生成相应彩色
plt.figure(figsize=(15, 15))
plt.imshow(wc.recolor(color_func=image_colors)) # 绘制词云
plt.axis('off') # 关闭图像坐标系
plt.show() # 显示图片--在窗口显示
wc.to_file('comment.png') # 保存图片
if __name__ == '__main__':
text = parse_web_data()
create_word_cloud(text)

素材资料补充
tencent.png
