fpn的理解
本部分截取自知乎文章:从代码细节理解 FPN,作者使用Mask-RCNN的源码辅助理解FPN结构,项目地址见MRCNN,
1、 怎么做的上采样?
高层特征怎么上采样和下一层的特征融合的,代码里面可以看到:
| 1 |
|
C5是 resnet最顶层的输出,它会先通过一个1*1的卷积层,同时把通道数转为256,得到FPN 的最上面的一层 P5。
| 1 |
|
Keras 的 API 说明告诉我们:
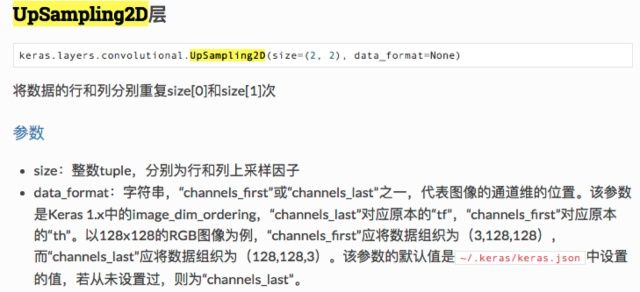
也就是说,这里的实现使用的是最简单的上采样,没有使用线性插值,没有使用反卷积,而是直接复制。
2、 怎么做的横向连接?
| 1 2 3 |
|
这里可以很明显的看到,P4就是上采样之后的 P5加上1*1 卷积之后的 C4,这里的横向连接实际上就是像素加法,先把 P5和C4转换到一样的尺寸,再直接进行相加。
注意这里对从 resnet抽取的特征图做的是 1*1 的卷积:
1x1的卷积我认为有三个作用:使bottom-up对应层降维至256;缓冲作用,防止梯度直接影响bottom-up主干网络,更稳定;组合特征。
3、 FPN自上而下的网络结构代码怎么实现?
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 |
|
注意 P6是用在 RPN 目标区域提取网络里面的,而不是用在 FPN 网络;
另外这里 P2-P5最后又做了一次3*3的卷积,作用是消除上采样带来的混叠效应。
4、 如何确定某个 ROI 使用哪一层特征图进行 ROIpooling ?
看代码:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
|
不同尺度的ROI,使用不同特征层作为ROI pooling层的输入,大尺度ROI就用后面一些的金字塔层,比如P5;小尺度ROI就用前面一点的特征层,比如P4。那怎么判断ROI改用那个层的输出呢?论文的 K 使用如下公式,代码做了一点更改,替换为roi_level:
![]()
| 1 2 |
|
224是ImageNet的标准输入,k0是基准值,设置为5,代表P5层的输出(原图大小就用P5层),w和h是ROI区域的长和宽,image_area是输入图片的长乘以宽,即输入图片的面积,假设ROI是112 * 112的大小,那么k = k0-1 = 5-1 = 4,意味着该ROI应该使用P4的特征层。k值会做取整处理,防止结果不是整数。
5、 上面得到的5个融合了不同层级的特征图怎么使用?
可以看到,这里只使用2-5四个特征图:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
|
对每个 box,都提取其中每一层特征图上该box对应的特征,然后组成一个大的特征列表pooled。
6、 金字塔结构中所有层级共享分类层是怎么回事?
先看代码:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 |
|
这里的PyramidROIAlign得到的 x就是上面一步得到的从每个层的特征图上提取出来的特征列表,这里对这个特征列表先接两个1024通道数的卷积层,再分别送入分类层和回归层得到最终的结果。
也就是说,每个 ROI 都在P2-P5中的某一层得到了一个特征,然后送入同一个分类和回归网络得到最终结果。
FPN中每一层的heads 参数都是共享的,作者认为共享参数的效果也不错就说明FPN中所有层的语义都相似。
7、 它的思想是什么?
把高层的特征传下来,补充低层的语义,这样就可以获得高分辨率、强语义的特征,有利于小目标的检测。
8、 横向连接起什么作用?
如果不进行特征的融合(也就是说去掉所有的1x1侧连接),虽然理论上分辨率没变,语义也增强了,但是AR下降了10%左右!作者认为这些特征上下采样太多次了,导致它们不适于定位。Bottom-up的特征包含了更精确的位置信息。