豆瓣新书速递数据爬取与简单数据处理 | 豆瓣爬虫 & python & pandas
豆瓣新书速递数据爬取与简单数据处理
概要
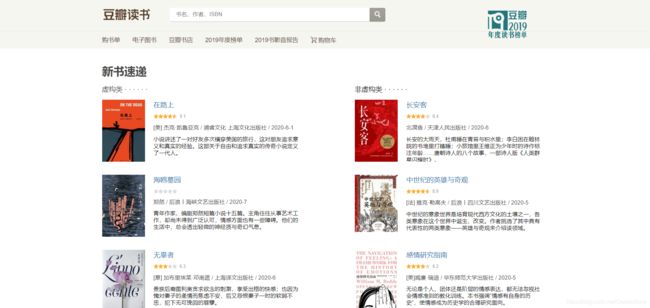
-
数据爬取
爬取豆瓣平台提供的数据,存储到本地 json 文件。
| 数据说明 | URL |
|---|---|
| 豆瓣新书速推 HTML | https://book.douban.com/latest?icn=index-latestbook-all |
| 豆瓣单条图书查询 RESTful API | https://api.douban.com/v2/book/:id?apikey=0df993c66c0c636e29ecbb5344252a4a |
- 使用 urllib3,获取豆瓣新书速推网页的 HTML 相应数据,在使用 bs4 库,从HTML DOM 中解析出所有新书的 id,保存到一个 list 对象中
- 遍历list:通过新书的 id,调用豆瓣单条图书查询 RESTful API,获取对应图书id的详细数据(一个 json 字符串数据,转换为 dict 对象),添加到 list 中
- 爬取完所有图书数据后,调用 json 库,把保存了图书数据的list 对象持久化到文件系统中。
-
数据预处理
对爬取到的数据简单预处理,进行数据清洗、数据变换、数据规约和数据导出过程。
数据预处理过程在Jupyter Notebook 上运行,主要使用了 Python 和 Pandas 做数据处理,内容包裹处理空值、数据格式等,最后进行数据规约、排序、分组等操作,把处理后的数据持久化到本地,供后续使用。
源码
源码包含了类型注解和注释
-
数据爬取
"""
采集豆瓣网站的新书速递图书数据
- 新书速推HTML: https://book.douban.com/latest?icn=index-latestbook-all
- 单条图书查询 RESTfulAPI: https://api.douban.com/v2/book/:id?apikey=0df993c66c0c636e29ecbb5344252a4a
"""
# from typing import Dict,List
import urllib3
from urllib3.response import HTTPResponse
from bs4 import BeautifulSoup, PageElement, ResultSet
from typing import Dict, List
import json
import datetime
__author__ = "onemsg ([email protected])"
DEFAULT_HEADERS = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) \
Chrome/83.0.4103.97 Safari/537.36 Edg/83.0.478.45"
}
def get_new_books() -> Dict[str,List[str]]:
"""
爬取页面 https://book.douban.com/latest?icn=index-latestbook-all 的图书 id
return 包含一个包含了 图书id 的 dict
"""
url = "https://book.douban.com/latest?icn=index-latestbook-all"
r: HTTPResponse = urllib3.PoolManager().request('GET', url, headers=DEFAULT_HEADERS)
bs = BeautifulSoup(r.data, features="lxml")
fiction: ResultSet[PageElement] = bs.select("#content > div > div.article > ul > li")
non_fiction: ResultSet[PageElement] = bs.select("#content > div > div.aside > ul > li")
books = {
"fiction": [],
"non_fiction": []
}
for li in fiction:
li:PageElement
id: str = li.find_next("a")["href"].split("/")[-2]
books['fiction'].append(id)
for li in non_fiction:
li: PageElement
id: str = li.find_next("a")["href"].split("/")[-2]
books['non_fiction'].append(id)
return books
def get_book_info(book_ids: List['str']) -> List[Dict]:
"""
获取一个图书id list中所有图书信息
调用API: https://api.douban.com/v2/book/:id?apikey=0df993c66c0c636e29ecbb5344252a4a
return: 一个 list[dict] 包含所有图书信息
"""
http = urllib3.PoolManager()
url_template = "https://api.douban.com/v2/book/{}?apikey=0df993c66c0c636e29ecbb5344252a4a"
books = []
for id in book_ids:
r: HTTPResponse = http.request("GET", url_template.format(id))
book = json.loads(r.data.decode("utf-8"))
books.append(book)
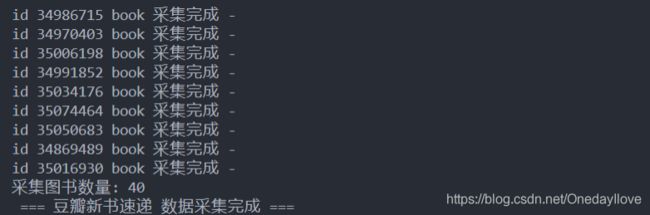
print("id {} book 采集完成 -".format(id))
return books
if __name__ == "__main__":
print(" === 豆瓣新书速递 数据采集开始 ===")
book_ids = get_new_books()
books = []
for ids in book_ids.values():
_books = get_book_info(ids)
books.extend(_books)
now = datetime.datetime.now()
date = now.strftime('%Y-%m-%d')
outpath = "data/books-{}.json".format(date)
with open(outpath, "w", encoding="utf-8") as f:
json.dump(books, f, indent=4, ensure_ascii=False)
print("采集图书数量: {}".format(len(books)))
print(" === 豆瓣新书速递 数据采集完成 ===")
-
数据预处理
Jupyter Notebook
豆瓣新书速递数据预处理
import pandas as pd
import json
from pprint import pprint
import os
print("list of ../data")
for f in os.listdir("../data"):
print("- ", f)
list of ../data
- books-2020-06-17.json
- books.json
1. 加载/预览数据
PATH = "../data/books.json"
with open(PATH, "r", encoding="utf-8") as f:
books = json.load(f)
print(" books size is ", len(books))
print(" one of books is")
pprint(books[0])
books size is 40
one of books is
{'alt': 'https://book.douban.com/subject/35040230/',
'alt_title': 'フーガはユーガ',
'author': ['[日]伊坂幸太郎'],
'author_intro': '[日]伊坂幸太郎\n'
'1971年生于日本千叶县。风格独树一帜的实力派,像奇迹般温暖的作家。\n'
'曾获得书店大奖、山本周五郎奖、新潮推理俱乐部奖等诸多奖项,并五次入围直木奖,在日本《达·芬奇》杂志“最受欢迎的作家”投票中常年与东野圭吾、村上春树竞争头名。作品曾多次被改编成影视剧,其中堺雅人主演的《金色梦乡》更是火遍亚洲。\n'
'他虽然常描写陷入巨大困境的小人物,却总能凭出色的幽默感和精妙设计的反转,让读者感受到温暖与希望。\n'
'另著有:《余生皆假期》《家鸭与野鸭的投币式寄物柜》《一个人办不到》《没关系,是伊坂啊!伊坂幸太郎3652日随笔集》等。\n'
'~~~~~~~~~~\n'
'代珂\n'
'1985年生。文学博士,现任教于日本东京都立大学人文社会系。曾译有伊坂幸太郎、东野圭吾、三岛由纪夫等作家作品多部。',
'binding': '平装',
'catalog': '',
'ebook_price': '24.00',
'ebook_url': 'https://read.douban.com/ebook/148955035/',
'id': '35040230',
'image': 'https://img1.doubanio.com/view/subject/m/public/s33640048.jpg',
'images': {'large': 'https://img1.doubanio.com/view/subject/l/public/s33640048.jpg',
'medium': 'https://img1.doubanio.com/view/subject/m/public/s33640048.jpg',
'small': 'https://img1.doubanio.com/view/subject/s/public/s33640048.jpg'},
'isbn10': '7559637299',
'isbn13': '9787559637291',
'origin_title': 'フーガはユーガ',
'pages': '280',
'price': '48.00元',
'pubdate': '2020-6',
'publisher': '北京联合出版公司',
'rating': {'average': '7.6', 'max': 10, 'min': 0, 'numRaters': 152},
'series': {'id': '52223', 'title': '磨铁·伊坂幸太郎作品'},
'subtitle': '',
'summary': '“如果人生有奖项,即便得不到一等奖,我们至少也配得上一个参与奖、鼓励奖什么的。”\n'
'五岁生日那天,我和我的双胞胎弟弟获得了三样东西:\n'
'父亲一如既往的暴力、母亲为求自保的熟视无睹,以及一种超能力:\n'
'生日当天,我们兄弟两人每隔两小时就会被动地“瞬间移动”,互相调换位置。\n'
'生活在可怕的家庭,拥有可笑的超能力……\n'
'即便如此可悲的我们,也有可以拯救的人吗?\n'
'伊坂幸太郎:“(写这本书时)我想找回《家鸭野鸭》时那种‘读时悲伤寂寞,读后却倍感温柔’的感觉。”\n'
'「再弱小的人,也有可以守护的东西,\n'
'再烂的人生,也能找到活下去的希望。」\n'
'☆☆☆☆☆☆☆☆☆\n'
'爱与痛的会心一击,\n'
'双倍于《金色梦乡》的苦难与救赎。\n'
'伊坂幸太郎长篇小说新作首次引进\n'
'伊坂近三年唯一正统长篇小说,\n'
'简体中文版首次引进。\n'
'(甚至比繁体版还早出版!)\n'
'“日本豆瓣”上市首月起连续霸榜11个月❗\n'
'毫无意外入围2019书店大奖❗❗\n'
'连伊坂自己都惊讶的故事设定\n'
'“我自己也奇怪,之前写的都是只脱离地表(实际)几厘米的故事,这次怎么直接飞起来了?”——伊坂幸太郎\n'
'收获读者一致认可的回归初心之作\n'
'读者走心评论:不可思议、善良、悲伤、浪漫。\n'
'“日本豆瓣”数据成倍超越伊坂近期其他作品。\n'
'伊坂自述:“我想找回《家鸭野鸭》时那种‘读时悲伤寂寞,读后却倍感温柔’的感觉。”\n'
'我们都爱伊坂幸太郎,一个奇迹般温暖的作家\n'
'“日本豆瓣”作家榜首位,\n'
'《达·芬奇》杂志“最受欢迎的作家”投票常年与东野圭吾、村上春树竞争头名。\n'
'东野圭吾:比起“写什么”,伊坂将更多的写作个性倾注到了“怎么写”上面。他的文字总有一种独特的韵律感。',
'tags': [{'count': 116, 'name': '伊坂幸太郎', 'title': '伊坂幸太郎'},
{'count': 44, 'name': '小说', 'title': '小说'},
{'count': 37, 'name': '日本', 'title': '日本'},
{'count': 35, 'name': '日本文学', 'title': '日本文学'},
{'count': 24, 'name': '推理', 'title': '推理'},
{'count': 15, 'name': '日系推理', 'title': '日系推理'},
{'count': 15, 'name': '推理小说', 'title': '推理小说'},
{'count': 14, 'name': '日本推理', 'title': '日本推理'}],
'title': '双子星',
'translator': ['代珂'],
'url': 'https://api.douban.com/v2/book/35040230'}
books_df = pd.DataFrame(data=books)
books_df.head(2)
| rating | subtitle | author | pubdate | tags | origin_title | image | binding | translator | catalog | ... | isbn10 | isbn13 | title | url | alt_title | author_intro | summary | ebook_price | series | price | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | {'max': 10, 'numRaters': 152, 'average': '7.6'... | [[日]伊坂幸太郎] | 2020-6 | [{'count': 116, 'name': '伊坂幸太郎', 'title': '伊坂幸... | フーガはユーガ | https://img1.doubanio.com/view/subject/m/publi... | 平装 | [代珂] | ... | 7559637299 | 9787559637291 | 双子星 | https://api.douban.com/v2/book/35040230 | フーガはユーガ | [日]伊坂幸太郎\n1971年生于日本千叶县。风格独树一帜的实力派,像奇迹般温暖的作家。\n... | “如果人生有奖项,即便得不到一等奖,我们至少也配得上一个参与奖、鼓励奖什么的。”\n五岁生... | 24.00 | {'id': '52223', 'title': '磨铁·伊坂幸太郎作品'} | 48.00元 | ||
| 1 | {'max': 10, 'numRaters': 100, 'average': '7.9'... | [[日]多利安助川] | 2020-5 | [{'count': 28, 'name': '日本文学', 'title': '日本文学'... | あん | https://img1.doubanio.com/view/subject/m/publi... | 平装 | [吕卫清] | ... | 7533958500 | 9787533958503 | 铜锣烧也有春天 | https://api.douban.com/v2/book/34852472 | あん | 作者简介\n多利安助川Dorian Sukegawa\n(1962—)\n日本作家、诗人、歌... | 日本“铜锣烧式”人气治愈小说\n日本电影《澄沙之味》原著小说\n2017年法国“文库本读者奖... | 14.99 | NaN | 38.00元 |
2 rows × 26 columns
2. 数据清洗
- 处理缺失值
books_df.info()
RangeIndex: 40 entries, 0 to 39
Data columns (total 26 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 rating 40 non-null object
1 subtitle 40 non-null object
2 author 40 non-null object
3 pubdate 40 non-null object
4 tags 40 non-null object
5 origin_title 40 non-null object
6 image 40 non-null object
7 binding 40 non-null object
8 translator 40 non-null object
9 catalog 40 non-null object
10 ebook_url 9 non-null object
11 pages 40 non-null object
12 images 40 non-null object
13 alt 40 non-null object
14 id 40 non-null object
15 publisher 40 non-null object
16 isbn10 40 non-null object
17 isbn13 40 non-null object
18 title 40 non-null object
19 url 40 non-null object
20 alt_title 40 non-null object
21 author_intro 40 non-null object
22 summary 40 non-null object
23 ebook_price 9 non-null object
24 series 23 non-null object
25 price 40 non-null object
dtypes: object(26)
memory usage: 8.2+ KB
na_handler = {
"ebook_url": "",
"ebook_price": "",
}
books_df = books_df.fillna(value=na_handler)
books_df['series'] = books_df['series'].map(lambda s: {} if pd.isna(s) else s)
books_df.info()
RangeIndex: 40 entries, 0 to 39
Data columns (total 26 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 rating 40 non-null object
1 subtitle 40 non-null object
2 author 40 non-null object
3 pubdate 40 non-null object
4 tags 40 non-null object
5 origin_title 40 non-null object
6 image 40 non-null object
7 binding 40 non-null object
8 translator 40 non-null object
9 catalog 40 non-null object
10 ebook_url 40 non-null object
11 pages 40 non-null object
12 images 40 non-null object
13 alt 40 non-null object
14 id 40 non-null object
15 publisher 40 non-null object
16 isbn10 40 non-null object
17 isbn13 40 non-null object
18 title 40 non-null object
19 url 40 non-null object
20 alt_title 40 non-null object
21 author_intro 40 non-null object
22 summary 40 non-null object
23 ebook_price 40 non-null object
24 series 40 non-null object
25 price 40 non-null object
dtypes: object(26)
memory usage: 8.2+ KB
3. 数据变换
price由 str 变换为 floatebook_price由 str 变换为 float- 由
rating新建属性rating-average、rating-numRaters - 由
series新建属性series-title author由 list[str] 变换为 strtranslator由 list[str] 变换为 strtags由 list[dict] 变换为 str
for col in books_df.columns:
print()
o = books_df[col][0]
print(" {}: {}".format(col, type(o)))
pprint(o)
rating:
{'average': '7.6', 'max': 10, 'min': 0, 'numRaters': 152}
subtitle:
''
author:
['[日]伊坂幸太郎']
pubdate:
'2020-6'
tags:
[{'count': 116, 'name': '伊坂幸太郎', 'title': '伊坂幸太郎'},
{'count': 44, 'name': '小说', 'title': '小说'},
{'count': 37, 'name': '日本', 'title': '日本'},
{'count': 35, 'name': '日本文学', 'title': '日本文学'},
{'count': 24, 'name': '推理', 'title': '推理'},
{'count': 15, 'name': '日系推理', 'title': '日系推理'},
{'count': 15, 'name': '推理小说', 'title': '推理小说'},
{'count': 14, 'name': '日本推理', 'title': '日本推理'}]
origin_title:
'フーガはユーガ'
image:
'https://img1.doubanio.com/view/subject/m/public/s33640048.jpg'
binding:
'平装'
translator:
['代珂']
catalog:
''
ebook_url:
'https://read.douban.com/ebook/148955035/'
pages:
'280'
images:
{'large': 'https://img1.doubanio.com/view/subject/l/public/s33640048.jpg',
'medium': 'https://img1.doubanio.com/view/subject/m/public/s33640048.jpg',
'small': 'https://img1.doubanio.com/view/subject/s/public/s33640048.jpg'}
alt:
'https://book.douban.com/subject/35040230/'
id:
'35040230'
publisher:
'北京联合出版公司'
isbn10:
'7559637299'
isbn13:
'9787559637291'
title:
'双子星'
url:
'https://api.douban.com/v2/book/35040230'
alt_title:
'フーガはユーガ'
author_intro:
('[日]伊坂幸太郎\n'
'1971年生于日本千叶县。风格独树一帜的实力派,像奇迹般温暖的作家。\n'
'曾获得书店大奖、山本周五郎奖、新潮推理俱乐部奖等诸多奖项,并五次入围直木奖,在日本《达·芬奇》杂志“最受欢迎的作家”投票中常年与东野圭吾、村上春树竞争头名。作品曾多次被改编成影视剧,其中堺雅人主演的《金色梦乡》更是火遍亚洲。\n'
'他虽然常描写陷入巨大困境的小人物,却总能凭出色的幽默感和精妙设计的反转,让读者感受到温暖与希望。\n'
'另著有:《余生皆假期》《家鸭与野鸭的投币式寄物柜》《一个人办不到》《没关系,是伊坂啊!伊坂幸太郎3652日随笔集》等。\n'
'~~~~~~~~~~\n'
'代珂\n'
'1985年生。文学博士,现任教于日本东京都立大学人文社会系。曾译有伊坂幸太郎、东野圭吾、三岛由纪夫等作家作品多部。')
summary:
('“如果人生有奖项,即便得不到一等奖,我们至少也配得上一个参与奖、鼓励奖什么的。”\n'
'五岁生日那天,我和我的双胞胎弟弟获得了三样东西:\n'
'父亲一如既往的暴力、母亲为求自保的熟视无睹,以及一种超能力:\n'
'生日当天,我们兄弟两人每隔两小时就会被动地“瞬间移动”,互相调换位置。\n'
'生活在可怕的家庭,拥有可笑的超能力……\n'
'即便如此可悲的我们,也有可以拯救的人吗?\n'
'伊坂幸太郎:“(写这本书时)我想找回《家鸭野鸭》时那种‘读时悲伤寂寞,读后却倍感温柔’的感觉。”\n'
'「再弱小的人,也有可以守护的东西,\n'
'再烂的人生,也能找到活下去的希望。」\n'
'☆☆☆☆☆☆☆☆☆\n'
'爱与痛的会心一击,\n'
'双倍于《金色梦乡》的苦难与救赎。\n'
'伊坂幸太郎长篇小说新作首次引进\n'
'伊坂近三年唯一正统长篇小说,\n'
'简体中文版首次引进。\n'
'(甚至比繁体版还早出版!)\n'
'“日本豆瓣”上市首月起连续霸榜11个月❗\n'
'毫无意外入围2019书店大奖❗❗\n'
'连伊坂自己都惊讶的故事设定\n'
'“我自己也奇怪,之前写的都是只脱离地表(实际)几厘米的故事,这次怎么直接飞起来了?”——伊坂幸太郎\n'
'收获读者一致认可的回归初心之作\n'
'读者走心评论:不可思议、善良、悲伤、浪漫。\n'
'“日本豆瓣”数据成倍超越伊坂近期其他作品。\n'
'伊坂自述:“我想找回《家鸭野鸭》时那种‘读时悲伤寂寞,读后却倍感温柔’的感觉。”\n'
'我们都爱伊坂幸太郎,一个奇迹般温暖的作家\n'
'“日本豆瓣”作家榜首位,\n'
'《达·芬奇》杂志“最受欢迎的作家”投票常年与东野圭吾、村上春树竞争头名。\n'
'东野圭吾:比起“写什么”,伊坂将更多的写作个性倾注到了“怎么写”上面。他的文字总有一种独特的韵律感。')
ebook_price:
'24.00'
series:
{'id': '52223', 'title': '磨铁·伊坂幸太郎作品'}
price:
'48.00元'
"""
price 由 str 变换为 float
"""
# 查看所有 price
print("price of all books, {} size".format(len(books_df['price'].values)))
print(books_df['price'].values)
price_handler = lambda s: float(s) if not s.endswith("元") else float(s[:-1])
books_df['price'] = books_df['price'].map(price_handler)
print("after transformation")
print(books_df['price'].values)
price of all books, 40 size
['48.00元' '38.00元' '45.00元' '49' '68.00' '46.00' '65.00' '48.00元' '56.00元'
'48.00元' '56.00' '48' '45.00元' '48.00' '68.00' '128' '168.00元' '55.00元'
'58.00元' '42.00元' '52' '258.00元' '390.00元' '84' '102.00元' '68' '45'
'42.00元' '49' '88.00元' '39.80元' '88.00' '49.00' '128.00元' '78.00元'
'32.00' '38.00元' '79.00元' '45' '68.00']
after transformation
[ 48. 38. 45. 49. 68. 46. 65. 48. 56. 48. 56. 48.
45. 48. 68. 128. 168. 55. 58. 42. 52. 258. 390. 84.
102. 68. 45. 42. 49. 88. 39.8 88. 49. 128. 78. 32.
38. 79. 45. 68. ]
"""
ebook_price 由 str 变换为 float
"""
# 查看所有 ebook_price
print("price of all books, {} size".format(len(books_df['ebook_price'].values)))
print(books_df['ebook_price'].values)
ebook_price_handler = lambda s: float(s) if s!="" else None
books_df['ebook_price'] = books_df['ebook_price'].map(ebook_price_handler)
print("after transformation")
print(books_df['ebook_price'].values)
price of all books, 40 size
['24.00' '14.99' '' '' '46.99' '' '39.99' '' '59.90' '' '' '' '' '' '' ''
'35.00' '' '' '' '' '' '' '' '' '' '' '' '32.99' '' '' '' '32.99' '' ''
'' '' '' '36.00' '']
after transformation
[24. 14.99 nan nan 46.99 nan 39.99 nan 59.9 nan nan nan
nan nan nan nan 35. nan nan nan nan nan nan nan
nan nan nan nan 32.99 nan nan nan 32.99 nan nan nan
nan nan 36. nan]
"""
- 由 rating 新建属性 rating-average、rating-numRaters
- 由 series 新建属性 series-title
"""
books_df['rating-average'] = books_df['rating'].map(lambda rating: rating['average'])
books_df['rating-numRaters'] = books_df['rating'].map(lambda rating: rating['numRaters'])
books_df['series-title'] = books_df['series'].map(lambda series: series.get('title', "") )
books_df[['title', 'rating-average', 'rating-numRaters', 'series-title']].head()
| title | rating-average | rating-numRaters | series-title | |
|---|---|---|---|---|
| 0 | 双子星 | 7.6 | 152 | 磨铁·伊坂幸太郎作品 |
| 1 | 铜锣烧也有春天 | 7.9 | 100 | |
| 2 | 海鸥墓园 | 6.0 | 13 | |
| 3 | 不语 | 8.2 | 20 | 杰西·鲍尔 作品 |
| 4 | 图案人 | 8.8 | 16 | 雷·布拉德伯里作品(精装纪念版) |
"""
- author 由 list[str] 变换为 str
- translator 由 list[str] 变换为 str
"""
books_df['author'] = books_df['author'].map(lambda ls: ",".join(ls))
books_df['translator'] = books_df['translator'].map(lambda ls: ",".join(ls))
books_df[['title', 'author', 'translator']].head()
| title | author | translator | |
|---|---|---|---|
| 0 | 双子星 | [日]伊坂幸太郎 | 代珂 |
| 1 | 铜锣烧也有春天 | [日]多利安助川 | 吕卫清 |
| 2 | 海鸥墓园 | 郑然 | |
| 3 | 不语 | [美]杰西·鲍尔 | 熊亭玉 |
| 4 | 图案人 | [美] 雷·布拉德伯里 | 宋怡秋 |
"""
tags 由 list[dict] 变换为 str
"""
books_df['tags'] = books_df['tags'].map(lambda ls: ",".join([tag['name'] for tag in ls]) )
books_df[['title', 'tags']].head()
| title | tags | |
|---|---|---|
| 0 | 双子星 | 伊坂幸太郎,小说,日本,日本文学,推理,日系推理,推理小说,日本推理 |
| 1 | 铜锣烧也有春天 | 日本文学,日本,小说,长篇小说,2020,澄沙之味,电影原著,蔬菜库存 |
| 2 | 海鸥墓园 | 小说,后浪文学,文学,中国文学,郑然,短篇小说,后浪,未知 |
| 3 | 不语 | 小说,推理,美国文学,美国,虚构,*北京·中信出版社*,杰西鲍尔,未知 |
| 4 | 图案人 | 科幻,雷·布拉德伯里,短篇集,小说,美国文学,美国,雷·布拉德伯里作品(精装纪念版),文学 |
4. 数据规约与数据导出
- 导出变换后的图书数据到
output/books.csv - 按评分排序图书,导出基本数据到
output/books_ranking.csv - 按图书价格排序图书,导出基本数据到
output/books_order_by_price.csv - 按图书出版日期排序,导出基本数据到
output/books_order_by_pubdate.csv - 按作者国家分类图书,导出原数据到
output/books_group_by_author_country.json
for col in books_df.columns:
print()
o = books_df[col][0]
print(" {}: {}".format(col, type(o)))
pprint(o)
rating:
{'average': '7.6', 'max': 10, 'min': 0, 'numRaters': 152}
subtitle:
''
author:
'[日]伊坂幸太郎'
pubdate:
'2020-6'
tags:
'伊坂幸太郎,小说,日本,日本文学,推理,日系推理,推理小说,日本推理'
origin_title:
'フーガはユーガ'
image:
'https://img1.doubanio.com/view/subject/m/public/s33640048.jpg'
binding:
'平装'
translator:
'代珂'
catalog:
''
ebook_url:
'https://read.douban.com/ebook/148955035/'
pages:
'280'
images:
{'large': 'https://img1.doubanio.com/view/subject/l/public/s33640048.jpg',
'medium': 'https://img1.doubanio.com/view/subject/m/public/s33640048.jpg',
'small': 'https://img1.doubanio.com/view/subject/s/public/s33640048.jpg'}
alt:
'https://book.douban.com/subject/35040230/'
id:
'35040230'
publisher:
'北京联合出版公司'
isbn10:
'7559637299'
isbn13:
'9787559637291'
title:
'双子星'
url:
'https://api.douban.com/v2/book/35040230'
alt_title:
'フーガはユーガ'
author_intro:
('[日]伊坂幸太郎\n'
'1971年生于日本千叶县。风格独树一帜的实力派,像奇迹般温暖的作家。\n'
'曾获得书店大奖、山本周五郎奖、新潮推理俱乐部奖等诸多奖项,并五次入围直木奖,在日本《达·芬奇》杂志“最受欢迎的作家”投票中常年与东野圭吾、村上春树竞争头名。作品曾多次被改编成影视剧,其中堺雅人主演的《金色梦乡》更是火遍亚洲。\n'
'他虽然常描写陷入巨大困境的小人物,却总能凭出色的幽默感和精妙设计的反转,让读者感受到温暖与希望。\n'
'另著有:《余生皆假期》《家鸭与野鸭的投币式寄物柜》《一个人办不到》《没关系,是伊坂啊!伊坂幸太郎3652日随笔集》等。\n'
'~~~~~~~~~~\n'
'代珂\n'
'1985年生。文学博士,现任教于日本东京都立大学人文社会系。曾译有伊坂幸太郎、东野圭吾、三岛由纪夫等作家作品多部。')
summary:
('“如果人生有奖项,即便得不到一等奖,我们至少也配得上一个参与奖、鼓励奖什么的。”\n'
'五岁生日那天,我和我的双胞胎弟弟获得了三样东西:\n'
'父亲一如既往的暴力、母亲为求自保的熟视无睹,以及一种超能力:\n'
'生日当天,我们兄弟两人每隔两小时就会被动地“瞬间移动”,互相调换位置。\n'
'生活在可怕的家庭,拥有可笑的超能力……\n'
'即便如此可悲的我们,也有可以拯救的人吗?\n'
'伊坂幸太郎:“(写这本书时)我想找回《家鸭野鸭》时那种‘读时悲伤寂寞,读后却倍感温柔’的感觉。”\n'
'「再弱小的人,也有可以守护的东西,\n'
'再烂的人生,也能找到活下去的希望。」\n'
'☆☆☆☆☆☆☆☆☆\n'
'爱与痛的会心一击,\n'
'双倍于《金色梦乡》的苦难与救赎。\n'
'伊坂幸太郎长篇小说新作首次引进\n'
'伊坂近三年唯一正统长篇小说,\n'
'简体中文版首次引进。\n'
'(甚至比繁体版还早出版!)\n'
'“日本豆瓣”上市首月起连续霸榜11个月❗\n'
'毫无意外入围2019书店大奖❗❗\n'
'连伊坂自己都惊讶的故事设定\n'
'“我自己也奇怪,之前写的都是只脱离地表(实际)几厘米的故事,这次怎么直接飞起来了?”——伊坂幸太郎\n'
'收获读者一致认可的回归初心之作\n'
'读者走心评论:不可思议、善良、悲伤、浪漫。\n'
'“日本豆瓣”数据成倍超越伊坂近期其他作品。\n'
'伊坂自述:“我想找回《家鸭野鸭》时那种‘读时悲伤寂寞,读后却倍感温柔’的感觉。”\n'
'我们都爱伊坂幸太郎,一个奇迹般温暖的作家\n'
'“日本豆瓣”作家榜首位,\n'
'《达·芬奇》杂志“最受欢迎的作家”投票常年与东野圭吾、村上春树竞争头名。\n'
'东野圭吾:比起“写什么”,伊坂将更多的写作个性倾注到了“怎么写”上面。他的文字总有一种独特的韵律感。')
ebook_price:
24.0
series:
{'id': '52223', 'title': '磨铁·伊坂幸太郎作品'}
price:
48.0
rating-average:
'7.6'
rating-numRaters:
152
series-title:
'磨铁·伊坂幸太郎作品'
# 导出变换后的图书数据到 output/books.csv, 没有 dict 结构
csv_cols = ['title', 'subtitle', 'author', 'pubdate', 'tags', 'origin_title', 'binding', 'translator', 'catalog', 'ebook_url', 'pages', 'alt', 'id', 'publisher', 'isbn10', 'isbn13', 'url', 'alt_title', 'author_intro', 'summary', 'ebook_price', 'price', 'rating-average', 'rating-numRaters', 'series-title']
OUTPATH = "../output/books.csv"
books_df[csv_cols].to_csv(OUTPATH, index=False, encoding="utf-8")
print("list of ../output: {}".format(os.listdir("../output")))
list of ../output: ['books.csv']
# 按评分排序图书,导出基本数据到 output/books_ranking.csv
OUTPATH = "../output/books_ranking.csv"
books_df[csv_cols].sort_values(by='rating-average', ascending=False)\
.reset_index(drop=True).to_csv(OUTPATH, encoding="utf-8" )
print("list of ../output: {}".format(os.listdir("../output")))
list of ../output: ['books.csv', 'books_ranking.csv']
# 按图书价格排序图书,导出基本数据到 output/books_order_by_price.csv
OUTPATH = "../output/books_order_by_price.csv"
books_df[csv_cols].sort_values(by='price', ascending=False)\
.reset_index(drop=True).to_csv(OUTPATH, encoding="utf-8" )
# 按图书出版日期排序,导出基本数据到 output/books_order_by_pubdate.csv
OUTPATH = "../output/books_order_by_pubdate.csv"
books_df[csv_cols].sort_values(by='pubdate', ascending=False)\
.reset_index(drop=True).to_csv(OUTPATH, encoding="utf-8" )
print("list of ../output:\n{}".format(os.listdir("../output")))
list of ../output:
['books.csv', 'books_order_by_price.csv', 'books_order_by_pubdate.csv', 'books_ranking.csv']
books_df['author']
0 [日]伊坂幸太郎
1 [日]多利安助川
2 郑然
3 [美]杰西·鲍尔
4 [美] 雷·布拉德伯里
5 [以色列]埃特加·凯雷特,[以色列]塔米·巴扎雷利
6 [意] 加布里埃莱·邓南遮
7 张贵兴
8 [美] 杰克·凯鲁亚克
9 [日] 西泽保彦
10 甫跃辉
11 [意] 翁贝托·埃科,欧金尼奥·卡尔米 绘
12 [阿根廷] 胡里奥·科塔萨尔
13 [日] 村上龙
14 骆以军
15 【比利时】雨果·克劳斯
16 (古希腊) 索福克勒斯
17 西西
18 西西
19 〔匈〕特雷西娅•莫拉,Terézia Mora
20 吴琦 主编
21 【法】米歇尔·帕斯图罗 著
22 [日]秋山亮二
23 [美]威廉·瑞迪
24 [美] 伊布拉姆·X.肯尼
25 [美] 马特·里克特
26 (美) 特雷西·基德尔 (Tracy Kidder),(美) 理查德·托德 (Richar...
27 [法]伊曼努尔·列维纳斯
28 [美] 理查德 ·普雷斯顿
29 [英] 菲利普·桑兹
30 美国旧金山写作社,San Francisco Writers’ Grotto
31 赵冬梅
32 [美]蒂莫西·伊根(Timothy Egan)
33 张云
34 席路德
35 [波兰]亚当·扎加耶夫斯基
36 杨本芬
37 [美]乔丽·格雷厄姆(Jorie Graham)
38 北溟鱼
39 [美] 琼·贝兹
Name: author, dtype: object
# 按作者国家分类图书,导出原数据到 output/books_group_by_author_country.json
import re
country_map = {
'美': '美国',
'日': '日本',
'法': '法国',
'意': '意大利',
'英': '英国',
'匈': '匈牙利'
}
def get_author_country(book: dict) -> str:
author: str = book['author'][0]
m = re.search('[\[【\(\〔].+[\]】\)\〕]', author[:-1])
if m == None:
country = "中国"
else:
country = m.group(0)[1:-1]
country = country_map.get(country, country)
if '美国' in author:
country = '美国'
return country
books_group_by_author_country = {}
for book in books:
country = get_author_country(book)
if country not in books_group_by_author_country:
books_group_by_author_country[country] = []
books_group_by_author_country[country].append(book)
print(books_group_by_author_country.keys())
OUTPATH = "../output/books_group_by_author_country.json"
with open(OUTPATH, 'w', encoding='utf-8') as f:
json.dump(books_group_by_author_country, f, ensure_ascii=False, indent=4)
print("list of ../output:\n{}".format(os.listdir("../output")))
dict_keys(['日本', '中国', '美国', '以色列', '意大利', '阿根廷', '比利时', '古希腊', '匈牙利', '法国', '英国', '波兰'])
list of ../output:
['books.csv', 'books_group_by_author_country.json', 'books_order_by_price.csv', 'books_order_by_pubdate.csv', 'books_ranking.csv']