mysql默认空列的弊端
概括:
- null列在查询的时候容易照成误解
- null列在使用count的时候必须要多注意
- null作为索引需要更多空间,让索引变得复杂
环境介绍
创建两张表
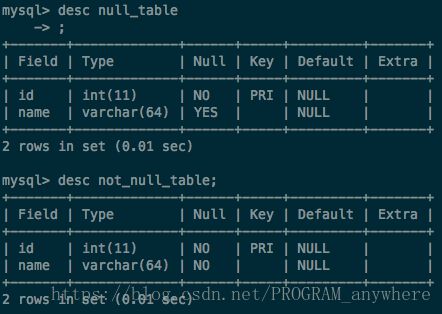
两张表里面数据一样,一共1000条记录,一条name=1
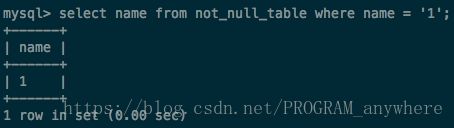
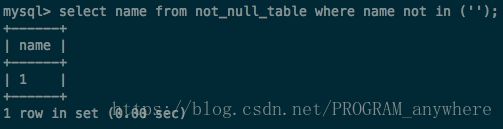
问题一
现在有个需求是查询表中所有name不等于1的id
![]()
999条数据没有被查出来(按理说null != 1么?答案肯定是不等于,但实际结果是这条记录被忽略)
上面这种情况如果复杂化,不是单表查询,几张表连着一起查询,就有可能比较难以发现问题。
![]()
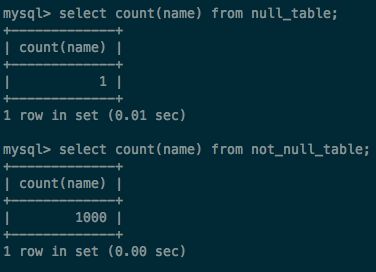
问题二
count在计算null的时候不会记录这条数据
问题三
有很多会认为null值可能不需要消耗空间,实际上是错误的,空和空字符串是两码事,我没有研究过源码,但是很容易想到的是,mysql一定需要标记这个空字段,既然需要标记,那么就需要空间。
下面是我做的一个小小测试:
1. [1254,939,933,975,902,949,876,877,906,937,954]
2. [1038,1061,923,969,899,868,893,885,894,901,933]
3. [1000,865,882,831,815,964,986,1247,883,986,945]
4. [1108,967,861,964,893,861,851,837,838,866,904]
第1、3行是对null_table进行查询,每次查询1000条数据,一共查询10次,最后那个数字是平均值
第2、4行同理
看样子是非空表的确稍微快一点,但不排除可能还有外部因素影响
如果该字段加一个索引
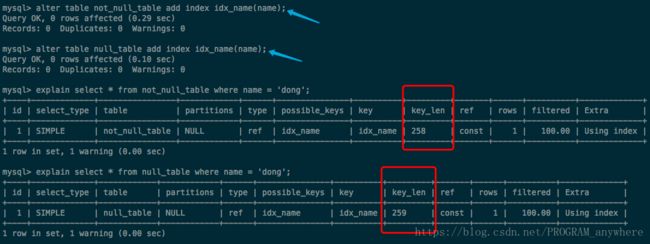
可以看出not_null_table的索引key_len=258
null_table的索引key_len=259
说一下这个key_len的计算

可以看出他们的编码用的都是utf8mb4(占四个字节)
258 = 64 * 4 + 2
259 = 64 * 4 + 2 + 1
这个2是因为存储 varchar变长字符需要2字节,定长不需要这2个字节
可以看出来还需要1个字节特殊标记,这样索引占的内存就大了,而且索引的设计会更复杂,查询时间会变长。