sharding-jdbc水平分库与垂直分库
前言
在上一篇中,我们见到介绍了sharding-jdbc的基本概念和使用,了解了其基本原理,在sharding-jdbc中存在水平分库与垂直分库的概念,从业务意义上讲,分库的目的是为了缓解单台服务器查询的压力,但在实践过程中,存在水平分库和垂直分库两种模式可供选择
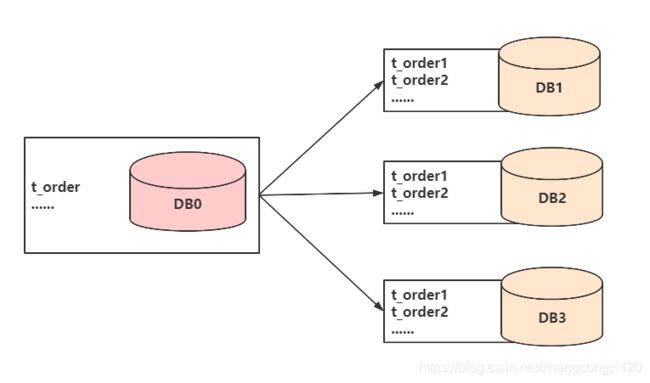
水平分库
水平分库是把同一个表的数据按一定规则拆到不同的数据库中,每个库可以放在不同的服务器 上,具体要将一张表拆分成多少张表,最好提前评估一下单表的数据量以及每张表预计承载的数量
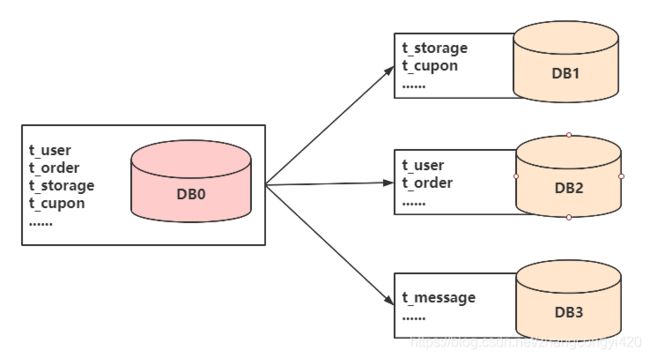
垂直分库
垂直分库是指按照业务将表进行分类,分布到不同的数据库上面,每个库可以放在不同的服务器 上,它的核心理念是专库专用,这个可以类比微服务中各个服务使用自己独立的库
水平分库代码整合与测试
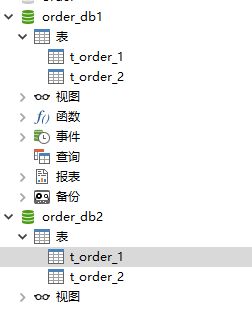
1、创建两个数据库
按照上面的图示,这里我们需要提前创建两个库,分别是order_db1和order_db2,每个库中存在两个表,t_order_1和t_order_2
测试建表sql
CREATE TABLE `t_order_1` (
`order_id` bigint(32) NOT NULL,
`price` decimal(10,2) NOT NULL,
`user_id` bigint(32) NOT NULL,
`status` varchar(32) DEFAULT NULL,
PRIMARY KEY (`order_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
2、导入依赖
org.springframework.boot
spring-boot-starter-parent
2.1.5.RELEASE
UTF-8
UTF-8
1.8
2.9.2
1.1.16
org.springframework.boot
spring-boot-starter-web
org.springframework.boot
spring-boot-starter-test
test
mysql
mysql-connector-java
5.1.47
org.apache.shardingsphere
sharding-jdbc-spring-boot-starter
4.0.0-RC1
org.mybatis.spring.boot
mybatis-spring-boot-starter
2.0.0
com.alibaba
druid-spring-boot-starter
${druid.version}
io.springfox
springfox-swagger2
${swagger.version}
io.springfox
springfox-swagger-ui
${swagger.version}
com.google.guava
guava
20.0
org.springframework.boot
spring-boot-maven-plugin
3、配置分片、分库策略
本文的配置方式都在配置文件中完成,也可以选择使用编码方式配置
server.port=8087
spring.application.name=sharding-jdbc
spring.main.allow-bean-definition-overriding=true
#mybatis配置
mybatis.type-aliases-package=com.congge.entity
mybatis.mapper-locations=classpath:mybatis/*.xml
mybatis.configuration.map-underscore-to-camel-case=true
#配置sql输出
logging.level.root=info
logging.level.org.springframework.web=info
logging.level.com.congge.mapper=debug
logging.level.druid.sql=debug
#定义分库规则
spring.shardingsphere.datasource.names=db1,db2
#数据库1的配置
spring.shardingsphere.datasource.db1.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.db1.driver-class-name=com.mysql.jdbc.Driver
spring.shardingsphere.datasource.db1.url=jdbc:mysql://106.15.37.145:3306/order_db1?useUnicode=true&characterEncoding=utf-8
spring.shardingsphere.datasource.db1.username=root
spring.shardingsphere.datasource.db1.password=123456
#数据库2的配置
spring.shardingsphere.datasource.db2.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.db2.driver-class-name=com.mysql.jdbc.Driver
spring.shardingsphere.datasource.db2.url=jdbc:mysql://106.15.37.145:3306/order_db2?useUnicode=true&characterEncoding=utf-8
spring.shardingsphere.datasource.db2.username=root
spring.shardingsphere.datasource.db2.password=123456
# ******************************* 分库策略开始 *******************************
spring.shardingsphere.sharding.tables.t_order.database-strategy.inline.sharding-column=user_id
spring.shardingsphere.sharding.tables.t_order.database-strategy.inline.algorithm-expression=db$->{user_id % 2 + 1}
# ******************************* 分库策略结束 *******************************
# ******************************* 分表策略开始 *******************************
#指定t_order表的数据分布状况,配置数据节点
spring.shardingsphere.sharding.tables.t_order.actual-data-nodes=db$->{1..2}.t_order_$->{1..2}
#指定t_order表的配置主键生成策略SNOWFLAKE
spring.shardingsphere.sharding.tables.t_order.key-generator.column=order_id
spring.shardingsphere.sharding.tables.t_order.key-generator.type=SNOWFLAKE
#指定t_order表的分片策略,包括分片键和分片算法
spring.shardingsphere.sharding.tables.t_order.table-strategy.inline.sharding-column=order_id
spring.shardingsphere.sharding.tables.t_order.table-strategy.inline.algorithm-expression=t_order_$->{order_id % 2 + 1}
# ******************************* 分表策略结束 *******************************
#打开sql输出日志
spring.shardingsphere.props.sql.show=true
关于配置文件有几点需要注意:
- 配置分库策略,表示查询数据的时候,sharding-jdbc要按照你的策略能找到要查询的库
- 配置分表策略,表示查询数据的时候,当sharding-jdbc定位到具体的库之后,能够在当前库中按照你的分表策略定位到具体是查询那张表的数据,比如这里的t_order_1还是t_order_2表
在这里,我们简单普及一下sharding-jdbc在执行一次查询时的底层执行过程原理,如下图所示
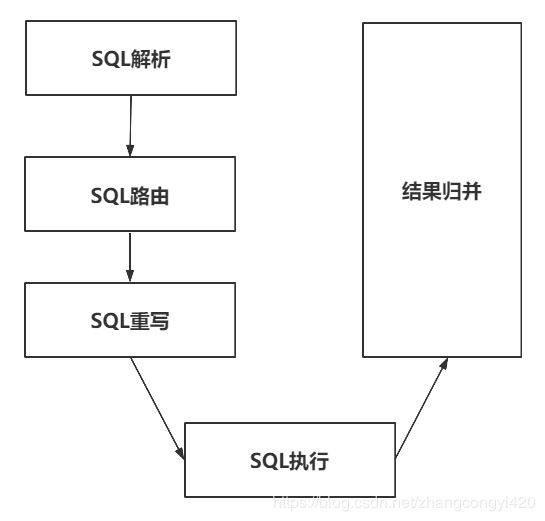
当Sharding-JDBC接受到一条SQL语句时,会陆续执行 SQL解析 => 查询优化 => SQL路由 => SQL改写 => SQL执行 => 结果归并 ,最终返回执行结果
SQL解析
SQL解析过程分为词法解析和语法解析。 词法解析器用于将SQL拆解为不可再分的原子符号,称为Token。并根据 不同数据库方言所提供的字典,将其归类为关键字,表达式,字面量和操作符。 再使用语法解析器将SQL转换为抽 象语法树。
SQL路由
SQL路由就是把针对逻辑表的数据操作映射到对数据结点操作的过程,比如我们数据库中保存的表是t_order_1和t_order_2,但是我们在上面的配置文件中写的是t_order,这个t_order表就是一个逻辑表,sharding-jdbc在执行的时候会根据路由规则进行逻辑表到真实表的映射
根据解析上下文匹配数据库和表的分片策略,并生成路由路径。 对于携带分片键的SQL,根据分片键操作符不同可 以划分为单片路由(分片键的操作符是等号)、多片路由(分片键的操作符是IN)和范围路由(分片键的操作符是 BETWEEN),不携带分片键的SQL则采用广播路由。根据分片键进行路由的场景可分为直接路由、标准路由、笛卡 尔路由等。
SQL改写
开发人员面向逻辑表书写的SQL,并不能够直接在真实的数据库中执行,SQL改写用于将逻辑SQL改写为在真实数据 库中可以正确执行的SQL,例如上面查询一个order的sql,逻辑上的查询语句如下:
SELECT order_id FROM t_order WHERE order_id=1;
假设该SQL配置分片键order_id,并且order_id=1的情况,将路由至分片表1。那么改写之后的SQL应该为
SELECT order_id FROM t_order_1 WHERE order_id=1;
也就是说,通过SQL改写,将逻辑sql变为真正的可执行sql,就是Innodb引擎可以解析的sql
SQL执行
Sharding-JDBC采用一套自动化的执行引擎,负责将路由和改写完成之后的真实SQL安全且高效发送到底层数据源 执行。 它不是简单地将SQL通过JDBC直接发送至数据源执行;也并非直接将执行请求放入线程池去并发执行。它 更关注平衡数据源连接创建以及内存占用所产生的消耗,以及最大限度地合理利用并发等问题
.结果归并
将从各个数据节点获取的多数据结果集,组合成为一个结果集并正确的返回至请求客户端,完成最终的数据获取并归并
小结
对于使用者来讲这一切都像是一个封闭的黑盒,只需要按照sharding-jdbc的配置规则进行定义即可,其他的工作交给sharding-jdbc即可
4、代码测试
我们先往数据库插入一批数据,测试代码按照业务层实现顺序依次贴出来
service
@Service
public class OrderService {
@Autowired
private OrderMapper orderMapper;
/**
* 插入
* @param price
* @param userId
* @param status
* @return
*/
public int insertOrder(BigDecimal price,Long userId,String status){
int statusRes = orderMapper.insertOrder(price,userId,status);
return statusRes;
}
/**
* 查询
* @param ids
* @return
*/
public List selectOrderLists(List ids) {
return orderMapper.selectOrderLists(ids);
}
}
dao
public interface OrderMapper {
int insertOrder(@Param("price") BigDecimal price, @Param("userId") Long userId, @Param("status") String status);
List selectOrderLists(@Param("ids") List ids);
}
sql.xml
insert into t_order(price,user_id,status) values(#{price},#{userId},#{status})
使用junit进行测试,编写测试代码
@RunWith(SpringRunner.class)
@SpringBootTest(classes = App.class)
public class OrderTest {
@Autowired
private OrderService orderService;
@Test
public void testInsert(){
for(int i=1;i<20;i++){
orderService.insertOrder(new BigDecimal(i),1L,"SUCCESS");
}
}
@Test
public void testQuery(){
List ids = new ArrayList<>();
ids.add(456788249407389697L);
ids.add(456788250867007489L);
List lists = orderService.selectOrderLists(ids);
for(Order single : lists){
System.out.println(single.getOrderId());
}
}
}
首先运行testInsert,插入部分数据

效果验证,发现数据都进入了order_db2的库中,均匀分布到两个不同的表里面了
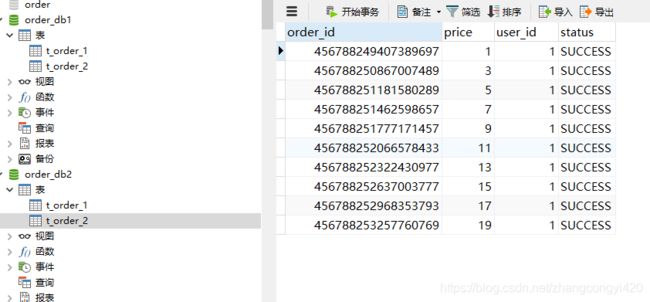
因为我们的分库策略是根据user_id来的,这里插入时候的user_id为奇数,所以落下数据的库为偶数库,同时,通过打印出来的sql日志也可以验证上面的sharding-jdbc整个执行sql的流程
查询测试
随机取出两个order_id进行查询,测试testQuery方法

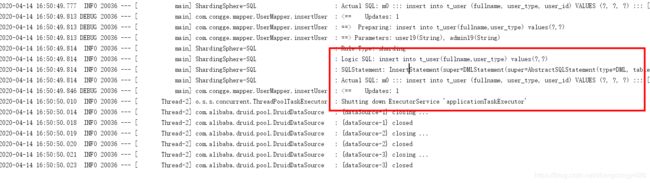
通过打印的sql我们分析再次印证上述的sql执行过程原理,同时也说明,如果我们不指定查询的数据库,sharding-jdbc会自动去完成路由的映射,但是这样也带来了更多性能上的开销和损耗,因此能够带上库的话尽量带上
垂直分库代码整合与测试
明白了基本的原理之后,再做垂直分库的代码整合就不难了,首先再创建一个库user_db,用户保存用户的表t_user数据
CREATE TABLE `t_user` (
`user_id` bigint(20) NOT NULL COMMENT '用户id',
`fullname` varchar(255) NOT NULL COMMENT '用户姓名',
`user_type` char(1) DEFAULT NULL COMMENT '用户类型',
PRIMARY KEY (`user_id`) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8 ROW_FORMAT=DYNAMIC;
整合过程和上面的水平分库流程一致,只需要再在配置文件中添加关于user_db的分库分表策略,下面贴出文件的完整配置,具体的配置说明可参考上面的水平分库配置解释
server.port=8087
spring.application.name=sharding-jdbc
spring.main.allow-bean-definition-overriding=true
#mybatis配置
mybatis.type-aliases-package=com.congge.entity
mybatis.mapper-locations=classpath:mybatis/*.xml
mybatis.configuration.map-underscore-to-camel-case=true
#配置sql输出
logging.level.root=info
logging.level.org.springframework.web=info
logging.level.com.congge.mapper=debug
logging.level.druid.sql=debug
#定义分库规则
spring.shardingsphere.datasource.names=m0,m1,m2
#数据库用户库的配置
spring.shardingsphere.datasource.m0.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.m0.driver-class-name=com.mysql.jdbc.Driver
spring.shardingsphere.datasource.m0.url=jdbc:mysql://106.15.37.145:3306/user_db?useUnicode=true&characterEncoding=utf-8
spring.shardingsphere.datasource.m0.username=root
spring.shardingsphere.datasource.m0.password=123456
#数据库订单库1的配置
spring.shardingsphere.datasource.m1.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.m1.driver-class-name=com.mysql.jdbc.Driver
spring.shardingsphere.datasource.m1.url=jdbc:mysql://106.15.37.145:3306/order_db1?useUnicode=true&characterEncoding=utf-8
spring.shardingsphere.datasource.m1.username=root
spring.shardingsphere.datasource.m1.password=123456
#数据库订单库2的配置
spring.shardingsphere.datasource.m2.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.m2.driver-class-name=com.mysql.jdbc.Driver
spring.shardingsphere.datasource.m2.url=jdbc:mysql://106.15.37.145:3306/order_db2?useUnicode=true&characterEncoding=utf-8
spring.shardingsphere.datasource.m2.username=root
spring.shardingsphere.datasource.m2.password=123456
# ******************************* 分库策略开始 *******************************
spring.shardingsphere.sharding.tables.t_order.database-strategy.inline.sharding-column=user_id
spring.shardingsphere.sharding.tables.t_order.database-strategy.inline.algorithm-expression=m$->{user_id % 2 + 1}
# ******************************* 分库策略结束 *******************************
# ******************************* 分表策略开始 *******************************
#指定t_order表的数据分布状况,配置数据节点
spring.shardingsphere.sharding.tables.t_order.actual-data-nodes=m$->{1..2}.t_order_$->{1..2}
#指定t_user表的数据分布状况,这里暂时只有一张表
spring.shardingsphere.sharding.tables.t_user.actual-data-nodes=m0.t_user
#指定t_order表的配置主键生成策略SNOWFLAKE
spring.shardingsphere.sharding.tables.t_order.key-generator.column=order_id
spring.shardingsphere.sharding.tables.t_order.key-generator.type=SNOWFLAKE
#指定t_user表的配置主键生成策略SNOWFLAKE
spring.shardingsphere.sharding.tables.t_user.key-generator.column=user_id
spring.shardingsphere.sharding.tables.t_user.key-generator.type=SNOWFLAKE
#指定t_order表的分片策略,包括分片键和分片算法
spring.shardingsphere.sharding.tables.t_order.table-strategy.inline.sharding-column=order_id
spring.shardingsphere.sharding.tables.t_order.table-strategy.inline.algorithm-expression=t_order_$->{order_id % 2 + 1}
#指定t_user表的分片策略,包括分片键和分片算法【这里没有做分表】
spring.shardingsphere.sharding.tables.t_user.table-strategy.inline.sharding-column=user_id
spring.shardingsphere.sharding.tables.t_user.table-strategy.inline.algorithm-expression=t_user
# ******************************* 分表策略结束 *******************************
#打开sql输出日志
spring.shardingsphere.props.sql.show=true
下面贴出测试的业务逻辑代码
service
@Service
public class UserService {
@Autowired
private UserMapper userMapper;
public int insertUser(String fullname,String userType){
return userMapper.insertUser(fullname,userType);
}
}
mapper
public interface UserMapper {
int insertUser(@Param("fullname") String fullname, @Param("userType") String userType);
}
sql.xml
insert into t_user(fullname,user_type) values(#{fullname},#{userType})
单元测试类,测试插入部分数据
@RunWith(SpringRunner.class)
@SpringBootTest(classes = App.class)
public class UserTest {
@Autowired
private UserService userService;
@Test
public void testInsertUser(){
for(int i=1;i<20;i++){
userService.insertUser("user" + i,"admin" + i);
}
}
}
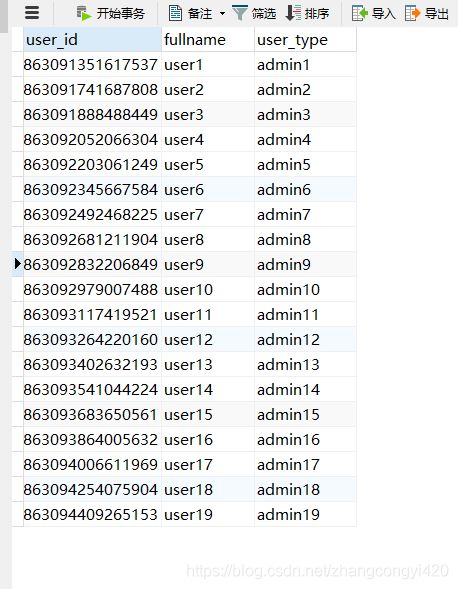
执行后,可以检查数据库是否插入成功
数据库也成功插入若干条数据
查询的测试就不再继续写了,有兴趣的童鞋可以自己写一下,本篇的整合与测试就到此结束,最后感谢观看!