TCP SACK panic漏洞的解释和思考(删)
最近几天一直在和CVE-2019-11477 SACK panic漏洞进行纠缠,挺有意思的。
细节就不多说了,给出几个链接自己看吧:
https://access.redhat.com/security/vulnerabilities/tcpsack
https://github.com/Netflix/security-bulletins/blob/master/advisories/third-party/2019-001.md
我自己也第一时间写了一篇。网上已经有很多文章描述这个漏洞的概览,危害以及如何补救,但是若要理解该漏洞的原理以及触发条件,还是要看我写的这篇:
CVE-2019-11477漏洞详解详玩:【已删改】 https://blog.csdn.net/dog250/article/details/92201200
至于说补救的方法,那太多了,一会儿我会给出一个自己的,然后,我得喷一通,这是惯例。
现在先来熟悉一下该漏洞原理以及一个EXP流程的说明。
在 CVE-2019-11477漏洞详解详玩 中已经描述过的原理,本文便不再赘述,本文是一个关于 如何做以及为什么会这样 总结,虽是总结,却也不简单。
先从数据的发送方式说起。
若想利用这个漏洞,攻击普通的网络服务器不一定可行,若要攻击成功或者说有成功的非0概率,服务器发送数据的方式必须满足一定的要求,即 以分散/聚集IO方式发送非线性数据同时开启GSO 才可以。
因为只有这样,被SACK的数据段才有可能会合并成一个大段,然后在总长和mss做除法求gso_segs时发生溢出。
可以看到,分散/聚集IO是关于用户进程和内核之间的IO接口,而GSO则是内核和网卡之间的IO接口,有了这两者,即可以大大减轻内核本身的负担。而内核本身,即可以将更多的时间片花在如何高效组织和利用数据上了。
比如,将覆盖多个skb的sack段合并成一个skb。
Linux内核设计如此颇值得深思。我们知道,之所以会在收到SACK段后会尝试合并skb,即将跨越多个skb的SACK段合并成一个,并不是多此一举,而是为了性能考虑。
在Linux 4.15内核之前,TCP的 已发送未确认队列 是以链表组织的,如今的网络在硬件方面,其介质质量越来越好,网络带宽越来越大,接收端主机的内存越来越大,对应的软件方面,TCP的发送窗口便随之增加,DBP持续增长,这意味着TCP的 已发送未确认队列 越来越长,而 长链表 在增删查方面是低效的,所以便有三种趋势的优化方向:
- 尝试将链表变短,即合并操作;
- 改变数据结构,比如用树代替链表;
- 改变数据结构的同时,尝试元素合并。
然而理论上如此在具体操作上并非如此简单,并非所有的TCP 已发送未确认队列 的被SACK的连续skb都是可以合并的。也就是说,合并操作这件事是在满足一定条件下才会发生的。
我们先看下普通的数据发送方式:
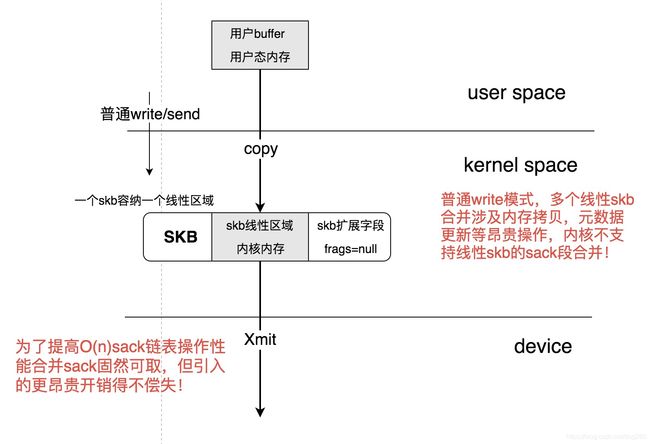
可见,skb本身就是数据的容器。
这种数据发送方式下,就不能合并skb,因为合并操作涉及大量的内存拷贝,这种性能损耗会抵消掉合并skb带来的好处,更何况,有合并就有分割,这又会有额外的内存损耗。
如果服务器以这种方式发送数据,那么注定攻击不会成功。
但是对于攻击者而言,幸运的是,如今的高性能服务器都不是用这种普通的方式吐数据的,而几乎都是采用了更加 高效 的方式,即分散/聚集IO的Zerocopy方式,不管是writev调用还是sendfile等等,我们看一下:
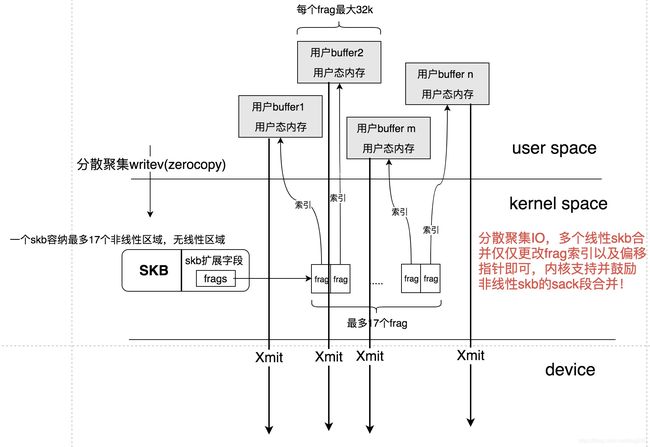
这种方式,skb不再是数据的容器,而仅仅是一个 把手(handle) 。
对于攻击者而言,攻击这种高性能高并发的服务器,影响才够大,效果才够好。而恰恰这种服务器才是可能被攻击的,才是最容易被攻击的。
我们回过头来看看漏洞利用的前提条件:
- 以分散/聚集IO方式每次发送32Kb的非线性skb数据并且开始GSO。
近一周查资料,请教朋友同事,目前的WEB服务器,各种代理服务器几乎都是满足的。 - 拥塞窗口快速增加到 已发送未确认队列 容纳 17 × 32768 17\times 32768 17×32768字节的大小。
目前的高性能服务器带宽很大,很容易快速增窗,在积累攻击数据的时候,为了防止丢包造成减窗,伪造重复积累ACK即可。
在满足上面两个大前提的条件下,我给出一个EXP的packetdrill脚本模拟,以一个实际的方式来展示如何利用该漏洞,而不是长篇大论:
…
【本来此处的脚本已被要求隐藏,待漏洞被完全修复后,重新开放】
全程值得注意的一点就是,攻击者时时刻刻都要beat cwnd!必须控制好被攻击侧的cwnd,而这并不容易,因为被攻击侧的cwnd是通过各种因素通过自己的拥塞控制算法自行计算出来的,所以攻击者依然要使用一些诱导措施,去影响被攻击侧的cwnd计算。做到:
- 不能太小,小到没有机会重传以及合并的skb,从而没有机会在tcp_fragment中做除法。
- 不能太大,大到重传时连续调用tcp_fragment,将剩余skb的总长度减到了溢出阈值以下。
哈哈,这本身就是一件很好玩的事情。
理解CVE-2019-11477这个漏洞如何被利用其实并不简单,虽然流程上并没有什么复杂之处,但是在Linux内核的TCP实现上,非常多的trick,代码非常凌乱,if语句非常多,超级多的垃圾细节,我自己连修改内核,上systap,改tcpprobe,绕过这个绕过那个,几乎熬了两个通宵才完成,最后发现没啥动机利用这个漏洞干点什么事,反而又撸了一遍TCP的源码,我记得曾经承若不再玩TCP了,有点恶心了,看来没能兑现。
一句话概括,你要对TCP在Linux内核的实现非常熟悉,熟悉程度要细化到每一个if语句。
其实有更简单的方法证明这个漏洞确实存在,只是证明,该证明无法用于漏洞利用。
也就是说缩小数据类型宽度,强制一个POC(proof of concept)…很简单,把gso_segs从unsigned short改为unsigned char即可,这样我们无需什么非常大的窗口就能模拟出BUG_ON的条件。
关于修复,Netfilx官方给出的以下patch:
https://github.com/Netflix/security-bulletins/tree/master/advisories/third-party/2019-001
足以解决问题。同时,如果不想给kernel打patch的话,各种规避方案也是有很多。当然关闭sack这种就不建议了,性能损耗太大了。
review了很多规避方案,以下的方案甚为精妙:
- 当TCP建连协商时,如果mss小于某个足够危险的值,就用iptables -j TCPOPTSTRIP --strip-options sack把sackOK给清理掉。
但是这个方案无法封堵ICMP Need Frag报文中途改变mss的情况,于是就需要再写一条规则来DROP掉携带小于足够危险的mtu的ICMP Need Frag报文,这就增加了事情的复杂性,过度依赖外部的iptables配置了。
何不写一个Netfilter模块搞定一切呢?其实就是把上面两条iptables的内核相关模块实现抄写到一个独立的Netfilter模块中而已。
但是我并不准备在这个Netfilter模块中阻滞小mss协商包的sackOK选项以及阻滞小mtu的ICMP通告,而是换了一种思路,即实时监控TCP连接的mss值以及到达的sack段,一旦mss小于某个足够危险的值,便清除掉到达包的sack段,以阻止潜在的sack序列攻击。
随手撸的代码如下,当然,大部分也是抄的:
#include 现在到了让我喷一会儿的时间。
不知大家还记不记得OpenSSL的Heartbleed漏洞CVE-2014-0160:
https://en.wikipedia.org/wiki/Heartbleed
之所以重新提到这个和Linux内核八杆子打不着,和TCP八杆子打不着的漏洞,那是因为在我看来五年前的CVE-2014-0160心血漏洞和CVE-2019-11477 SACK panic漏洞在风格上,亲如兄弟,如出一辙:
- 根植于混乱,出世于混沌。实现太太太乱了,代码太恶心了!
你想对代码的每一行,每一个参数细节做合规性检查,简直不可能!不可能!不可能!
是的,心血漏洞后我为此喷过OpenSSL:
令人作呕的OpenSSL: https://blog.csdn.net/dog250/article/details/24552307
事后,我也做了反思,视野要开阔,人无完人,孰能无过…
直到前几天,还有朋友问我关于OpenSSL的问题,不过我早就疲倦了,不想作答:
问题不是 为什么还在用 ,而是在于 已经用了 , 而是在于 没有别的可以用!
之前有人怼我怼的好啊, “你给OpenSSL资助一分钱了吗?你给OpenSSL贡献一行代码了吗?没有就别瞎逼逼!”
怼的很有道理,也确实,OpenSSL非常不容易了,不管怎么说,赛里布瑞特吧!
说回TCP。
TCP已经30多年了,早就该死掉了,之所以没有死就是因为 人们已经用了 以及 没有别的可以替代 。
我厌倦了去陈列为什么TCP该死掉的事实,一方面是因为真正懂的人其实并不多,另一方面,在以此为饭碗的人们面前去陈列这些事实,面对的十有八九不会是客观的讨论而是被怼,所以,为了避免重蹈当时喷OpenSSL的覆辙,罢了。
不过还是要稍微喷一下。
抛开生态而言,纯技术上,TCP真的就是垃圾,就和OpenSSL一样!TCP是垃圾:
- 其实现代码中处处都是trick,编程大牛们,泰斗们说,代码最忌讳的就是trick,但TCP的实现里全是。
- 绝大多数的实现,比如Linux/BSD已经完全不可维护,不可升级进化,BBR虽是创举,但我觉得不会再有第二次。
如果谁想针对TCP实现的一个点做优化或者扩展啥的,则牵一发而动全身,解决了一个问题,却引入新的问题,代码已经杂糅耦合成了一团乱麻。你改动的任何代码都保不准是否会在别的地方被误解甚至误用。
但是,每天总是会有新的trick诞生,从而也就滋生了新的BUG,具有讽刺意味的是,代码的作者并不知道什么时候在什么情况下就会飞来一只BUG,不得不靠BUG_ON来捕获它们,然后以宕机为代价,予以修复。
以至于,扫一下Linux内核TCP方面的所有BUG_ON,不出意外,定能扫出新的漏洞,定有收获,要不要试一下呢?
哈哈哈哈哈哈~~
程序员喜欢确定的东西,喜欢可以推导出来的结果,不喜欢被规定或者被绑架的结论,所以程序员往往较真于此,但答案往往都是简单,不得已的规定而已。
恰恰TCP的实现这种很垃圾的东西,浪费了程序员大量的时间和精力。
这里不说TCP,以IP说话。
比如,有人问, “为什么IP报文最长能容纳65535个字节的数据?为什么是2个字节表示长度,2个半字节不行吗?” 如果你回答 “RFC就是这么规定的。” 往往提问者不会满意… 总是觉得用2个字节表示长度是另有蹊跷。
但是,这里必须转折。
大部分人虽不满足于结论,但往往对于过程也是浅尝辄止。你知道 大端机和小端机 的区别,但是为什么会有这两种设计?它们的优缺点分别是什么?你搜一下答案,铺天盖地的都是《格列佛游记》里的那一段。几乎没有人从类型转换,protocol解析效率的角度去看这个问题。
好了,写完了。
把《三国》看完了,不能平静。中国如若能维持三分天下,五胡便不会乱华,至少影响不会那么大。
都喜欢司马家族的老谋深算,奉为官场职场楷模,但我并不喜欢这种隐忍,至少在我看来,司马家族和刘皇叔一样,是自私的,格局偏安在自身。
我还是喜欢曹操那种家国天下的格局,北拒胡虏,南抗孙刘,当时的历史形势下,不得已嘛,只有曹操的做法是对的,其他人都是浑水摸鱼。看看几乎同时期的罗马帝国,三世纪危机,同样是混战。把视野拉大,就会发现,司马家族以及孙刘,终成笑话。
虽说是演义,又拍成了电视剧,但还是喜欢其中的一些话:
“也许你昨天看错了我曹操,可是今天呢,你又看错了,但是我仍然是我,我从来都不怕别人看错我。”
对了, “何不食肉糜?” 这个是司马家的人说的,而且可能是真的。
曹操真的是很牛逼的经理,看看他用的人就明白了。三国一并考虑,下面的组合如何:
- 谋士:郭嘉,陆逊。霸道之后有均势。
- 将军:徐晃,马超。这俩人都比较生猛,而且专业素质又高。
- 将军:许褚,赵云。这俩人都是禁卫军经理。
- 将军:魏延,吕蒙。这俩人善于自由发挥。
- 精神&后勤:程普,黄忠。这俩人精神领袖,战争动员。
反正,张飞,关羽,诸葛亮这种肯定是被排除的,炫耀技巧之辈,只是显得牛逼,吵吵闹闹的嘴炮之徒罢了。
浙江温州皮鞋湿,下雨进水不会胖。