Google Brain 研究员梁辰:从零开始搜索机器学习算法(附视频、PPT)
导读:2020 年 5 月 16 日上午,在北京智源人工智能研究院主办的智源论坛第 31 期上,AutoML-Zero 团队核心成员梁辰做了题为《AutoML-Zero: Evolving Machine Learning Algorithms from Scratch》的学术报告,并和特约嘉宾、字节跳动人工智能实验室总监李航进行了对话,探讨了自动机器学习(AutoML)技术的前沿发展。

梁辰,博士毕业于 Northwestern University,是 Google Brain 研究员,主要研究方向包括 AutoML、Neural Symbolic Methods、RL、NLP,在NeurIPS/ICML/ICLR/ACL/IJCAI/AAAI 等会议发表了多篇论文。
AutoML 是目前机器学习中发展比较迅速的一个领域,并且在自然语言处理和计算机视觉等任务上取得了不错的效果。但是目前 AutoML 有一些局限性,主要体现在两个方面:自动机器学习方法还不够自动,很多方面依然需要机器学习专家的手动设计;搜索的范围只是整个机器学习算法中很少一部分,限制了 AutoML 的潜力。
Google Brain团队最新的研究成果,可以很好地规避这两个局限性——这项技术被称之为AutoML-Zero,意为“从零开始的自动机器学习”。作为AutoML-Zero团队的核心成员,梁辰在报告中详细介绍了AutoML-Zero的设计思想和工作原理。据梁辰介绍,AutoML-Zero 探索了一个新的研究方向:从零开始从基本的数学操作去搜索机器学习算法,包括实验展示了可以通过进化算法重新发现包括反向传播在内的很多机器学习算法。
下面,我们先来阅读梁辰带来的精彩分享。
整理:智源社区 车飞虎 季葛鹏 高洛生 杨依帆
一、背景介绍
机器学习(Machine Learning,ML)算法的设计与应用需要大量的专家干预,这些人工干预表现在:特征提取、模型设计、算法优化和参数调节等几个方面。而自动机器学习(Automated Machine Learning,AutoML) 技术的出现,则试图实现自动化地学习以上几个重要步骤,使得 ML 模型无需专家干预即可被应用于科研或者工程项目之中。

图1:自动机器学习成功案例
AutoML 技术的发展已为机器学习及其衍生领域带来巨大的福祉,众多优秀的搜索算法案例如雨后春笋般接踵而出,在很多现有的基准测评上面取得了优异的性能排名,例如:图像分类 [1]、目标检测 [2]、自然语言处理 [3]。另外,它在评估协议和应用方面的发展也不可忽视。而梁辰在这次分享报告中提到的工作,从 Why、How、What 三个方面依次为大家介绍了他在 AutoML 领域的探索——AutoML-Zero。
二、Why——为什么要做Auto-ML?
(一)AutoML 算法的局限性

图2:自动机器学习的局限性
梁辰在报告中指出,虽然 AutoML 算法在众多领域取得了如此优异的成绩,但是其算法设计也存在一定的局限性。他将 AutoML 这个技术名词拆解成两个部分来看:
1. 自动化(Automatic,Auto):现有的算法往往被大家诟病并没有那么自动化,很多元素和模块仍旧依赖于机器学习专家的手工设计。举一个最直接的例子就是:算法中搜索空间的限定需要机器学习专家的设计,但是近来研究者发现很多结构空间中的搜索方法不是那么重要,即便做一个随机搜索(Random Search)也可以得到一个具有竞争力的结果。
2. 机器学习(Machine Learning,ML):大多数算法搜索的只是整个机器学习算法中的一小部分,比如只聚焦于结构(Architecture),优化的方法(Optimizer)或者激活函数(Activation Function)等子模块的搜索,而算法中其余的大部分都是由专家预先设定的。
(二)如何消除 AutoML 算法局限性?

图3:AutoML-Zero 能否消除自动机器学习算法的局限性?
上面提到的局限性,虽说不影响算法在基准测评中的表现结果,但是很大程度上面限制了 AutoML 技术巨大的潜力(小编:AutoMLer 的终极梦想)。于是梁辰团队开始提出了对于 AutoML 技术的思考:如何移除局限性?我们是否能够在最小的专家干预情况下搜索整个机器学习算法?
答案是:可以。我们可以从两个方面来缓解局限性:(1)尽量减少手工设计从而摆脱对于先验知识的依赖,即做到真正从零开始;(2)用最少的专家设计去搜索整个算法空间。

图4:一个简单的例子——如何建立一个神经网络模型?
作为引入,我们来看一个简单的例子:一般地,我们使用现有的机器学习库来实现一个神经网络并不困难,只需要调用库中现成的 API 函数和模块即可,但是无形之中会引入很多 Expert Knowledge。“从零开始”的一个最直接的想法是,借助 Numpy 数学库中的数学操作来实现神经网络这样的机器学习算法,这便在某种意义上实现了不依赖于机器学习专家的设计。这也是我们 AutoML-Zero 需要探索的问题:能不能只用基本的数学操作来搜索新的机器学习算法?
(三)什么是 AutoML-Zero?

图5:拓展——建立一个AutoML-Zero模型
如果将上述例子拓展一下,就是给出数学基本操作空间集合,给出既定的机器学习任务空间集合,我们通过AutoML-Zero 模型,在以上两者的基础上探索发现一些机器学习算法。
三、How——如何从零设计AutoML模型?
(一)算法的定义和评估
既然需要搜索机器学习算法,面临的第一个难题就是如何表征一个算法?一般地,我们在将所有的机器学习算法最终应用落地的时候,都要实现成为一个程序,所以梁辰团队用程序来表征机器学习的算法。梁辰表示,鉴于研究工作中受到有监督学习的启发,便把算法归纳成包含三个函数的程序:“Setup()”用于初始化算法的超参数,“Predict()”用于输出预测结果,和 “Learn()”用于真值样本监督下的回归更新参数。

图6:如何表征和评估一个算法
如图 6 所示,梁辰团队定义了 64 个基本的数学操作,比如:数值运算、三角函数、预备微积分、线性代数、概率论与统计等。具备了基本的数学操作定义后,还需要定义如何评估一个机器学习算法(Evaluation),并在每次评估预测值与真值是否匹配之后,便将结果累计于 Loss 函数中,用于参数的学习,实际上这也是我们常见的监督学习算法框架流程。
(二)任务目标的定义

图7:任务定义
给出了表示和评估算法的方式后,我们还需要一些机器学习的任务定义,也就是需要在这些任务中搜索一个算法。这个过程类似于元学习(Meta-learning),即所关注的不仅仅是一个任务,而是多个任务的集合,所以可以构建元数据集(Meta-dataset)。最后在任务集合上面取平均准确率作为算法评估的结果。类似于常见的 AutoML 算法流程,梁辰将任务分成三个步骤:
搜索(Search/Meta-train):搜索过程当中用来评估候选算法的表现;
算法选择(Algorithm selection/Meta-validation):从候选算法中选择最佳的算法;
最终评估(Final evaluation/Meta-test):在全新的任务上面进行测试、尝试更高维的数据、或者使用不同数据分布的数据集进行测试。
(三)规则化进化算法
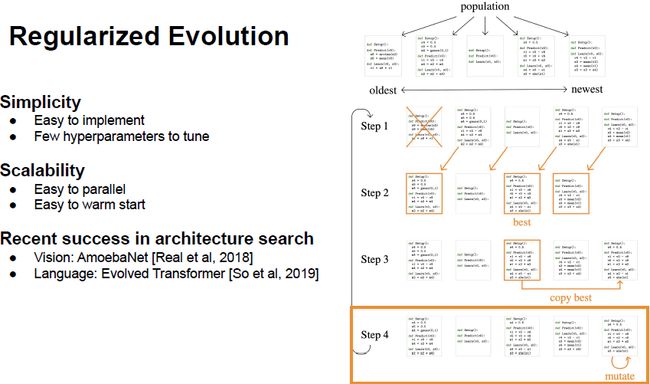
图8:规则化进化算法(Regularized Evolution)
接下来,梁辰介绍除了用 Random Search 作为基准参考,还有一个搜索方法是 Regularize Evolution,它实现起来非常简单,而且本身的超参也非常少。具体方法就是每次一个 Population,图8例子中有 5 个 Program Individual,从最早到最新依次排序,接下来就是重复几个步骤:首先把最早的程序移除,也是 Regularized Evolution 的一部分,然后把剩下的复制过来再选一个子集,然后在其中 Evaluation,再把最佳的 Program 进行复制并执行 Mutation 操作,就从目前最佳的程序通过 Mutation(变异)得到一个新的程序。在不停地重复这样几个步骤的过程当中,Population 当中的程序会变得越来越复杂,最终 Accuracy 也会变得越来越好。
我们可以看到整个算法的过程非常简单,同时也非常容易拓展,比如:Evaluation 每个 Individual 的过程当中完全并行化地来做,同时也非常容易去做 Warm Start,如果已经知道某个程序是非常好的,便可以通过这个程序来做 Initial Population,这样可以节省很多搜索的计算。
(四)算法细节——变异

图9:变异(Mutations)
直观理解下,Mutation(变异)就是在已有的程序上面生成出一个新的程序,在这里梁辰给出了三种比较简单的变异算法:随机插入或删除指令、随机化一个函数、随机地改变指令中的参数。
(五)相关工作介绍

图10:相关工作介绍
另外更加详细的相关工作介绍可以参见梁辰团队的论文原文,包含 AutoML,Genetic Programming,Meta Learning 和 Program Synthesis 等内容。
(六)若干加速方法

图11:加速的方法
梁辰还为大家介绍了若干关于加速方法的介绍,例如:Proxy tasks(向低维度映射)、Migration(多个 Worker 交互 Run Evolution)、Functional Equivalence Checking(FEC,用于消除具有相同功能的冗余程序)、Diversity in tasks 和 Hurdle(提前结束结果很差的一些算法)。感兴趣的同学可以移步论文原文查看更多细节。
四、What——得到哪些令人欣喜的结果?
上文详细阐述了AutoML-Zero的出发点以及具体实施步骤,下文将着重阐述在该项工作过程中得到的非常有意思的一些结果。
(一)AutoML-Zero的搜索空间到底有多难?
AutoML的搜索空间到底有多难?由于AutoML-Zero希望尽量减少人工的设计,所以在该项工作中并不存在高级模块,而是从最基本的数学操作开始进行搜索。这导致搜索空间更大,并且让搜索难度增加。通过包含基本数学操作的线性回归任务,证明AutoML-Zero可以很好地解决该问题。搜索过程如图12给出的简单线性回归程序所示。

图12:搜索过程示例
如何定义一个搜索任务的难度?之前的方法多是通过解空间的指数级别来衡量,但是这并不完全准确。假若一个搜索空间非常大,但是搜索空间中大部分都是较好的解,那么搜索问题也并不困难,这也就解释了为什么在神经网络架构搜索领域当中可以达到较好的结果。更好的评估方法应该是看搜索空间当中好的解的密度有多大,然后通过一个简单方法近似估计。即运行一个随机搜索,确定经过多少次尝试才能找到最优解,尝试次数越多说明问题越复杂。
梁辰指出,实验中发现的困难确实较之前的神经网络架构搜索要难很多,其中最大的难点就是合适的解非常稀疏。这是由于AutoML-Zero尽量减少了人工设计,因此导致很难找到合适的解。这在直观上也比较好理解:随机地写一些程序,然后做机器学习任务的可能性是非常低的,即使以最简单的线性回归举例,也需要四个指令和数百万次的尝试才能通过随机搜索找到合适的解。倘若把问题变难一点,则需要搜索三个Function,同时还需要加入一个偏置变成新的回归问题,使得该问题很快就会变成10^12,因此AutoML-Zero的确增加了很多挑战。但与此同时,梁辰认为我们也可以从中看到非常有希望的地方:尽管进化使得问题变难了,但是可以在随机搜索的基础上得到显著改善。实验发现即使在一个比较简单的AC Regression问题上便可以达到10^4的提速。更有意思的是,随着问题难度的增加,进化后的方法相对随机搜索的提速也会增加。所以尽管搜索空间变得复杂了许多,但是一些富有挑战性的问题还是有希望找到一些解决方案。
(二)进化能重新找到支撑吗?
这项研究工作的初衷是希望通过进化的方法或者自动搜索的方法重新发现一些经典的机器学习算法,比如现在最常用的反向传播算法。梁辰团队发现,将之前的线性任务换成非线性任务,搜索过程中可以更加容易地找到反向传播算法或者找到神经网络。
比较有意思的是,尽管Evolution问题非常具有挑战性,但是仍然可以找到双层神经网络的影子。图13展示了搜索过程当中的代码段。为了方便展示,代码段删除了一些对整个程序理解没有影响的操作,同时在不影响程序原意的情况下做了一些重排。从该段代码中不难看出,该段程序和常见的神经网络非常类似,可以初始化矩阵、向量以及一些学习率等,可以在Predict部分进行一些点积运算,然后会用Maximum Function得到最后的预测结果。

图13:代码框架
梁辰认为其中最有意思的是 Learn 部分,因为没有为其提供 Ingredient 操作,所以需要用基本的加减乘除运算求出每一层的成分。这就如同最开始学习机器学习时,为了加深理解大多数初学者会做一个练习,多通过使用 NumPy 实现算法,而不像 TensorFlow 可以给出封装好的操作。Learn 部分首先会计算输入数据和标签的差值,然后 Scale 学习率,并在反向传播的过程中得到 Activation Ingredient,最后对这两层的位置进行更新。
不难发现,由于 AutoML-Zero 尽量减少人工的设计使得整个搜索空间复杂了很多,但是演化后的方法依然可以从基本的数学操作找到神经网络反向传播等经典算法。
(三)进化的方法能否找到其他算法?
能否将 Evolution 给予相对真实的数据集并找到其它算法?在前文的描述中,尽管是通过低维的数据搜索,但不局限于低维的数据,高维数据上依然可以凑效,使得最终估计时希望在原始数据维度进行估计,随后也进行了更加富有挑战的工作,就是在不同的数据集上搜索出来的算法是否依然可以奏效。
在搜索的过程当中,通过图14所示曲线将整个演化过程抽象出来,横轴是实验进展,纵轴是最佳算法在任务上达到的准确率。由于任务是二分类,最开始可达到50%的准确率;接下来会出现线性模型,可以更新得到更好的结果;之后是 Normalize Ingredient;最后会出现乘法相互作用。整个过程当中程序的时间复杂度和空间复杂度会变得越来越长,同时准确率也在逐渐提高。
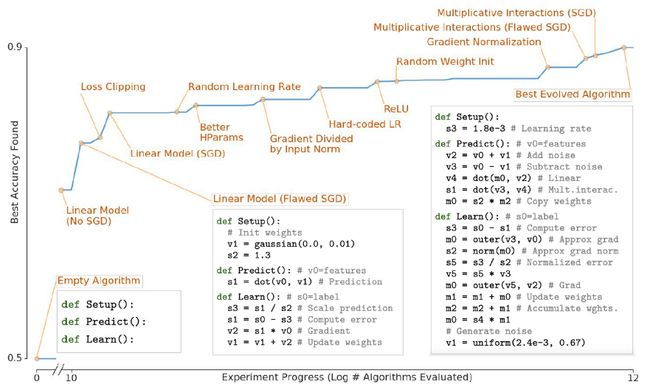
图14:搜索精度随实验的变化
找到算法之后,在搜索数据集上可以工作,但是其它的数据是否也可以奏效?通过图15不难发现,Discovered这一行确实不仅仅可以在原始数据上奏效,在其它数据集上面的表现同样比线性或者简单的基准线更好。
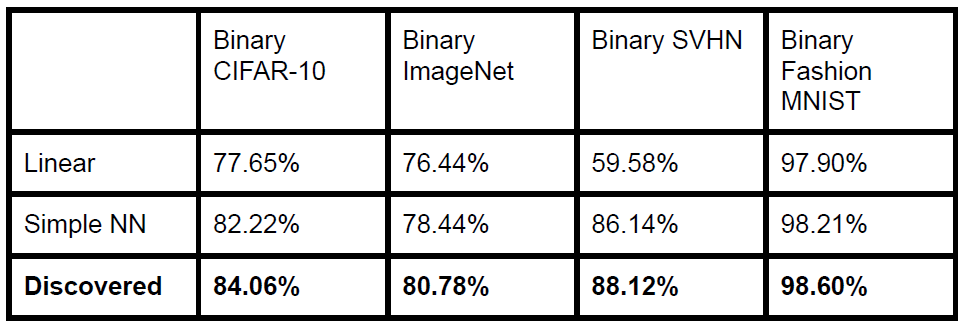
图15:对比结果
(四)进化的算法是做什么的?
通过上面的实验可知,这样做的确可以找出一些比较有意思的算法,那么该算法到底做了什么?怎样达到比传统的神经网络效果更好?通过分析代码可知。
如图16所示:左半边是用可视化的流程图,右半边是程序代码。S0 相当于 Label y*。首先,会生成一些随机噪声,然后加入或者减到输入上,相当于对输入数据做数据增强。其次,由于 M0 是矩阵,所以会通过输入 V2 得到 V4,V4 再和 V3 做点积运算,得到最终 Output。该过程实际上是一个 Bio-linear Model。

图16:算法流程图
然后通过标签减去预测值,接下来就通过上文提到的 Auto Product 计算 Ingredient,而不是直接去用 Ingredient 更新参数。最后计算一个近似值,相当于做了一个规则化。然而最令人感到感到惊讶的是除了矩阵 M0 之外还用到了 M2,通过 M2 累计权重,之后在 Predict 时再将 M2 复制到 M0 当中。
(五)进化能适应现有的算法吗?
梁辰指出,由于 AutoML-Zero 没有限制只能搜索计算机器学习算法的某一部分, 反而给了更多搜索或者创新的空间,我们可以在输入部分增强搜索的方法,反向传播部分发现 Normalize Ingredient。梁辰认为,前面谈到的处理方式是比较理想化的设定,每次都从零开始进行搜索,但实际应用当中如果已经知道很好的算法,就没有必要每次都从零开始进行搜索,而应该用已知的比较好的算法初始化。那么,是否有可能通过改变每个机器学习任务或者实验设置诱导 AutoML-Zero发现不同的算法?譬如让任务本身的数据量更少、更加容易过拟合,从而更加容易规则化?
答案是肯定的。方法是通过让数据量尽量减少,即 Fewer DataSetting 原则。在2010年曾经有发表过这么一个思路:仅用 800 个和 80 个训练样本,更少的数据量就会重复该模式,然后再添加一个随机噪声。实验证明,通过加上噪声达到想要的效果,确实可以通过改变实验或者任务的 Setting 来发现不同的方法。除此之外,还有通过减少训练步骤发现可以让模型训练收敛更快的方法。然而还有许多难点并没有被理解,例如:学习率衰变,即通过指数式衰变发现更快的收敛的方法。另外,AutoML-Zero还尝试了多任务分类的问题,通过抽象作为学习率(Learning Rate)来使用,但是梁辰也指出这项技术背后的好处并没有完全理解。尽管该方法能够找到更好的算法,但是如何解释算法在做什么?如何理解算法背后的道理?本身也是一个非常富有挑战性的问题。
上文介绍的实验发现:通过 Warm Start 或者 Existing Algorithm 可以极大地减少计算成本,证明确实可以通过改变任务背景发现不同的方法。由于 AutoML-Zero 这项工作旨在探索一个新的方向,但是仍然存在一些问题。比较明显的就是是否能够进一步减少局限性,上文提到的 Setup Predict 和 Learn 的框架,使得很多重要的算法并不能够在该框架下表现出来,怎样进一步减少这种局限性,从而发现全新的算法也是一项值得探索的工作。探索一些新的算法并理解背后的含义,不仅提高搜索效率,也有利于找到更加复杂的算法。
演讲最后梁辰指出,尽管如今的 AutoML 看似已达到较高的水准,但可能只呈现了它潜力的冰山一角,还有更多的潜力值得人们挖掘。从零开始进行机器学习算法减少了人工设计,尽管使得搜索问题变得复杂了很多,但是演化后的方法依然有些令人欣喜的结果——我们可以发现一些经典的机器学习算法。由于时间关系和篇幅限制,很多AutoML-Zero的细节未在演讲和本文中提及,详细细节参见项目GitHub地址( https://github.com/google-research/google-research/tree/master/automl_zero#automl-zero )。
结语
自动机器学习是一个非常有意义的研究领域,不仅可以使机器学习算法尽量摆脱专家知识,降低机器学习算法的应用门槛,还可以通过搜索发现一些新的机器学习算法。本次演讲中,梁辰从如何让 AutoML 更加自动和对整个机器学习算法进行搜索两个方面深入浅出地介绍了 AutoML-Zero,为自动机器学习探索了一个新的方向:从零开始用基本的数学操作去搜索机器学习算法,并且实验结果展示进化算法可以重新发现包括反向传播在内的很多种机器学习算法。
关于自动机器学习的未来研究方向,梁辰认为可以从下面四个方面展开:
1. 进一步减少自动机器学习的局限性,发现新的机器学习算法;
2. 应用到更多真实的机器学习任务中提高性能;
3. 对已经发现的机器学习算法提供更好的解释性;
4. 提高搜索效率。
附:对话与问答
梁辰演讲结束后,和来自字节跳动人工智能实验室总监李航进行了对话交流,并分别问答了观众提问。

李航,ACL 会士、IEEE 会士、ACM 杰出科学家。京都大学毕业,东京大学博士。曾就职于 NEC 公司中央研究所,任研究员;微软亚洲研究院,任高级研究员与主任研究员;华为技术有限公司诺亚方舟实验室,任首席科学家与主任。
下面是梁辰、李航对话和观众问答的精彩要点。
第一环节:李航向梁辰提问
李航:AutoML有没有理论指导?怎样能够判断哪些操作是需要的,哪些是不需要的?
梁辰:我们的工作主要是探索新的方法,理论方面还没有非常完善。我们选择操作的时候是一个很简单的标准:不要涉及机器学习已有的概念。我们也希望这些基本操作能够支持经典的算法,但很多问题我们都没有解决,比如说我们在选择过程中是否已经包含一定的倾向性——我们已知神经网络的算法是什么样的,而我们最终选择的操作可能无形当中就倾向于神经网络的算法,这样不适合于发现新的方法。
李航:人脑是一个非常复杂的系统,人工智能需要参考人的信息处理机制开发出更好的机器学习算法,借鉴人脑和人的认知能力从复杂的神经网络开始可能是更好的。我非常理解您研究的意义,但这和原来的想法是背道而驰的是吗?多大程度上能够真正帮助人工智能未来的发展?
梁辰:AutoML-Zero这项工作可以说是在一个比较理想化的设定下。目前大家在AutoML常用的方法,更多的是在已经设计好的搜索空间、比较小的创新空间当中进行;而我们希望拓展大家的想法,实现一个和大家现在的做法非常不一样的,即完全从零开始找出一些有意思的东西。我们最终希望启发的是处于中间位置的方法——既不是已经设计好了的高级模块,也不是每次都从零开始进行搜索的方法。
李航:您提到了群体的概念,人类的进化就是多个群体产生更大的进化和更大的效果。是不是多个群体之间有些交互,能够促进算法的成功率和探索的速度?
梁辰:您提得特别好,这是前面我没有展开阐释的叫做Migration的概念。我们每个机器运行一个Evolution,同时我们有一个中心服务器,中心服务器起到的作用是让不同的群体进行交换。我们发现这样确实有好处。好处之一在于这样更并行化,我们可以同时运行多个Evolution,通过中心服务器进行交互,单个机器因为内存限制,到了一定程度不能变得更大。另一个好处是优化探索效率,单个Evolution更容易卡在某一部分,这样本地优化就进行不下去了,而多台机器通过中心服务器交流的方法能够减少本地优化的问题。
第二环节 梁辰、李航分别回答观众提问
观众:Proxy Task的规模和大小对效果有没有影响?
梁辰:肯定是有影响的。从Proxy Task的深度来讲,比如为了让一个Task运行速度更快,我们可能会把它的特征集(Feature Set)或数据集(Data Set)变小,这样会对最终结果产生影响的。如果只选取一部分的话,我们发现选取的子集不能非常小,不然会和真正的Task效果没有很强的关联性,导致最终的结果不够准确。
另外大家讨论比较少的就是Proxy Task的广度也非常重要,如果只用一个Proxy Task,最终搜索出的方法可能只作用于这一类Task。在AutoML中,如果我们只用某一类Task或某一个具体的数据集进行搜索,可能最后得出的算法是没有进行过任何学习的。只有把这个数据集的数目增加,它才会觉得可能要做一些学习,这样才能在不同的数据集上都可以起作用。所以深度和广度都会对效果有影响。
观众:基本运算知识库是不是需要不断增加?
梁辰:目前我们用的都是非常基础的运算,因此是一个比较理想化的设定。我们在选基本运算的时候,可能加入了偏好在其中,因为最常用的是神经网络,我们选择的过程当中无形就会受到这个影响。将来真正的算法是需要进行转化的,如何扩展操作库和减少偏好对于发现全新的算法非常重要。
观众:能否引入强化学习思想,用判别器来自动改善算法?
梁辰:我们最开始也考虑过引入强化学习思想改善算法,但最后的选择更多的是基于扩展性考虑。我刚才也展示了一个Evolution的例子,它非常简单,并没有很多超参需要去调,非常容易并行化,这样我们才可以达到每秒钟每个CPU上面1万个Evaluation的速度。引入强化学习以后可能会让整个实施的设计流程比较复杂,比如首先需要引入强化学习模型,这个模型也会引入更多超参需要去调。比如要将强化学习的判别器放在中间的服务器上,服务器也要处理Learning Logic,会让系统变得比较复杂。
观众:如何保证Initialization和Mutation过程中产生的Algorithm/Program是合法可执行的?
梁辰:在Initialization和Mutation过程中选择函数的参数时会做基本的Type检查,让表达式符合语法。如果在程序执行中出现Error那么这个Program就会得到很低的分数,从而被淘汰掉。
观众:如何保证每次迭代过程中准确地evalute和compare每个算法呢?
梁辰:在evaluate和compare过程中是有可能有Noise的,在某一步迭代中可能会错过好的算法,但是因为同一个算法有可能会在Evolution过程反复出现,所以会减弱Noise的影响。
观众:如果把BP 作为初始解,能否找到比BP 更好的优化算法?
梁辰:我们的实验中从BP 基础上发现了一些可以帮助学习的经典技巧比如Learning Rate Decay,Noisy ReLU等等,但是我们的探索还比较初级,这个方向还有更多的挖掘空间。
观众:AutoML-Zero在Cifar10上的最终精度能达到86%,但现在Cifar10上精度已经能达到90%+了,请问现在AutoML这个领域目前仍然无法达到人手调的网络的精度吗?
梁辰:在这个工作中我们的重点不是去和State-of-the-Art比较,而是尝试从零开始搜索。AutoML在很多任务上已经得到了超过人手调的精度,比如最近的EfficientNet。
观众:请问下实验中的Discovers有没有被reuse在现有的DNNs中,用来提高DNNs的性能?
梁辰:在实验中有discover一些DNN中常用的经典技巧比如Weight Averaging,Learning Rate Decay,Gradient Normalization等等。
观众:除了定义的一些基本数学算子,是否可以增加复杂的算子,如卷积?
梁辰:我们的框架可以通过加入更多的操作,比如卷积来进行扩展,这是一个很有意思的未来方向。
观众:梁博报告中提到的简单任务采用深度网络做WarmUp,最终退化,那么有没有做类似神经网络压缩相关的实验呢?另外,AutoML搜索出来的网络是否对对抗样本的鲁棒性有待提高?
梁辰:还没有做和压缩或对抗样本相关的实验,但是应用AutoML-Zero的框架到这些问题上是很有潜力的未来方向。
观众:人工智能会不会暴动,会不会反抗,会不会超出我们的掌控?
李航:原则上这个问题需要慎重,但不需要担心。任何一个工程系统,如果设计它的人要做一些坏事,那么可能就会有风险有危害。我们假设工程师设计这个东西完全出于善意,这个时候是能够设计出来最后要怎么控制这个系统,实现的过程当中也会去考虑,做好了以后也会去做测试,原则上会尽量减少可能发生的任何问题以及不能掌控的风险。就像汽车比人跑得快,那么我们不能掌控汽车了吗?有点像这个问题,设计汽车的时候我们一定要考虑怎么安全,能够让人控制汽车。
观众:人工智能会对社会带来什么影响?对人们就业产生什么影响?
李航:其实这个问题已经历史悠久,大概上世纪三十年代爱因斯坦曾经写过一篇文章叫做《科学与社会》。当时大家就在讨论科学会给社会带来什么样的风险,包括大规模杀伤性武器、人的就业问题、信息上不好的影响,比如有的人会操控信息。我觉得从宏观的、人类的角度来看,是不需要担心这样的事情的。中国改革开放四十年,四十年前中国农村的就业人口大概是当时人口的90%,现在大概是30%-40%,中国社会因为这些变化变得更差了还是变得更好了?所以从整个社会发展的角度来说,整个产业自然会发生变化,更多的人去做另外一些工作。未来偏创造性的、有情感类的工作可能是机器不能替代的,同时也有很多相对枯燥、劳累的工作我们也未必想去做,并且是希望机器能够替代它们的。所以人类发展整体上是在不断进步的,从某种意义上讲大家不需要担心。另外,从微观层面来说,对于每个人怎么在自己有生之年为社会创造价值,让自己的人生活得更有意义,建议可以选择感兴趣的、能给自己带来更多价值的工作去做。
第三环节:梁辰向李航提问
梁辰:李老师从整个机器学习的角度是怎么看待AutoML的?我了解的主要有两派,一派是认为AutoML能够发现一些比较有意思的工作;另一派则认为AutoML其实是一项调参的工作,叫做AutoML有点言过其实,希望听一听李老师对AutoML发展方向的建议。
李航:未来AutoML一定是一个重要支柱,即使短期来说AutoML的意义也是很大的,比如工业界当中,像Google这样计算资源非常丰富的公司,已经可以通过AutoML找到更好的架构模型,并在一定范围内产生了效果。瞄向未来的话,AutoML可能还是需要一些理论的研究,特别是探索新的机器学习机制、模型和算法等方面的工作。
对于机器学习、深度学习,新的Architecture给这个领域带来变化的可能性是最大的。回顾过去三十年,算力已经增加了100万倍,数据量的增加大概也是这个规模,带宽、通信速度都是快速增长,未来这种持续增长的趋势还是不会变的,所以开发新的Architecture仍然有很多机会。
简单就自然语言处理来说。人脑处理语言的时候有两个脑区,布洛克区和维尼卡区,一个负责语法,一个负责语义,其实就是一个 Unified Architecture。人脑在进行自然语言信息处理时,语法和语义是并行的。所以现在神经网络的处理方式,我们从一定程度上也能看到局限性:我们现在通过Transformer,将语法和语义处理放在了一起。如果神经网络能够像人脑一样把语法和语义从一定程度上剥离开来,相对比较独立,但也形成交互就更好了。
计算视觉也是这样,人的视觉存在两个维度:一个是处理空间,一个是处理大小。现在Neuro Architecture进行各种图象处理的时候并没有分开,所以人的处理其实是更复杂的。我们希望计算机能够像人一样处理语言、处理图像,我相信是需要有更接近人的Architecture才能做到,而这个方向上最有希望取得突破的一项重要技术就是AutoML。
梁辰:确实,AutoML可能是把算力推向极致的方法,通过增加算力减少工作量,但是需要借助我们对人的观察,或者需要一些其它学科的启发。还有一个问题想问李老师,未来哪些方法是在深度学习领域比较有潜力的方法?
李航:您也在做符号处理和神经处理的结合,这也是很具挑战的方向,非常值得继续探索。现在业界已经可以用神经网络做些事情,但还是跟人有很大的差距。未来也希望有突破,我所说的突破是指像2012年左右深度学习对整个人工智能领域带来的影响,如果有的话就非常棒了。
关注“北京智源人工智能研究院”公众号,回复关键词“梁辰”下载PPT。
点击“阅读原文”进入智源社区,与AI爱好者们一起参与本文讨论。
参考文献:
[1] Tan, Mingxing, and Quoc Le. "EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks." International Conference on Machine Learning. 2019.
[2] Tan, Mingxing, Ruoming Pang, and Quoc V. Le. "Efficientdet: Scalable and Efficient Object Detection." Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2020.
[3] So, David, Quoc Le, and Chen Liang. "The Evolved Transformer." International Conference on Machine Learning. 2019.




