斯坦福大学Christopher Manning:Transformer语言模型为什么能取得突破
2020 北京智源大会
本文属于2020北京智源大会嘉宾演讲的整理报道系列。北京智源大会是北京智源人工智能研究院主办的年度国际性人工智能高端学术交流活动,以国际性、权威性、专业性和前瞻性的“内行AI大会”为宗旨。2020年6月21日-24日,为期四天的2020北京智源大会在线上圆满举办。来自20多个国家和地区的150多位演讲嘉宾,和来自50多个国家、超过50万名国内外专业观众共襄盛会。
2020年6月22日,在第二届北京智源大会语音与自然语言处理专题论坛上,国际自然语言处理著名学者、斯坦福人工智能实验室负责人Christopher Manning做了名为《Linguistic structure discovery with deep contextual word representations》的主题演讲。
在演讲中,Christopher Manning 根据对语言学结构的学习程度,将语言模型分为三个发展阶段:早期基于概率统计、无法学习语言结构的黑暗时代(Language Models in The Dark Ages);之后则是启蒙时代的神经语言模型(Enlightenment era neural Language Models),特点是具备一定学习语言结构的能力;2018年始,基于Transformer结构的大参数量预训练模型(Big Language Models)大行其道,Manning发现预训练语言模型的参数中包含着非常多的语言结构信息,并在本次演讲中进行了详细的解析。

Christopher Manning,斯坦福人工智能实验室(SAIL)主任,斯坦福大学语言学和计算机科学系机器学习领域、斯坦福人类中心人工智能研究所(HAI)副主任。Manning 的研究目标是以智能的方式实现人类语言的处理、理解及生成,研究领域包括树形 RNN 、情感分析、基于神经网络的依存句法分析、神经机器翻译和深度语言理解等,是一位 NLP 领域的深度学习开拓者。他是国际计算机学会 (ACM)、国际人工智能协会(AAAI)、国际计算语言学会(ACL)等国际权威学术组织的 Fellow,曾获 ACL、EMNLP、COLING、CHI 等国际顶会最佳论文奖,著有《统计自然语言处理基础》、《信息检索导论》等自然语言处理著名教材。
整理:智源社区 何灏宇
一、语言模型:用数学给语言建模
在报告中,Christopher Manning首先引出了语言模型的概念。语言模型是对自然语言进行数学建模的工具,它提供了一种能够用数学模型去表示自然语言的方法。现如今通用的语言模型大多采用序列化概率模型的思想,比如在给定的语境下预测下一个词出现的概率。

图1:根据语境预测下一个词
语言模型如N-Gram语言模型、基于循环神经网络的语言模型及预训练语言模型等都在不同的任务上被广泛使用,且能达到理想的效果。然而,这些语言模型真的学到了语言结构吗?还是说它们仅仅是在句子层面上学习词的概率分布?Manning给出了他的答案。
二、黑暗时代:N-Gram语言模型
N-Gram语言模型,是通过统计数据中给定词在长度为n的上文的条件下出现的频率来表征这些词在相应语境下的条件概率,如

图2:N-Gram例子
N-Gram语言模型是神经网络出现之前构建语言模型的通用方法,该方法虽然通过引入马尔科夫假设,但是其参数量依然很大。另外,N-Gram语言模型通过平滑和回退策略解决数据稀疏的问题。但是N-Gram语言模型学到了多少人类语言的结构信息?有些语言学家们认为几乎没学到。虽然这样的模型可能会包含一些简单的常识性知识,比如“船”通常会与“沉没”、“起航”等词共同出现,或者模型会学习到一些简单的词法,比如类似于“冠词-形容词-名词”这样的句子,但是N-Gram语言模型对于“名词”这样的词性概念和语言结构规则是没有概念的。
因此,在那个时代,如果想要让模型学习到语言结构,必须通过人工标注的方式获取特定语言结构的训练数据,然后训练相应的分类器。采用这一方法固然是能让语言模型学习到语言结构,但是标注成本太高且数据的迁移性差,似乎并不是一个好的解决方案。
图3:人工标注的语法
Manning随后表示,想要让语言模型学习到自然语言的结构知识,只学习字面上的信息是远远不够的,但幸好,自N-Gram语言模型之后,基于神经网络的语言模型取得了长足的进步。
三、启蒙时代:
神经网络赋予语言模型新的方向
得益于神经网络和深度学习带来的强大学习能力,神经网络语言模型展现出了比N-Gram语言模型好得多的效果。这其中最为人熟知的便是前向神经网络(FFNN)语言模型和循环神经网络(RNN)语言模型。前向神经网络语言模型通过把高维度的稀疏向量嵌入到低维度的分布式向量,从根本上解决了维度灾难问题。循环神经网络语言模型,例如LSTM模型,通过“门”的机制解决长距离依赖的问题,这样的模型结构在处理语句这种序列化数据时就有着天然的优势。Manning提到,N-Gram和过去的大多数模型都解决不了语句中的长距离依赖问题,但我们可以期待神经语言模型做到这一点。
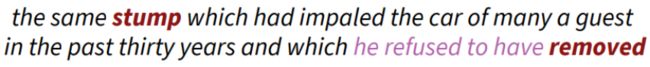
图4:预测词removed,需要用到句子中距离较远的词stump而不是通过N-Gram在近距离取上下文
同时,Manning还展示了通过树结构的神经网络捕捉语句结构的一个研究成果。事实上,Manning 早期的深度学习工作一直致力于构建树形模型,因为在他看来,树形模型更能捕捉到语言不同于线性的视觉或者信号处理的结构特点。他们建立的TreeLSTM能够在一定程度上学习到如何去构建语句的语法树,该模型在细粒度情感分类、语义关系分类等任务上也取得了更好的效果,但比提高准确率更重要的是,语言模型终于开始学习语言结构了。

图5:语法树
四、大模型时代:
Transformer模型带来巨大突破
2018年,大参数量的预训练语言模型一个接一个的出现,为自然语言处理带来了突破性的进展。

图6:预训练语言模型
在这些预训练模型中,除了ELMo,其他的模型都应用了Transformer结构,原因是Transformer的结构使得模型在GPU上进行大规模训练成为可能,而模型的参数量也越来越大,达到十亿甚至百亿级别。Transformer的输入是句子中的词以及词的位置编码, 通过一层线性变换,每个词得到Query、Key、Value三个低维向量。通过对三个向量做Attention运算,从而计算出句子中的每个词应该对句子中的其他词付出多少“注意力”。不仅如此,Transformer结构中还引入了“多头”机制,“多头”机制认为句子中的上下文信息可以从多个方面进行挖掘,因此Transformer使用了多个权重矩阵对Query、Key、Value向量进行Attention运算,从而达到通过多个权重矩阵学习多重语义信息的目的。

图7:Transformer的结构
这些基于Transformer结构的预训练语言模型在自然语言处理的很多领域都产生了巨大的影响,显著地提高了多个NLP任务的准确率。那么,动辄几十亿参数的预训练模型们可以学习到多少语言结构呢?在本次演讲中Manning选取了其中最著名的BERT模型进行了分析。
根据对Transformer结构的理解可以知道,Attention运算是通过点积加权的方式计算两个向量的相关性,从而得到句子中的每个词对其他词该付出多少“注意力”。通过分析这个注意力结果,Manning发现,在BERT的多个“头”中,有几个“头”是能够通过无监督或自监督的方式学习到和依存句法相关的信息的。

图8:BERT模型中每个词对其他词的注意力,颜色越深表示注意力越强
如上图的左半部分,宾语sell和stocks会将注意力更多地指向动词considered和recommending,而在上图的右半部分,限定词(冠词等)the、in,形容词huge、new等,它们更多将注意力指向名词language、law、flight、time等。如果对这四个例子中的语句进行依存分析,我们会发现左图中的词sell、stocks与动词considered、recommending构成了直接宾语的依存关系,而右图中的词the、in、huge等都是名词laguage、law等的前置修饰语,它们构成了语句中的限定词依存关系。可以看到模型确实在一定程度上学习到了依存句法信息。
事实上,“多头”机制不仅学习到了句法结构,也学习到了语句中的共指关系。下图中左边的例子中,she、her、Kim实际上指的是同一个人,从模型中的注意力分布也可以看到这种关系。右图同理。

图9:BERT模型中的某些“头”学习到的共指关系
Manning表示以上的这些发现证明,预训练语言模型能够对语言的符号结构进行建模,因为不管是依存句法还是共指关系其实都是一种用符号表示语法的方法,这是一件很酷的事情。但如果模型能够直接对语言结构进行建模,那就更好了。
随后,Manning提出了一个问题:在BERT模型的向量空间中是否蕴含着语法树结构?为了验证这个问题,Manning对BERT模型产生的词向量进行了探索,希望这些基于深度上下文的词表征能够带给我们答案。那么,如何根据词向量去构建这些树呢?
Manning假定句子中词向量间的L2距离作为树中结点之间的距离,根据这个距离构建一棵最小生成树,并将这个最小生成树作为模型学习到的语法树,最后用该树去与人工标注的语法树进行验证。值得一提的是,在不同的语境下,一个词可能会有不同的含义,那么每个词向量就可能会包含着多重语义信息。在实验时,Manning通过对词向量进行线性变换从而将词向量映射到一个低维的空间,这个低维的向量就包含了原词向量在特定语境下的语义信息。
实验结果表明,BERT根据上下文词表征构建的树效果非常好,在许多场景下都可以达到人工标注的精度。如下图中,根据BERT向量空间构建的最小生成树,与本篇文章图5所提到的语法树完全一致。
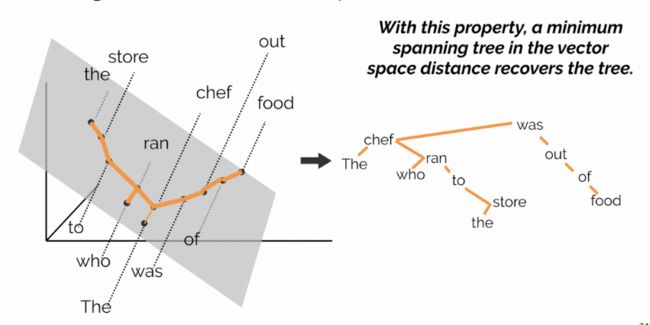
图10:根据BERT向量空间构建的最小生成树

图11:用BERT做语法分析树能够达到和人工标注相似的结果
根据这样的实验结果,Manning总结道,像BERT这种基于深度上下文词表征的语言模型,与之前的语言模型相比有了一个大转型,不论是形态上还是学习效果上。模型中大量的参数使得神经网络不再仅仅去学习词与词之间的表面联系,而是有了学习语法结构的能力。至于为什么模型会去主动学习语法结构,Manning也给出了解释,他认为模型之所以会去主动学习语法结构,是因为学习语法结构能够帮助模型更好地完成预测任务,也就是说,模型本质上依然是在提高预测能力,由于学习到语法结构有助于更好地预测,模型就会利用参数去学习语句的语法结构。
接下来,Manning做了另一个更有趣的探索,探索不同种类语言的BERT模型是否学到了相似的语法信息。做法如下,使用一种语言(如英语)的BERT模型的语法空间表示去验证另一种语言(如法语),如果验证成功,那么就说明BERT模型编码不同种语言的语法是采用的是相近的方法。

图12:两种语言的语法空间聚类结果
上图是实验结果,相似颜色的浅色代表英文,深色代表法语,可以看到聚类效果明显,这表明BERT模型在建模不同语言的语法信息时采用的方法是相近的。
演讲最后,Manning提出了如下几点思考。
1. 基于无监督或自监督学习的上下文词表征模型能够成功学习到语言结构,取得这样的成功证明了语言模型的学习实际上是一个信息量丰富的通用任务。
2. 既然语言模型已经能够学习语言结构,那过去几十年耗费人力标注语言学数据算是一个错误吗?
3. 基于深度上下文词表征的语言模型已经从之前的基于统计的关联学习模型转型,开始主动探索语言结构。
4. 在下个十年,语言模型的任务是否应该更多地将重心放在接地语言学习(Grounded Language Learning)上?
点击阅读原文,进入智源社区参与更多讨论。





