清华大学张悠慧:超越冯·诺依曼模型,实现软硬件去耦合的类脑计算(附视频)

软硬件去耦合是计算机系统结构中非常重要的设计方法论。简单来理解,即软件研发人员不需要考虑底层硬件如何设计;而硬件开发人员则只需要遵循一定指令集规范,并不用担心兼容性,也不用考虑上层软件开发问题。多年以来,软硬件去耦合确保了通用计算机体系结构的快速发展。而之所以能够做到软硬件去耦合,其背后的原理便是“图灵机与计算理论”。
那么类脑计算,要超越甚至替代冯·诺依曼模型和传统计算机,是否也需要做到软硬件去耦合?该用什么方法实现?这些问题对类脑计算的研究和开发意义重大。
针对这些问题,在第二届北京智源大会“智能体系架构和芯片”专题论坛上,智源学者、清华大学张悠慧做了题为“软硬件去耦合的类脑计算系统设计与思考”的专题报告。

张悠慧,清华大学计算机系研究员,博导,主要从事计算机体系结构,包括处理器设计、类脑计算芯片与基础软件、高性能计算等方向的研究;曾担任多个国际/国内学术会议程序委员会委员及期刊编委;在NATURE、ASPLOS、MICRO、NIPS、DAC等期刊/会议上发表论文近70篇;是国家科技进步二等奖、国家级教学成果二等奖、教育部科技进步一等奖获得者。
张悠慧在演讲中首先介绍了类脑计算的起源、应用与发展等研究背景,并分析了以类脑芯片为核心的软硬件和基于“通用”类脑计算开发框架(语言)系统两种类脑计算研究的现状,以及探讨了如何从传统计算机的发展中汲取经验,采用软硬件去耦合、软硬件协同设计等多种方法论,来探索符合类脑计算与神经形态器件特色的设计方法论,最后,张悠慧简述了通用类脑计算当前研究的最新进展和下步工作重点。
整理:智源社区 王光华,贾伟
一、研究背景:类脑计算的起源、应用与发展
类脑计算或者神经形态计算的历史比较悠远。神经形态计算的鼻祖之一,加州理工的Carver Mead教授在1990年提出“神经形态计算”这个词,并将其定义为“采用以模拟器件仿真生物神经系统的VLSI来实现大规模并行的自适应计算系统”[1]。

图1:加州理工Carver Mead教授
但这个概念提出的初衷,并不是为了做AI或神经网络计算等,主要是为了追求计算效能。因为传统数字架构,一条指令执行时,需要经过译码、数据传输等一系列操作再进行计算,其“耗能不单是这个计算本身的,而是执行整个计算流程所消耗的总能量”,效能不高。而生物系统的计算效能比数字计算系统计算效能高几个数量级。所以,当时的有识之士,便开始借鉴生物神经网思想,用以提升计算效能。这里主要包括两点:一是使用基本的物理现象作为计算的原语,类似于模拟计算的方法。二是,采用类似Spiking这样的模拟相对值而不是数字的绝对值来进行信息表述。这两点是生物系统能效优势的根本原因,对于提升计算效能具有非常重要的启示。
图2:类脑计算所支持的各类应用[2]
张悠慧介绍,类脑计算应用目前比较侧重于AI。根据综述文章[2],类脑计算目前所支持的主要应用是神经网络形式的,但是也有越来越多的工作在探索利用类脑计算实现非神经网络应用。主要包括两种,一种是以神经网络的形式解决图计算、计算优化等非AI的问题;另一种是问题形式、表述形式、解决形式等非神经网络形式的,比如利用脉冲神经网络构建通用计算框架。
但2016年的《Nature》文章提到:类脑计算作为后摩尔时代极具潜力的发展方向之一,不能把类脑计算应用只局限于AI,要放宽一点。
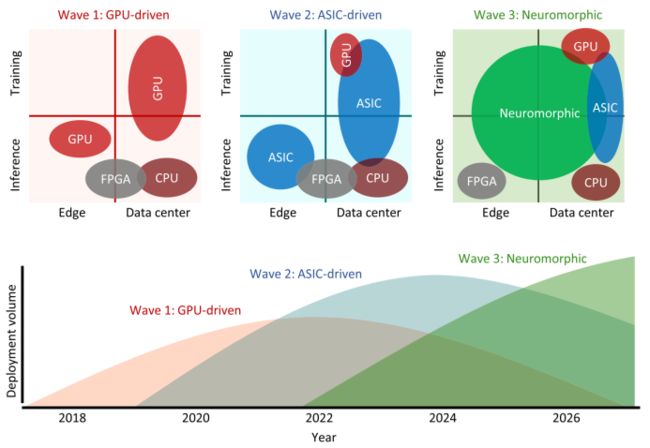
图3:引领类脑计算的技术浪潮[5]
那么类脑计算的未来会怎么样?2020年初有一篇文章[5]指出,类脑计算可能引领下一波Computer Engineering的浪潮。目前,GPU驱动了第一阶段浪潮,第二个阶段将是ASIC加速器,而第三阶段可能就是神经形态计算。图灵奖得主John L. Hennessy和 David A. Patterson在2018年的图灵报告[3]里也提到,未来10年是重新定义计算机体系结构的10年。目前体系结构因发展路径的多样性,将带来体系基础结构创新的重大契机,逐步会有越来越多的非冯处理器崛起,包括神经形态处理器,基于量子力学规律的处理器等[4]。
二、现状分析:
专用芯片 vs “通用”框架(语言)
张悠慧介绍,目前已经有很多种类的类脑芯片开发,比如,斯坦佛大学Neurogrid团队和滑铁卢大学NEF团队合作的Braindrop;英特尔的Loihi;以及TrueNorth、SpiNNaker、BrainScales等。
这些类脑芯片大多以软硬件协同设计为主,各芯片提供了自己特有的软硬件接口以及工具链。好处是端到端的设计对于适配的应用而言效率比较高;不足之处则是纵向设计,把上层应用和下层系统软硬件等绑定在一起,导致缺乏应用的可移植性,降低开发的效率,开发人员不得不面对底层硬件暴露的约束。
图4:Braindrop[6]
与Loihi等系统相比,Braindrop做得比较灵活。Loihi等系统对外提供的编程原语是基于神经元、神经元突触、神经网络这个层次。而Braindrop则是利用滑铁卢大学的NEF框架,在功能级上提出的编程原语。用户可以将认知计算函数描述成为一个非线性的微分方程系统,并且与底层硬件是无关的、去耦合的,然后通过NEF将每个方程转换成一组物理上的神经元,并映射到模数混合的芯片上。但它的问题在于当进行设计的时候,软硬件的所有层次都要协同设计,底层硬件设计也要严格遵循理论框架,它的上、下层耦合度很高,只是耦合到了NEF框架里去了。
图5:TrueNorth[7]
TrueNorth是基于认知计算编程语言Corelet进行应用开发的。硬件基础单元是TrueNorth中的神经形态基元模型,包括神经元计算模型、突触模型及其扩展,通过一个或多个神经元配置互联实现基本功能的函数。通过Corelet编程,软件工具链采用分而治之策略,将一个复杂算法分解为简单算法,反复分解直至变换为一个神经突触核所能完成的计算,这时候形成神经形态网络层面的基础单元以及单元的连接。实际上,这种方法也同样把硬件底层的基础单元暴露给了上层开发者。
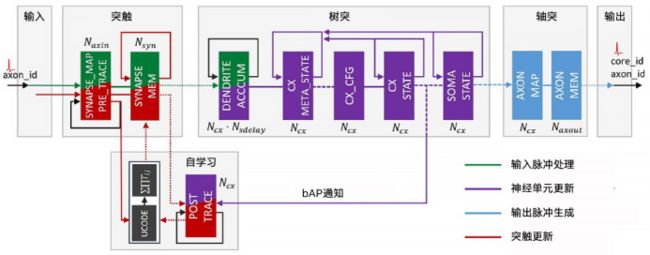
图6:Loihi神经元计算硬件流水线[8]
Loihi对外提供一系列编程原语,用于脉冲神经网络拓扑描述的神经元间室模型、突出模型、突出踪迹、描述SNN动力学的神经元模型以及突出学习规则。如图6,实际上该硬件流水线基本是对照SNN的仿真模型实现的,计算神经学中仿真神经元计算怎么做,Loihi便把它用硬件实现。相当于Loihi把神经网络模拟里的软件流水线硬件固化,形成基本功能单元再暴露给上层的开发人员。首尔大学基于Loihi结构进行了拓展[9],支持SNN的各类学习算法,这些算法主要是基于STDP或者STDP衍生的众多算法,首尔大学分析了多种算法并归纳出更多原语进行扩展支持。但不管怎样,还是把底层的原语直接暴露给上层。
现在很多研究越来越往通用框架演进,目的则是提供一种高层次的编程抽象,实现与具体芯片无关的统一开发框架,使底层硬件规则约束能够对应用开发透明。好处在于较高层次的抽象能够屏蔽硬件细节,提高可移植性和开发效率。但目前的问题在于,芯片底层缺乏一致的硬件接口,仍存在一对一的移植工作。现在很多采用开放社区与标准化方案鼓励大家做相关工作,比如,美国国家实验室2019年做的Fugu项目就是其中典型案例[10]。它试图提供一个通用开发平台,研究人员不需要大量背景知识就能开发应用程序,开发框架通过开源社区的方式去做,将具体应用、脉冲神经网络算法设计、以及神经形态硬件平台的具体细节分离开来,形成三个层次。框架最高层的目标人群是科学计算或者应用开发人员,他们对自己领域很熟但是不熟悉神经网络计算方法;中间层用户比较熟悉神经网络计算,用神经网络实现功能、提供函数,但是不熟悉硬件平台;第三层用户是硬件平台专家开发人员,能够优化和裁剪针对特定硬件的神经网络算法。从公开文献看目前该项目还没有支持某一款特定的芯片,仍然是用模拟器进行替代。
三、当前进展:
通用计算机启示下的类脑计算研究
图7:解耦合的系统设计
张悠慧认为,基于通用处理器的计算机系统层次结构采用的是非常典型的软硬件去耦合的设计方法,这将给予我们方法论上的启示。
总体思路,如图7所示,也是采用软硬件去耦合的系统设计,但在应用和芯片之间引入了软件编程模型、硬件执行模型两层抽象。软件编程模型提供给软件开发人员使用,不需要关心底层硬件的规格与约束,把这些交给硬件执行模型处理,在两层之间通过“编译器”进行编译转换。
以神经网络计算为例,上层的编程模型是数据流或者计算图的编程模型,下层的硬件执行模型也可以看作是数据流,但是,它的原语和规模都是受限的。关键的问题是要把两者进行等价转换。
张悠慧介绍,他们团队在2016年便提出了解耦合系统原型[11],主要通过神经网络的冗余来容忍硬件层面的约束,实现了在类脑硬件具有精度、连接度、函数类型等约束的情况下上层模型到下层模型的自动转换;利用神经网络的冗余性和容错性,通过去除一定的冗余性之后降低精度来匹配硬件约束。该工作支持“天机一代”芯片约束下的“编译”。
2018年,张悠慧团队进一步做了神经网络编译器[12]。这包括两个方面,一是对硬件执行模型的形式化定义,引入点积和非线性函数两个硬件基本算子,二是实现严格硬件约束下的神经网络模型转换,即把神经网络转换为约束条件下等价的网络。因为软件神经元和硬件神经元能力不一样,转换成硬件神经元以后规模可能需要膨胀,以规模换取能力实现精度损失可控。
在工作[12]的基础上,张悠慧团队做了架构设计与映射工具[13]。[12]说明方案是可行的,还需要进一步研究该方案的效率。基于所需的基本原语,他们提出基于忆阻器的可重构神经网络芯片架构(FPSA),证明了方案的高效性与可实现性。整体上是遵从RISC设计思想,简化硬件设计利用忆阻器高效实现两个原语,上层各种各样软件的灵活性通过编译器实现。同时,引入FPGA可重构路由,解决传统BUS和NOC无法匹配忆阻器高速计算的通信瓶颈问题。
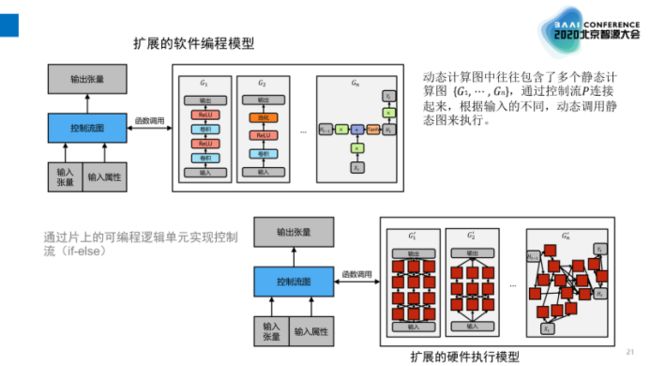
图8:动态图软硬件模型
张悠慧团队还把相关工作拓展到动态计算图[14],即在软件编程模型和硬件执行模型当中使用控制流来支持动态图,使其功能更加完整。动态计算图中包括多个静态计算图,在软件编程模型里根据输入的不同动态调用静态图来执行。底层硬件很大程度上借鉴了FPGA的设计,利用可编程的逻辑单元来实现控制流,即硬件上控制器选择不同的分支来完成不同的执行路径。

图9:FPSA系统栈
FPSA系统栈如图9。最上层是包含各种张量的动态计算图,即各种各样有控制的、不受限制的神经网络操作,通过神经网络编译器编译成等价的仅包括控制流本身和硬件支持的几个核心原语的动态计算图。核心原语目前主要有两个,一个是点积,一个是非线性函数。然后再通过神经网络映射器,把硬件执行模型进一步转化为包含核心原语计算、缓存和控制逻辑的网表,即计算逻辑、计算调度、数据移动和暂存等,最后直接复用FPGA的功能实现相关的布局布线。
在前端,张悠慧团队做了基于GPU的高性能脉冲神经网络开发与仿真平台[15],它支持被广泛应用的SNN的开发语言——PyNN。针对SNN行为的稀疏性、事件驱动等特征,他们采用了细粒度神经网络表示与执行模式,以及带时间戳的稀疏矩阵存储等方法进行特殊优化。使得其性能比现有最新的基于GPU的SNN模拟器要快很多。
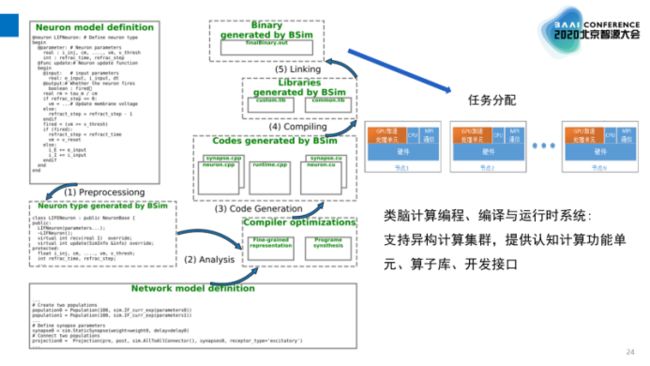
图10:BSIM工作流
图10是BSIM工作流,最上层给开发人员使用,并且屏蔽了硬件的细节,开发人员可以定义模型进行预处理,将网络各种层次连接起来,最后通过编译生成GPU上的执行程序。同时,它还支持不同的底层硬件神经元和突出模型,方便进行功能验证。作为类脑计算编程、编译与运行时系统,目前该平台支持GPU集群异构计算并提供认知计算功能单元、算子库、开发接口。
四、下一步研究:通用类脑计算?
张悠慧认为,当前在类脑计算领域,不管是各家基于芯片构建的系统,还是意图通用的、去耦合的软硬件系统栈都面临的问题是:各平台都有自己不同的开发接口、编程接口,各用各的。
所以从长远来看,我们需要一个解决方案能够应对多个平台。因此希望未来硬件接口能够稳定下来,开发出相同(或者兼容)的接口。
通用计算机系统在这方面做得比较好,软硬件去耦合的计算机层次结构是经典计算机迅猛发展的体系结构基础,这是通用计算机几十年来快速发展背后体系结构方面的逻辑。
如果类脑计算要超越或替代冯·诺依曼模型,我们不能总基于归纳法进行软硬件体系结构的设计,因为这种方法未来无法满足新的应用,并且存在软硬件绑定的问题。
五、总结
张悠慧的报告,让我们体会到:传统计算机系统的软硬件去耦合的层次化设计思想是IT技术得以飞速发展的体系结构基础;目前类脑计算的系统和芯片,虽然具体类型有所不同但都比较侧重于端到端的软硬件协同设计方法,缺乏能将算法、芯片和器件等不同领域技术和需求有机结合起来的软硬件系统栈设计;因此,我们需要进一步从传统的通用计算系统的成功思路中汲取经验,既要形似,也要神似!
另外,演讲结束后,中科院计算所研究员、智源首席科学家陈云霁对演讲内容进行了提问,我们也将张悠慧的回答整理给大家。
Q&A
Q:作为计算机研究者来说,通用性和完备性非常重要,这正是像图灵机这样具有通用性完备性的模型,使得我们今天研究的是计算机,而不仅仅是一个计算器。第一个问题,中间层和TVM的差别是什么?
A:从在系统中的位置和作用来说,它们是类似的。不同在于,第一,TVM主要支持DNN,我们这边更倾向于做SNN。第二,我们目前正在做的工作是想提出一套硬件原语,从理论上确保这个硬件原语从神经系统计算层面来说是足够的。我们目前做了这么一个简单的原型系统,能够证明带来三个好处:1)如果硬件能够实现这套原语的话,理论上确保软件模型和硬件模型的等价;2)至少理论上可以使得底层的类脑硬件能够支持通用的计算;3)我们这种设计将来引入新的系统评测维度,一般系统讲应用性能和硬件开销之间的Tradeoff,我们引入了近似粒度,能够容忍怎样的Error。这是一个三角关系。
Q:我想请教一个问题,我自己感觉在深度学习发展里面有这样一个问题,一开始在学术界应用相对少一些它会显得比较干净规整,但是一旦进入工业界之后,很多“肮脏的东西”就会往上跑。比如我们看现在比较大规模的深度神经网络,比如自然语言处理里面的BERT,或者图像检测里面的Faster R-CNN,仅仅说是向量内机(点积)和非线性激活函数就感觉hold不住了。目前SNN在工业上的实际部署相对来说比较少一些,您能否预测SNN未来进入大规模工业应用会不会有这样的问题出现?
A:我觉得肯定会有这样的问题出现,去耦合和Codesign永远是相辅相成的。理想情况下,基石是去耦合的,通过提供一系列原语来实现。同时,针对特定应用而言,还要通过Codesign在去耦合基础上去提升性能和效率,我相信将来系统肯定是这么一个混合式系统,包括传统计算机也是这样的,完备性是个基石,但是Codesign是提升效能的关键,所以我们可能会针对不同应用需求去扩展做Codesign。
点击阅读原文,进入智源社区参与更多讨论。
参考文献
[1] C. Mead.Neuromorphic electronic systems. Proceedings of the IEEE, 1990, 78(10):1629-1636.
[2] Schuman C D , Potok T E , Patton R M , et al. A Survey of Neuromorphic Computing and Neural Networks in Hardware[J]. 2017.
[3] John L. Hennessy, David A. Patterson. A New Golden Age for Computer Architecture. Communications of the ACM, February 2019.
[4] Kathleen E. Hamilton,et al. Accelerating Scientific Computing in the Post-Moore’s Era. ACM Transactions on Parallel Computing. 2020.
[5] Jack D. Kendall, Suhas Kumar. The building blocks of a brain-inspired computer. Applied Physics Reviews 7, 011305 (2020).
[6] “Braindrop: A mixed-signal neuromorphic architecture with a dynamical systems-based programming model. Proceedings of the IEEE, 2019”.
[7] A. Amir et al., Cognitive computing programming paradigm: A Corelet Language for composing networks of neurosynaptic cores, IJCNN 2013.
[8] Lin C K , Wild A , Chinya G , et al. Programming Spiking Neural Networks on Intel Loihi[J]. Computer, 2018.
[9] E. Baek et al., FlexLearn: Fast and Highly Efficient Brain Simulations Using Flexible On-Chip Learning, MICRO 2019
[10] James B. Aimone, William Severa, Craig M. Vineyard. Composing neural algorithms with Fugu. International Conference on Neuromorphic Systems. 2019.
[11] Yu Ji, et al. “NEUTRAMS: Neural network transformation and co-design under neuromorphic hardware constraints”.
[12] Yu Ji, et al. “Bridge the Gap between Neural Networks and Neuromorphic Hardware with a Neural Network Compiler”.
[13] Yu Ji, et al. “FPSA: A Full System Stack Solution for Reconfigurable ReRAM-based NN Accelerator Architecture”.
[14] Y. Ji, Z. Liu and Y. Zhang, "A Reduced Architecture for ReRAM-based Neural Network Accelerator and Its Software Stack".
[15] P. Qu, Y. Zhang, et al, "High Performance Simulation of Spiking Neural Network on GPGPUs".





