https://raw.githubusercontent.com/nltk/nltk_data/gh-pages/index.xml
A----http://blog.csdn.net/caicai1617/article/details/21191781
《使用Python进行自然语言处理》学习笔记五
版权声明:本文为博主原创文章,未经博主允许不得转载。
目录(?)[+]
第三章 加工原料文本
3.1 从网络和硬盘访问文本
1 电子书
古腾堡项目的其它文本可以在线获得,
整个过程大概需要几十秒(实验室网络不行是硬伤)
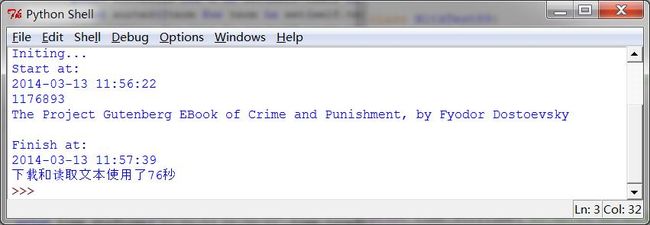
使用raw()可以得到原始的字符串。但是raw得到的数据绝对不是我们能直接拿去分析的,还要经过一些预处理。我们要将字符串分解为词和标点符号,正如我们在第 1 章中所看到的。这一步被称为分词, 它产生我们所熟悉的结构,一个词汇和标点符号的链表。
2处理的 HTML
好像很多公测语料都是html或者xml发布的,这个应该可以处理类似的数据。但书里说其中仍然含有不需要的内容,包括网站导航及有关报道等,通过一些尝试和出错你可以找到内容索引的开始和结尾,并选择你感兴趣的标识符,按照前面讲的那样初始化一个文本。
这里面的“尝试和出错”有点不合适吧。难道不能按标签去找吗,写一个网页模版然后去抽取某基础标签的内容,之前都是这么干的。
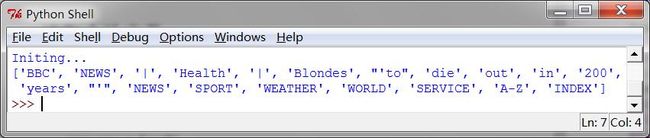
3处理搜索引擎的结果
网络可以被看作未经标注的巨大的语料库。网络搜索引擎提供了一个有效的手段,搜索大量文本作为有关的语言学的例子。搜索引擎的主要优势是规模:因为你正在寻找这样庞大的一个文件集,会更容易找到你感兴趣语言模式。而且,你可以使用非常具体的模式,仅在较小的范围匹配一两个例子,但在网络上可能匹配成千上万的例子。网络搜索引擎的第个优势是非常容易使用。因此, 它是一个非常方便的工具, 可以快速检查一个理论是否合理。
不幸的是,搜索引擎有一些显著的缺点。首先,允许的搜索方式的范围受到严格限制。不同于本地驱动器中的语料库,你可以编写程序来搜索任意复杂的模式,搜索引擎一般只允许你搜索单个词或词串,有时也允许使用通配符。其次,搜索引擎给出的结果不一致,并且在不同的时间或在不同的地理区域会给出非常不同的结果。当内容在多个站点重复时,搜索结果会增加。最后, 搜索引擎返回的结果中的标记可能会不可预料的改变, 基于模式方法定位特定的内容将无法使用(通过使用搜索引擎 APIs 可以改善这个问题)。
4 处理处理 RSS 订阅
我觉得这个部分可以使用爬虫和html处理来解决,更加方便。
5 读取本地文件
只需要注意一点,使用”\\”就没问题的。path2='D:\\PythonSource\\fileTest.txt'

6从 PDF、MS Word 及其他二进制格式中提取文本
ASCII 码文本和 HTML 文本是人可读的格式。文字常常以二进制格式出现,如 PDF 和MSWord,只能使用专门的软件打开。第三方函数库如 pypdf 和 pywin32 提供了对这些格式的访问。从多列文档中提取文本是特别具有挑战性的。一次性转换几个文件,会比较简单些, 用一个合适的应用程序打开文件, 以文本格式保存到本地驱动器, 然后以如下所述的方式访问它。如果该文档已经在网络上,你可以在 Google 的搜索框输入它的 URL。搜索结果通常包括这个文档的 HTML 版本的链接,你可以将它保存为文本。
7捕获用户输入
Python2.X的版本是s =raw_input("Enter some text: "),到了3.X好像是用input代替了raw_input,更加好记了。
8 NLP 的流程

这个图表示的很清楚,我觉得预处理的任务就是将非结构化的数据尽量结构化,以便进一步处理。
- #!/usr/python/bin
- #Filename:NltkTest89,一些关于文本资源处理的测试
- from__future__ import division
- importnltk, re, pprint
- fromurllib import urlopen
- importtime
- importdatetime
- classNltkTest89:
- def __init__(self):
- print 'Initing...'
- def EbookTest(self,url):
- starttime = datetime.datetime.now()
- print 'Start at:'
- print time.strftime('%Y-%m-%d %H:%M:%S',time.localtime(time.time()))
- raw = urlopen(url).read()
- print len(raw)
- print raw[:75]
- endtime = datetime.datetime.now()
- print 'Finish at:'
- print time.strftime('%Y-%m-%d%H:%M:%S',time.localtime(time.time()))
- print '下载和读取文本使用了%d秒' %(endtime- starttime).seconds
- return raw
- def TokenTest(self,raw):
- '''''基于Project Gutenberg的一些分词测试'''
- tokens = nltk.word_tokenize(raw)
- print type(tokens)
- len(tokens)
- print tokens[:10]
- text = nltk.Text(tokens)
- print type(text)
- print text[1020:1060]
- print text.collocations()
- print raw.rfind("End of ProjectGutenberg's Crime")
- def HtmlTest(self,url):
- html = urlopen(url).read()
- html[:60]
- raw= nltk.clean_html(html)
- tokens = nltk.word_tokenize(raw)
- print tokens[:20]
- def FileTest(self,filePath):
- f = open(filePath)
- for line in f:
- print line.strip()
- nt89=NltkTest89()
- url1= "http://www.gutenberg.org/files/2554/2554.txt"
- #nt89.EbookTest(url1)
- #nt89.TokenTest(nt89.EbookTest(url1))
- url2="http://news.bbc.co.uk/2/hi/health/2284783.stm"
- #nt89.HtmlTest(url2)
- path1=nltk.data.find('corpora/gutenberg/melville-moby_dick.txt')
- path2='D:\\PythonSource\\fileTest.txt'
- nt89.FileTest(path2)
3.2字符串:最底层的文本处理
1字符串的基本操作
这一部分讲的是Pyhton对字符串的处理,字符串处理哪种编程都有,再加上Python那么人性化,所以整个上手很容易。
2输出字符串
也很简单,只注意一点,在需要拼接字符串的时候一定要注意,在拼接处需要空格的地方要加空格。如果没有注意可能就会出现”Monty PythonHoly Grail“的情况,如果这是在处理其他指令的话就容易出大问题。之前用Java时就不小心过,取数据的MySQL指令少了一个空格还找了一会才排掉错。
3访问单个字符
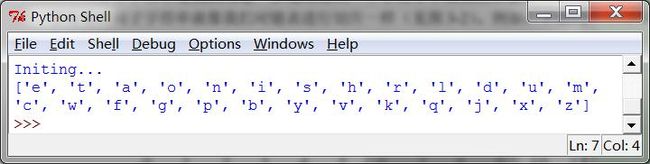
又想起那个关于四六级的笑话了,话说学渣背单词,从前往后背,背不过C,从后往前背,背不过S。看来得说从前往后背,背不过e,从后往前背,背不过t,这样才更科学。
4访问子字符串
主要是列表切片和find,很简单。
5更多的字符串操作
p100有详情。师兄温馨提示我,split和strip非常重要,尤其是strip和Java里的trim一样,处理文本数据经常需要去掉字符串前后的空格什么的,没有会很麻烦。
6链表与字符串的差异
当我们在一个 Python 程序中打开并读入一个文件,我们得到一个对应整个文件内容的字符串。如果我们使用一个 for 循环来处理这个字符串元素,所有我们可以挑选出的只是单
个的字符——我们不选择粒度。相比之下, 链表中的元素可以很大也可以很小, 只要我们喜欢。例如:它们可能是段落、句子、短语、单词、字符。所以,链表的优势是我们可以灵活的决定它包含的元素,相应的后续的处理也变得灵活。因此,我们在一段 NLP 代码中可能做的第一件事情就是将一个字符串分词放入一个字符串链表中。相反, 当我们要将结果写入到一个文件或终端,我们通常会将它们格式化为一个字符串。
字符串是不可变的:一旦你创建了一个字符串,就不能改变它。然而,链表是可变的,其内容可以随时修改。作为一个结论,链表支持修改原始值的操作,而不是产生一个新的值。
- #-*-coding: utf-8-*-
- #!/usr/python/bin
- #Filename:NltkTest98,一些关于字符串处理的测试
- from__future__ import division
- importnltk, re, pprint
- fromurllib import urlopen
- fromnltk.corpus import gutenberg
- importtime
- importdatetime
- classNltkTest98:
- def __init__(self):
- print 'Initing...'
- def AlphaTest(self,text):
- raw = gutenberg.raw(text)
- fdist = nltk.FreqDist(ch.lower() for chin raw if ch.isalpha())
- print fdist.keys()
- nt98=NltkTest98()
- text='melville-moby_dick.txt'
- nt98.AlphaTest(text)
3.3使用 Unicode 进行文字处理
1 什么是 Unicode?
Unicode 支持超过一百万种字符。每个字符分配一个编号,称为编码点。文件中的文本都是有特定编码的,所以我们需要一些机制来将文本翻译成 Unicode翻译成 Unicode 叫做解码。相对的,要将 Unicode 写入一个文件或终端,我们首先需要将 Unicode 转化为合适的编码——这种将 Unicode 转化为其它编码的过程叫做编码.
2 从文件中提取已编码文本
3 在 Python 中使用本地编码
在一个 Python 文件中使用你的字符串输入及编辑的标准方法,需要在文件的第一行或第二行中包含字符串:'# -*- coding: utf-8-*-' 。注意windows里面编辑的文件到Linux里面要转码,不然会乱码。
3.4 使用正则表达式检测词组搭配
1 使用基本的元字符
P108正则表达式都是差不多的,pythonli里的,java里的,shell里的都差不多。
2 范围与闭包
T9 系统用于在手机上输入文本。两个或两个以上的词汇以相同的击键顺序输入,这叫做输入法联想提示,这个原来是这样的啊。那么在用户词库里的应该优先权更大一点,这样就符合个性化的要求。
3.5 正则表达式的有益应用
1 提取字符块
2 在字符块上做更多事情
3 查找词干
这表明另一个微妙之处:“*”操作符是“贪婪的”,所以表达式的“.*”部分试图尽可能多的匹配输入的字符串。
regexp= r'^(.*?)(ing|ly|ed|ious|ies|ive|es|s|ment)?$'
^abc表示以abc开始
如果我们要使用括号来指定连接的范围,但不想选择要输出的字符串,必须添加“?:”
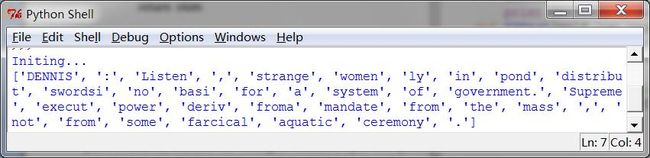
4 搜索已分词文本

这个在做商品评价什么的应该非常有用的,直接抽取附近的形容词然后统计所占比例就可以了。
3.6 规范化文本
去掉所有的词缀以及提取词干的任务等。更进一步的步骤是确保结果形式是字典中确定的词,即叫做词形归并的任务。
1 词干提取器
NLTK 中包括了一些现成的词干提取器,Porter和 Lancaster 词干提取器按照它们自己的规则剥离词缀。NltkTest105.TokenerCompare试了一下,好像是Porter好一些。虽说专业的比较好,但是据说nltk的预处理也就一般,英文的还是一般用Stanford的,可以试着比较一下。
2词形归并
WordNet 词形归并器删除词缀产生的词都是在它的字典中的词。 这个额外的检查过程使词形归并器比刚才提到的词干提取器要慢。
好吧,确实很慢,大概慢一倍以上,不过还是可以接收的,可以考虑和Porter级联使用。
3.7用正则表达式为文本分词
分词是将字符串切割成可识别的构成一块语言数据的语言单元。
1分词的简单方法
2 NLTK 的正则表达式分词器
函数 nltk.regexp_tokenize()与 re.findall() 类似(我们一直在使用它进行分词) 。 然而,nltk.regexp_tokenize()分词效率更高,且不需要特殊处理括号。
3分词的进一步问题
个人觉得,如果不是专业研究分词,可以简单的使用目前已公认的效果最好的分词工具就可以了,不必要为了造飞机去研究冶铁。
3.8分割
1断句
在将文本分词之前,我们需要将它分割成句子。NLTK通过包含 Punkt句子分割器(Kiss & Strunk,2006)简化了这些。
2分词
现在分词的任务变成了一个搜索问题:找到将文本字符串正确分割成词汇的字位串。我们假定学习者接收词,并将它们存储在一个内部词典中。给定一个合适的词典,是能够由词典中的词的序列来重构源文本的。
好吧,默默的在这里决定了,英文用Stanford的分词,中文用NLPIR2014,不在这里纠结了。
3.9格式化:从链表到字符串
1从链表到字符串
''.join(silly)
2字符串与格式
太基础了,不多说
3排列
%s 和%d。我们也可以指定宽度,如%6s,产生一个宽度为 6 的字符串。
4将结果写入文件
存储和内存是需要协调的,当无法提供足够的内存支持时,要有意识的写文件存储中间结果。尤其是训练时间很长的结果,能少算一次就少算一次。
5文本换行
我们可以在 Python 的 textwrap 模块的帮助下采取换行。
- fromtextwrap import fill
- wrapped= fill(output)
- printwrapped
- 代码片段NltkTest105
- #-*- coding: utf-8-*-
- #!/usr/python/bin
- #Filename:NltkTest105,一些关于字符串处理的测试
- from__future__ import division
- importnltk, re, pprint
- fromurllib import urlopen
- fromnltk.corpus import gutenberg, nps_chat
- importtime
- importdatetime
- classNltkTest105:
- def __init__(self):
- print 'Initing...'
- def ReTest(self,lan,regex):
- wordlist = [w for w innltk.corpus.words.words(lan) if w.islower()]
- print [w for w in wordlist ifre.search(regex, w)]
- def T9Test(self,lan,regex):
- wordlist = [w for w innltk.corpus.words.words(lan) if w.islower()]
- print [w for w in wordlist ifre.search(regex, w)]
- def stem(self,word):
- regexp =r'^(.*?)(ing|ly|ed|ious|ies|ive|es|s|ment)?$'
- stem, suffix = re.findall(regexp,word)[0]
- return stem
- def TokensReTest(self):
- moby =nltk.Text(gutenberg.words('melville-moby_dick.txt'))
- print moby.findall(r"(<.*>)
") - def TokenerCompare(self,tokens):
- porter = nltk.PorterStemmer()
- lancaster = nltk.LancasterStemmer()
- wnl = nltk.WordNetLemmatizer()
- print [porter.stem(t) for t in tokens]
- print [lancaster.stem(t) for t intokens]
- print [wnl.lemmatize(t) for t intokens]
- def FileWrTest(self,path,content):
- outFile=open(path,'w')
- for word in sorted(content):
- outFile.write(word+'\n')
- nt105=NltkTest105()
- lan='en'
- regex1='ed$'
- regex2='^[ghi][mno][jlk][def]$'
- #nt105.ReTest(lan,regex1)
- #nt105.T9Test(lan,regex2)
- raw="""DENNIS: Listen, strange women lying in ponds distributingswords\
- is nobasis for a system of government. Supreme executive power derives from\
- amandate from the masses, not from some farcical aquaticceremony."""
- tokens= nltk.word_tokenize(raw)
- #print[nt105.stem(t) for t in tokens]
- #nt105.TokensReTest()
- #nt105.TokenerCompare(tokens)
- words= set(nltk.corpus.genesis.words('english-kjv.txt'))
- path='D:\\PythonSource\\outfiletest.txt'
- nt105.FileWrTest(path,words)
http://python.jobbole.com/81834/
Python 自然语言处理(NLP)工具库汇总
英文出处: pansop.com。欢迎加入 翻译组。
1.NLTK
NLTK 在使用 Python 处理自然语言的工具中处于领先的地位。它提供了 WordNet 这种方便处理词汇资源的接口,以及分类、分词、词干提取、标注、语法分析、语义推理等类库。
网站
http://www.nltk.org/
安装
安装 NLTK: sudo pip install -U nltk
安装 Numpy (可选): sudo pip install -U numpy
安装测试: python then type import nltk
2.Pattern
Pattern 拥有一系列的自然语言处理工具,比如说词性标注工具(Part-Of-Speech Tagger),N元搜索(n-gram search),情感分析(sentiment analysis),WordNet。它也支持机器学习的向量空间模型,聚类,向量机。
网站:
https://github.com/clips/pattern
安装:
pip install pattern
3.TextBlob
TextBlob 是一个处理文本数据的 Python 库。它提供了一个简单的 api 来解决一些常见的自然语言处理任务,例如词性标注、名词短语抽取、情感分析、分类、翻译等等。
网站:
http://textblob.readthedocs.org/en/dev/
安装:
pip install -U textblob
4.Gensim
Gensim 是一个 Python 库,用于对大型语料库进行主题建模、文件索引、相似度检索等。它可以处理大于内存的输入数据。作者说它是“纯文本上无监督的语义建模最健壮、高效、易用的软件。”
网站:
https://github.com/piskvorky/gensim
安装:
pip install -U gensim
5.PyNLPI
它的全称是:Python 自然语言处理库(Python Natural Language Processing Library,音发作: pineapple) 是一个用于自然语言处理任务库。它集合了各种独立或松散互相关的,那些常见的、不常见的、对NLP 任务有用的模块。PyNLPI 可以用来处理 N 元搜索,计算频率表和分布,建立语言模型。它还可以处理向优先队列这种更加复杂的数据结构,或者像 Beam 搜索这种更加复杂的算法。
安装:
LInux:sudo apt-get install pymol
Fedora:yum install pymol
6.spaCy
这是一个商业的开源软件。结合了Python 和Cython 优异的 NLP 工具。是快速的,最先进的自然语言处理工具。
网站:
https://github.com/proycon/pynlpl
安装:
pip install spacy
7.Polyglot
Polyglot 支持大规模多语言应用程序的处理。它支持165种语言的分词,196中语言的辨识,40种语言的专有名词识别,16种语言的词性标注,136种语言的情感分析,137种语言的嵌入,135种语言的形态分析,以及69种语言的翻译。
网站:
https://pypi.python.org/pypi/polyglot
安装
pip install polyglot
8.MontyLingua
MontyLingua 是一个免费的、功能强大的、端到端的英文处理工具。在 MontyLingua 输入原始英文文本 ,输出就会得到这段文本的语义解释。它适用于信息检索和提取,请求处理,问答系统。从英文文本中,它能提取出主动宾元组,形容词、名词和动词短语,人名、地名、事件,日期和时间等语义信息。
网站:
http://web.media.mit.edu/~hugo/montylingua/
9.BLLIP Parser
BLLIP Parser(也叫做 Charniak-Johnson parser)是一个集成了生成成分分析器和最大熵排序的统计自然语言分析器。它包括命令行和python接口。
10.Quepy
Quepy 是一个 Python 框架,提供了将自然语言问题转换成为数据库查询语言中的查询。它可以方便地自定义自然语言中不同类型的问题和数据库查询。所以,通过 Quepy,仅仅修改几行代码,就可以构建你自己的自然语言查询数据库系统。
网站
https://github.com/machinalis/quepy
http://quepy.machinalis.com/
C、http://www.cnblogs.com/rcfeng/p/3918544.html
自然语言处理(1)之NLTK与PYTHON
题记: 由于现在的项目是搜索引擎,所以不由的对自然语言处理产生了好奇,再加上一直以来都想学Python,只是没有机会与时间。碰巧这几天在亚马逊上找书时发现了这本《Python自然语言处理》,瞬间觉得这对我同时入门自然语言处理与Python有很大的帮助。所以最近都会学习这本书,也写下这些笔记。
1. NLTK简述
NLTK模块及功能介绍
| 语言处理任务 | NLTK模块 | 功能描述 |
| 获取语料库 | nltk.corpus | 语料库和词典的标准化接口 |
| 字符串处理 | nltk.tokenize,nltk.stem | 分词、句子分解、提取主干 |
| 搭配研究 | nltk.collocations | t-检验,卡方,点互信息 |
| 词性标示符 | nltk.tag | n-gram,backoff,Brill,HMM,TnT |
| 分类 | nltk.classify,nltk.cluster | 决策树,最大熵,朴素贝叶斯,EM,k-means |
| 分块 | nltk.chunk | 正则表达式,n-gram,命名实体 |
| 解析 | nltk.parse | 图标,基于特征,一致性,概率性,依赖项 |
| 语义解释 | nltk.sem,nltk.inference | λ演算,一阶逻辑,模型检验 |
| 指标评测 | nltk.metrics | 精度,召回率,协议系数 |
| 概率与估计 | nltk.probability | 频率分布,平滑概率分布 |
| 应用 | nltk.app,nltk.chat | 图形化的关键词排序,分析器,WordNet查看器,聊天机器人 |
| 语言学领域的工作 | nltk.toolbox | 处理SIL工具箱格式的数据 |
2. NLTK安装
我的Python版本是2.7.5,NLTK版本2.0.4

1 DESCRIPTION 2 The Natural Language Toolkit (NLTK) is an open source Python library 3 for Natural Language Processing. A free online book is available. 4 (If you use the library for academic research, please cite the book.) 5 6 Steven Bird, Ewan Klein, and Edward Loper (2009). 7 Natural Language Processing with Python. O'Reilly Media Inc. 8 http://nltk.org/book 9 10 @version: 2.0.4
安装步骤跟http://www.nltk.org/install.html 一样
1. 安装Setuptools: http://pypi.python.org/pypi/setuptools
在页面的最下面setuptools-5.7.tar.gz
2. 安装 Pip: 运行 sudo easy_install pip(一定要以root权限运行)
3. 安装 Numpy (optional): 运行 sudo pip install -U numpy
4. 安装 NLTK: 运行 sudo pip install -U nltk
5. 进入python,并输入以下命令
1 192:chapter2 rcf$ python 2 Python 2.7.5 (default, Mar 9 2014, 22:15:05) 3 [GCC 4.2.1 Compatible Apple LLVM 5.0 (clang-500.0.68)] on darwin 4 Type "help", "copyright", "credits" or "license" for more information. 5 >>> import nltk 6 >>> nltk.download()
当出现以下界面进行nltk_data的下载

也可直接到 http://nltk.googlecode.com/svn/trunk/nltk_data/index.xml 去下载数据包,并拖到Download Directory。我就是这么做的。
最后在Python目录运行以下命令以及结果,说明安装已成功
1 from nltk.book import * 2 *** Introductory Examples for the NLTK Book *** 3 Loading text1, ..., text9 and sent1, ..., sent9 4 Type the name of the text or sentence to view it. 5 Type: 'texts()' or 'sents()' to list the materials. 6 text1: Moby Dick by Herman Melville 1851 7 text2: Sense and Sensibility by Jane Austen 1811 8 text3: The Book of Genesis 9 text4: Inaugural Address Corpus 10 text5: Chat Corpus 11 text6: Monty Python and the Holy Grail 12 text7: Wall Street Journal 13 text8: Personals Corpus 14 text9: The Man Who Was Thursday by G . K . Chesterton 1908
3. NLTK的初次使用
现在开始进入正题,由于本人没学过python,所以使用NLTK也就是学习Python的过程。初次学习NLTK主要使用的时NLTK里面自带的一些现有数据,上图中已由显示,这些数据都在nltk.book里面。
3.1 搜索文本
concordance:搜索text1中的monstrous
1 >>> text1.concordance("monstrous")
2 Building index...
3 Displaying 11 of 11 matches:
4 ong the former , one was of a most monstrous size . ... This came towards us ,
5 ON OF THE PSALMS . " Touching that monstrous bulk of the whale or ork we have r
6 ll over with a heathenish array of monstrous clubs and spears . Some were thick
7 d as you gazed , and wondered what monstrous cannibal and savage could ever hav
8 that has survived the flood ; most monstrous and most mountainous ! That Himmal
9 they might scout at Moby Dick as a monstrous fable , or still worse and more de
10 th of Radney .'" CHAPTER 55 Of the Monstrous Pictures of Whales . I shall ere l
11 ing Scenes . In connexion with the monstrous pictures of whales , I am strongly
12 ere to enter upon those still more monstrous stories of them which are to be fo
13 ght have been rummaged out of this monstrous cabinet there is no telling . But
14 of Whale - Bones ; for Whales of a monstrous size are oftentimes cast up dead u
similar:查找text1中与monstrous相关的所有词语
1 >>> text1.similar("monstrous")
2 Building word-context index...
3 abundant candid careful christian contemptible curious delightfully
4 determined doleful domineering exasperate fearless few gamesome
5 horrible impalpable imperial lamentable lazy loving
dispersion_plot:用离散图判断词在文本的位置即偏移量
1 >>> text4.dispersion_plot(["citizens","democracy","freedom","duties","America"])
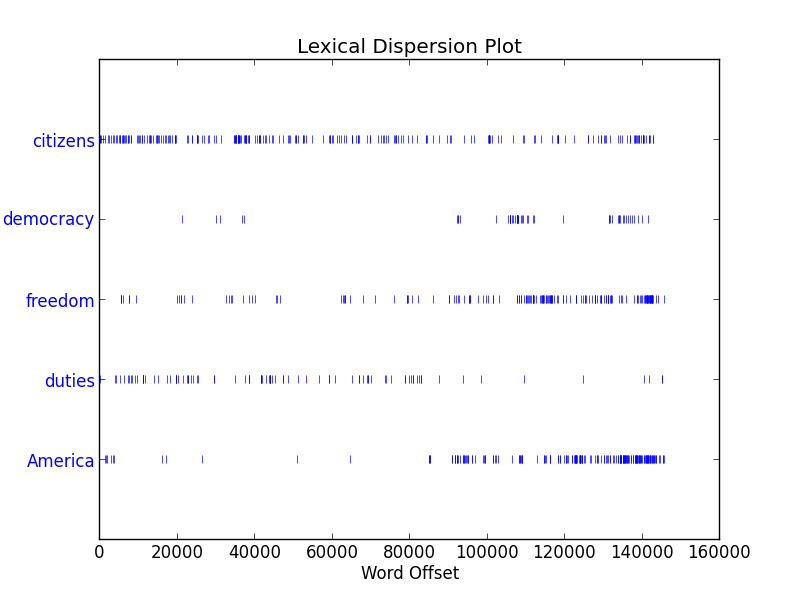
3.2 计数词汇
len:获取长度,即可获取文章的词汇个数,也可获取单个词的长度
1 >>> len(text1) #计算text1的词汇个数 2 260819 3 >>> len(set(text1)) #计算text1 不同的词汇个数 4 19317 5 >>> len(text1[0]) #计算text1 第一个词的长度 6 1
sorted:排序
1 >>> sent1 2 ['Call', 'me', 'Ishmael', '.'] 3 >>> sorted(sent1) 4 ['.', 'Call', 'Ishmael', 'me']
3.3 频率分布
nltk.probability.FreqDist
1 >>> fdist1=FreqDist(text1) #获取text1的频率分布情况 2 >>> fdist1 #text1具有19317个样本,但是总体有260819个值 34 >>> keys=fdist1.keys() 5 >>> keys[:50] #获取text1的前50个样本
6 [',', 'the', '.', 'of', 'and', 'a', 'to', ';', 'in', 'that', "'", '-', 'his', 'it', 'I', 's', 'is', 'he', 'with', 'was', 'as', '"', 'all', 'for', 'this', '!', 'at', 'by', 'but', 'not', '--', 'him', 'from', 'be', 'on', 'so', 'whale', 'one', 'you', 'had', 'have', 'there', 'But', 'or', 'were', 'now', 'which', '?', 'me', 'like']
1 >>> fdist1.items()[:50] #text1的样本分布情况,比如','出现了18713次,总共的词为260819
2 [(',', 18713), ('the', 13721), ('.', 6862), ('of', 6536), ('and', 6024), ('a', 4569), ('to', 4542), (';', 4072), ('in', 3916), ('that', 2982), ("'", 2684), ('-', 2552), ('his', 2459), ('it', 2209), ('I', 2124), ('s', 1739), ('is', 1695), ('he', 1661), ('with', 1659), ('was', 1632), ('as', 1620), ('"', 1478), ('all', 1462), ('for', 1414), ('this', 1280), ('!', 1269), ('at', 1231), ('by', 1137), ('but', 1113), ('not', 1103), ('--', 1070), ('him', 1058), ('from', 1052), ('be', 1030), ('on', 1005), ('so', 918), ('whale', 906), ('one', 889), ('you', 841), ('had', 767), ('have', 760), ('there', 715), ('But', 705), ('or', 697), ('were', 680), ('now', 646), ('which', 640), ('?', 637), ('me', 627), ('like', 624)]
1 >>> fdist1.hapaxes()[:50] #text1的样本只出现一次的词 2 ['!\'"', '!)"', '!*', '!--"', '"...', "',--", "';", '):', ');--', ',)', '--\'"', '---"', '---,', '."*', '."--', '.*--', '.--"', '100', '101', '102', '103', '104', '105', '106', '107', '108', '109', '11', '110', '111', '112', '113', '114', '115', '116', '117', '118', '119', '12', '120', '121', '122', '123', '124', '125', '126', '127', '128', '129', '130']
3 >>> fdist1['!\'"']
4 1
1 >>> fdist1.plot(50,cumulative=True) #画出text1的频率分布图

3.4 细粒度的选择词
1 >>> long_words=[w for w in set(text1) if len(w) > 15] #获取text1内样本词汇长度大于15的词并按字典序排序 2 >>> sorted(long_words) 3 ['CIRCUMNAVIGATION', 'Physiognomically', 'apprehensiveness', 'cannibalistically', 'characteristically', 'circumnavigating', 'circumnavigation', 'circumnavigations', 'comprehensiveness', 'hermaphroditical', 'indiscriminately', 'indispensableness', 'irresistibleness', 'physiognomically', 'preternaturalness', 'responsibilities', 'simultaneousness', 'subterraneousness', 'supernaturalness', 'superstitiousness', 'uncomfortableness', 'uncompromisedness', 'undiscriminating', 'uninterpenetratingly'] 4 >>> fdist1=FreqDist(text1) #获取text1内样本词汇长度大于7且出现次数大于7的词并按字典序排序
5 >>> sorted([wforwin set(text5) if len(w) > 7 and fdist1[w] > 7]) 6 ['American', 'actually', 'afternoon', 'anything', 'attention', 'beautiful', 'carefully', 'carrying', 'children', 'commanded', 'concerning', 'considered', 'considering', 'difference', 'different', 'distance', 'elsewhere', 'employed', 'entitled', 'especially', 'everything', 'excellent', 'experience', 'expression', 'floating', 'following', 'forgotten', 'gentlemen', 'gigantic', 'happened', 'horrible', 'important', 'impossible', 'included', 'individual', 'interesting', 'invisible', 'involved', 'monsters', 'mountain', 'occasional', 'opposite', 'original', 'originally', 'particular', 'pictures', 'pointing', 'position', 'possibly', 'probably', 'question', 'regularly', 'remember', 'revolving', 'shoulders', 'sleeping', 'something', 'sometimes', 'somewhere', 'speaking', 'specially', 'standing', 'starting', 'straight', 'stranger', 'superior', 'supposed', 'surprise', 'terrible', 'themselves', 'thinking', 'thoughts', 'together', 'understand', 'watching', 'whatever', 'whenever', 'wonderful', 'yesterday', 'yourself']
3.5 词语搭配和双连词
用bigrams()可以实现双连词
1 >>> bigrams(['more','is','said','than','done'])
2 [('more', 'is'), ('is', 'said'), ('said', 'than'), ('than', 'done')]
3 >>> text1.collocations()
4 Building collocations list
5 Sperm Whale; Moby Dick; White Whale; old man; Captain Ahab; sperm
6 whale; Right Whale; Captain Peleg; New Bedford; Cape Horn; cried Ahab;
7 years ago; lower jaw; never mind; Father Mapple; cried Stubb; chief
8 mate; white whale; ivory leg; one hand
3.6 NLTK频率分类中定义的函数
| 例子 | 描述 |
| fdist=FreqDist(samples) | 创建包含给定样本的频率分布 |
| fdist.inc(sample) | 增加样本 |
| fdist['monstrous'] | 计数给定样本出现的次数 |
| fdist.freq('monstrous') | 样本总数 |
| fdist.N() | 以频率递减顺序排序的样本链表 |
| fdist.keys() | 以频率递减的顺序便利样本 |
| for sample in fdist: | 数字最大的样本 |
| fdist.max() | 绘制频率分布表 |
| fdist.tabulate() | 绘制频率分布图 |
| fdist.plot() | 绘制积累频率分布图 |
| fdist.plot(cumulative=True) | 绘制积累频率分布图 |
| fdist1 | 测试样本在fdist1中出现的样本是否小于fdist2 |
最后看下text1的类情况. 使用type可以查看变量类型,使用help()可以获取类的属性以及方法。以后想要获取具体的方法可以使用help(),这个还是很好用的。
1 >>> type(text1) 23 >>> help('nltk.text.Text') 4 Help on class Text in nltk.text: 5 6 nltk.text.Text = class Text(__builtin__.object) 7 | A wrapper around a sequence of simple (string) tokens, which is 8 | intended to support initial exploration of texts (via the 9 | interactive console). Its methods perform a variety of analyses 10 | on the text's contexts (e.g., counting, concordancing, collocation 11 | discovery), and display the results. If you wish to write a 12 | program which makes use of these analyses, then you should bypass 13 | the ``Text`` class, and use the appropriate analysis function or 14 | class directly instead. 15 | 16 | A ``Text`` is typically initialized from a given document or 17 | corpus. E.g.: 18 | 19 | >>> import nltk.corpus 20 | >>> from nltk.text import Text 21 | >>> moby = Text(nltk.corpus.gutenberg.words('melville-moby_dick.txt')) 22 | 23 | Methods defined here: 24 | 25 | __getitem__(self, i) 26 | 27 | __init__(self, tokens, name=None) 28 | Create a Text object. 29 | 30 | :param tokens: The source text. 31 | :type tokens: sequence of str 32 | 33 | __len__(self) 34 | 35 | __repr__(self) 36 | :return: A string representation of this FreqDist. 37 | :rtype: string 38 | 39 | collocations(self, num=20, window_size=2) 40 | Print collocations derived from the text, ignoring stopwords. 41 | 42 | :seealso: find_collocations 43 | :param num: The maximum number of collocations to print. 44 | :type num: int 45 | :param window_size: The number of tokens spanned by a collocation (default=2) 46 | :type window_size: int 47 | 48 | common_contexts(self, words, num=20) 49 | Find contexts where the specified words appear; list 50 | most frequent common contexts first. 51 | 52 | :param word: The word used to seed the similarity search 53 | :type word: str 54 | :param num: The number of words to generate (default=20) 55 | :type num: int 56 | :seealso: ContextIndex.common_contexts()
4. 语言理解的技术
1. 词意消歧
2. 指代消解
3. 自动生成语言
4. 机器翻译
5. 人机对话系统
6. 文本的含义
5. 总结
虽然是初次接触Python,NLTK,但是我已经觉得他们的好用以及方便,接下来就会深入的学习他们。
D、http://www.cnblogs.com/yuxc/archive/2011/08/24/2152667.html
5.2 Tagged Corpora 标注语料库
Representing Tagged Tokens 表示标注的语言符号
By convention in NLTK, a tagged token is represented using a tuple consisting of the token and the tag. We can create one of these special tuples from the standard string representation of a tagged token, using the function str2tuple():
|
We can construct a list of tagged tokens directly from a string. The first step is to tokenize the string to access the individual word/tag strings, and then to convert each of these into a tuple (using str2tuple()).
|
Reading Tagged Corpora 读取已标注的语料库
Several of the corpora included with NLTK have been tagged for their part-of-speech. Here's an example of what you might see if you opened a file from the Brown Corpus with a text editor:
The/at Fulton/np-tl County/nn-tl Grand/jj-tl Jury/nn-tl said/vbd Friday/nr an/at investigation/nn of/in Atlanta's/np$ recent/jj primary/nn election/nn produced/vbd / no/at evidence/nn ''/'' that/cs any/dti irregularities/nns took/vbd place/nn ./.
Other corpora use a variety of formats for storing part-of-speech tags. NLTK's corpus readers provide a uniform interface so that you don't have to be concerned with the different file formats. In contrast with the file extract shown above, the corpus reader for the Brown Corpus represents the data as shown below. Note that part-of-speech tags have been converted to uppercase, since this has become standard practice(标准惯例) since the Brown Corpus was published.
|
Whenever a corpus contains tagged text, the NLTK corpus interface will have a tagged_words() method. Here are some more examples, again using the output format illustrated for the Brown Corpus:
|
Not all corpora employ the same set of tags; see the tagset help functionality and the readme() methods mentioned above for documentation. Initially we want to avoid the complications of these tagsets, so we use a built-in mapping to a simplified tagset:
|
Tagged corpora for several other languages are distributed with NLTK, including Chinese, Hindi, Portuguese, Spanish, Dutch and Catalan. These usually contain non-ASCII text, and Python always displays this in hexadecimal when printing a larger structure such as a list.
|
If your environment is set up correctly, with appropriate editors and fonts, you should be able to display individual strings in a human-readable way. For example, Figure 5.1 shows data accessed using nltk.corpus.indian.
Figure 5.1: POS-Tagged Data from Four Indian Languages: Bangla, Hindi, Marathi, and Telugu
If the corpus is also segmented into sentences, it will have a tagged_sents() method that divides up the tagged words into sentences rather than presenting them as one big list. This will be useful when we come to developing automatic taggers, as they are trained and tested on lists of sentences, not words.
Tagged corpora use many different conventions for tagging words. To help us get started, we will be looking at a simplified tagset (shown in Table 5.1).
| Tag |
Meaning |
Examples |
| ADJ |
adjective |
new, good, high, special, big, local |
| ADV |
adverb |
really, already, still, early, now |
| CNJ |
conjunction |
and, or, but, if, while, although |
| DET |
determiner |
the, a, some, most, every, no |
| EX |
existential |
there, there's |
| FW |
foreign word |
dolce, ersatz, esprit, quo, maitre |
| MOD |
modal verb |
will, can, would, may, must, should |
| N |
noun |
year, home, costs, time, education |
| NP |
proper noun |
Alison, Africa, April, Washington |
| NUM |
number |
twenty-four, fourth, 1991, 14:24 |
| PRO |
pronoun |
he, their, her, its, my, I, us |
| P |
preposition |
on, of, at, with, by, into, under |
| TO |
the word to |
to |
| UH |
interjection |
ah, bang, ha, whee, hmpf, oops |
| V |
verb |
is, has, get, do, make, see, run |
| VD |
past tense |
said, took, told, made, asked |
| VG |
present participle |
making, going, playing, working |
| VN |
past participle |
given, taken, begun, sung |
| WH |
wh determiner |
who, which, when, what, where, howTable 5.1: Simplified Part-of-Speech Tagset |
Let's see which of these tags are the most common in the news category of the Brown corpus:
|
Note
![]() Your Turn: Plot the above frequency distribution using tag_fd.plot(cumulative=True). What percentage of words are tagged using the first five tags of the above list? 60%
Your Turn: Plot the above frequency distribution using tag_fd.plot(cumulative=True). What percentage of words are tagged using the first five tags of the above list? 60%
We can use these tags to do powerful searches using a graphical POS-concordance tool nltk.app.concordance(). Use it to search for any combination of words and POS tags, e.g. N N N N, hit/VD, hit/VN, or the ADJ man.
Nouns 名词
Nouns generally refer to people, places, things, or concepts, e.g.: woman, Scotland, book, intelligence. Nouns can appear after determiners and adjectives, and can be the subject or object of the verb, (名词可以出现在限定词和形容词之后,并且可以做动词的主语或宾语)as shown in Table 5.2.
| Word |
After a determiner |
Subject of the verb |
| woman |
the woman who I saw yesterday ... |
the woman sat down |
| Scotland |
the Scotland I remember as a child ... |
Scotland has five million people |
| book |
the book I bought yesterday ... |
this book recounts the colonization of Australia |
| intelligence |
the intelligence displayed by the child ... |
Mary's intelligence impressed her teachersTable 5.2: Syntactic Patterns involving some Nouns |
The simplified noun tags are N for common nouns like book, and NP for proper nouns like Scotland.
Let's inspect some tagged text to see what parts of speech occur before a noun, with the most frequent ones first. To begin with, we construct a list of bigrams whose members are themselves word-tag pairs such as (('The', 'DET'), ('Fulton', 'NP')) and (('Fulton', 'NP'), ('County', 'N')). Then we construct a FreqDist from the tag parts of the bigrams.
|
(a,b)也就是(('The', 'DET'), ('Fulton', 'NP')),如果b[1]==’N’,则给出前面这个词的词性a[1]
This confirms our assertion that nouns occur after determiners and adjectives, including numeral adjectives (tagged as NUM).
Verbs 动词
Verbs are words that describe events and actions, e.g. fall, eat in Table 5.3. In the context of a sentence, verbs typically express a relation involving the referents of one or more noun phrases.
| Word |
Simple |
With modifiers and adjuncts (italicized) |
| fall |
Rome fell |
Dot com stocks suddenly fell like a stone |
| eat |
Mice eat cheese |
John ate the pizza with gustoTable 5.3: Syntactic Patterns involving some Verbs |
What are the most common verbs in news text? Let's sort all the verbs by frequency:
|
Note that the items being counted in the frequency distribution are word-tag pairs. Since words and tags are paired, we can treat the word as a condition and the tag as an event, and initialize a conditional frequency distribution with a list of condition-event pairs. This lets us see a frequency-ordered list of tags given a word:
|
We can reverse the order of the pairs, so that the tags are the conditions, and the words are the events(词作为条件,标签作为事件). Now we can see likely words for a given tag:
|
To clarify the distinction between VD (past tense) and VN (past participle), let's find words which can be both VD and VN, and see some surrounding text:
|
In this case, we see that the past participle of kicked is preceded by a form of the auxiliary verb have. Is this generally true?
Note
![]() Your Turn: Given the list of past participles specified by cfd2['VN'].keys(), try to collect a list of all the word-tag pairs that immediately precede items in that list.
Your Turn: Given the list of past participles specified by cfd2['VN'].keys(), try to collect a list of all the word-tag pairs that immediately precede items in that list.
Adjectives and Adverbs 形容词和副词
Two other important word classes are adjectives and adverbs. Adjectives describe nouns, and can be used as modifiers (e.g. large in the large pizza), or in predicates (e.g. the pizza is large). English adjectives can have internal structure (e.g. fall+ing in the falling stocks). Adverbs modify verbs to specify the time, manner, place or direction of the event described by the verb (e.g. quickly in the stocks fell quickly). Adverbs may also modify adjectives (e.g. really in Mary's teacher was really nice).
English has several categories of closed class words in addition to prepositions, such as articles (also often called determiners) (e.g., the, a), modals (e.g., should, may), and personal pronouns (e.g., she, they). Each dictionary and grammar classifies these words differently.
Note
![]() Your Turn: If you are uncertain about some of these parts of speech, study them using nltk.app.concordance(), or watch some of the Schoolhouse Rock! grammar videos available at YouTube, or consult the Further Reading section at the end of this chapter.
Your Turn: If you are uncertain about some of these parts of speech, study them using nltk.app.concordance(), or watch some of the Schoolhouse Rock! grammar videos available at YouTube, or consult the Further Reading section at the end of this chapter.
Unsimplified Tags 未简化的标签
Let's find the most frequent nouns of each noun part-of-speech type. The program in Example 5.2 finds all tags starting with NN, and provides a few example words for each one. You will see that there are many variants of NN; the most important contain $ for possessive nouns, S for plural nouns (since plural nouns typically end ins) and P for proper nouns. In addition, most of the tags have suffix modifiers: -NC for citations, -HL for words in headlines and -TL for titles (a feature of Brown tabs).
|
||
|
||
| Example 5.2 (code_findtags.py): Program to Find the Most Frequent Noun Tags |
When we come to constructing part-of-speech taggers later in this chapter, we will use the unsimplified tags.
Exploring Tagged Corpora 探索标注的语料库
Let's briefly return to the kinds of exploration of corpora we saw in previous chapters, this time exploiting POS tags.
Suppose we're studying the word often and want to see how it is used in text. We could ask to see the words that follow often
|
However, it's probably more instructive use the tagged_words() method to look at the part-of-speech tag of the following words:
|
Notice that the most high-frequency parts of speech following often are verbs. Nouns never appear in this position (in this particular corpus).
Next, let's look at some larger context, and find words involving particular sequences of tags and words (in this case "
|
||
|
||
| Example 5.3 (code_three_word_phrase.py): Figure 5.3: Searching for Three-Word Phrases Using POS Tags |
Finally, let's look for words that are highly ambiguous as to their part of speech tag. Understanding why such words are tagged as they are in each context can help us clarify the distinctions between the tags.
|
Note
![]() Your Turn: Open the POS concordance tool nltk.app.concordance() and load the complete Brown Corpus (simplified tagset). Now pick some of the above words and see how the tag of the word correlates with the context of the word. E.g. search for near to see all forms mixed together, near/ADJ to see it used as an adjective, near N to see just those cases where a noun follows, and so forth.
Your Turn: Open the POS concordance tool nltk.app.concordance() and load the complete Brown Corpus (simplified tagset). Now pick some of the above words and see how the tag of the word correlates with the context of the word. E.g. search for near to see all forms mixed together, near/ADJ to see it used as an adjective, near N to see just those cases where a noun follows, and so forth.
E、https://cs.umd.edu/~nau/cmsc421/part-of-speech-tagging.pdf
http://idiom.ucsd.edu/~rlevy/lign256/winter2008/ppt/lecture_6_pos_tagging_I.pdf
CC - Coordinating conjunction • CD - Cardinal number • DT - Determiner • EX - Existential there • FW - Foreign word • IN - Preposition or subordinating conjunction • JJ - Adjective • JJR - Adjective, comparative • JJS - Adjective, superlative • LS - List item marker • MD - Modal • NN - Noun, singular or mass • NNS - Noun, plural • NNP - Proper noun, singular • NNPS - Proper noun, plural • PDT - Predeterminer • POS - Possessive ending • PRP - Personal pronoun • PRP$ - Possessive pronoun • RB - Adverb • RBR - Adverb, comparative • RBS - Adverb, superlative • RP - Particle • SYM - Symbol • TO - to • UH - Interjection • VB - Verb, base form • VBD - Verb, past tense • VBG - Verb, gerund or present participle • VBN - Verb, past participle • VBP - Verb, non-3rd person singular present • VBZ - Verb, 3rd person singular present • WDT - Wh-determiner • WP - Wh-pronoun • WP$ - Possessive wh-pronoun • WRB - Wh-adverb
CC - Coordinating conjunction • CD - Cardinal number • DT - Determiner • EX - Existential there • FW - Foreign word • IN - Preposition or subordinating conjunction • JJ - Adjective • JJR - Adjective, comparative • JJS - Adjective, superlative • LS - List item marker • MD - Modal • NN - Noun, singular or mass • NNS - Noun, plural • NNP - Proper noun, singular • NNPS - Proper noun, plural • PDT - Predeterminer • POS - Possessive ending • PRP - Personal pronoun • PRP$ - Possessive pronoun • RB - Adverb • RBR - Adverb, comparative • RBS - Adverb, superlative • RP - Particle • SYM - Symbol • TO - to • UH - Interjection • VB - Verb, base form • VBD - Verb, past tense • VBG - Verb, gerund or present participle • VBN - Verb, past participle • VBP - Verb, non-3rd person singular present • VBZ - Verb, 3rd person singular present • WDT - Wh-determiner • WP - Wh-pronoun • WP$ - Possessive wh-pronoun • WRB Wh-adverb however whenever where why
F、http://www.cnblogs.com/XDJjy/p/5111167.html
python 安装nltk,使用(英文分词处理,词干化等)(Green VPN)
安装pip命令之后:
sudo pip install -U pyyaml nltk
import nltk nltk.download()
等待ing
目前访问不了,故使用Green VPN
http://www.evergreen.com/ubuntu-pptp--setting/
nltk使用
http://www.cnblogs.com/yuxc/archive/2011/08/29/2157415.html
http://blog.csdn.net/huyoo/article/details/12188573
http://www.52nlp.cn/tag/nltk
1.空格进行英文分词.split(python自带)
>>> slower 'we all like the book' >>> ssplit = slower.split() >>> ssplit ['we', 'all', 'like', 'the', 'book'] >>>
或
>>> import nltk >>> s = u"我们都Like the book" >>> m = [word for word in nltk.tokenize.word_tokenize(s)] >>> for word in m: ... print word ... 我们都Like the book
或
>>> tokens = nltk.word_tokenize(s) >>> tokens [u'\u6211\u4eec\u90fdLike', u'the', u'book'] >>> for word in tokens File "", line 1 for word in tokens ^ SyntaxError: invalid syntax >>> for word in tokens: ... print word ... 我们都Like the book
2.词性标注
>>> tagged = nltk.pos_tag(tokens) >>> for word in tagged: ... print word ... (u'\u6211\u4eec\u90fdLike', 'IN') (u'the', 'DT') (u'book', 'NN') >>>
3.句法分析
>>> entities= nltk.chunk.ne_chunk(tagged)
>>> entities
Tree('S', [(u'\u6211\u4eec\u90fdLike', 'IN'), (u'the', 'DT'), (u'book', 'NN')])
>>>
---------------------------------------------------------------------------------------------------------------------------------------------------------
4.转换为小写(Python自带)
>>> s 'We all like the book' >>> slower = s.lower() >>> slower 'we all like the book' >>>
5.空格进行英文分词.split(python自带)
>>> slower 'we all like the book' >>> ssplit = slower.split() >>> ssplit ['we', 'all', 'like', 'the', 'book'] >>>
6.标号与单词分离
>>> s 'we all like the book,it\xe2\x80\x98s so interesting.' >>> s = 'we all like the book, it is so interesting.' >>> wordtoken = nltk.tokenize.word_tokenize(s) >>> wordtoken ['we', 'all', 'like', 'the', 'book', ',', 'it', 'is', 'so', 'interesting', '.'] >>> wordtoken = nltk.word_tokenize(s) >>> wordtoken ['we', 'all', 'like', 'the', 'book', ',', 'it', 'is', 'so', 'interesting', '.'] >>> wordsplit = s.split() >>> wordsplit ['we', 'all', 'like', 'the', 'book,', 'it', 'is', 'so', 'interesting.'] >>>
7.去停用词(nltk自带127个英文停用词)
>>> wordEngStop = nltk.corpus.stopwords.words('english')
>>> wordEngStop
[u'i', u'me', u'my', u'myself', u'we', u'our', u'ours', u'ourselves', u'you', u'your', u'yours', u'yourself', u'yourselves', u'he', u'him', u'his', u'himself', u'she', u'her', u'hers', u'herself', u'it', u'its', u'itself', u'they', u'them', u'their', u'theirs', u'themselves', u'what', u'which', u'who', u'whom', u'this', u'that', u'these', u'those', u'am', u'is', u'are', u'was', u'were', u'be', u'been', u'being', u'have', u'has', u'had', u'having', u'do', u'does', u'did', u'doing', u'a', u'an', u'the', u'and', u'but', u'if', u'or', u'because', u'as', u'until', u'while', u'of', u'at', u'by', u'for', u'with', u'about', u'against', u'between', u'into', u'through', u'during', u'before', u'after', u'above', u'below', u'to', u'from', u'up', u'down', u'in', u'out', u'on', u'off', u'over', u'under', u'again', u'further', u'then', u'once', u'here', u'there', u'when', u'where', u'why', u'how', u'all', u'any', u'both', u'each', u'few', u'more', u'most', u'other', u'some', u'such', u'no', u'nor', u'not', u'only', u'own', u'same', u'so', u'than', u'too', u'very', u's', u't', u'can', u'will', u'just', u'don', u'should', u'now']
>>> len(wordEngStop)
127
>>>
>>> len(wordEngStop) 127 >>> s 'we all like the book, it is so interesting.' >>> wordtoken ['we', 'all', 'like', 'the', 'book', ',', 'it', 'is', 'so', 'interesting', '.'] >>> for word in wordtoken: ... if not word in wordEngStop: ... print word ... like book , interesting . >>>
8.去标点符号
>>> english_punctuations = [',', '.', ':', ';', '?', '(', ')', '[', ']', '!', '@', '#', '%', '$', '*']
>>> wordtoken
['we', 'all', 'like', 'the', 'book', ',', 'it', 'is', 'so', 'interesting', '.']
>>> for word in wordtoken:
... if not word in english_punctuations:
... print word
...
we
all
like
the
book
it
is
so
interesting
>>>
9.词干化
“我们对这些英文单词词干化(Stemming),NLTK提供了好几个相关工具接口可供选择,具体参考这个页面:http://nltk.org/api/nltk.stem.html , 可选的工具包括Lancaster Stemmer, Porter Stemmer等知名的英文Stemmer。这里我们使用LancasterStemmer:” 来自:我爱自然语言处理 http://www.52nlp.cn/%E5%A6%82%E4%BD%95%E8%AE%A1%E7%AE%97%E4%B8%A4%E4%B8%AA%E6%96%87%E6%A1%A3%E7%9A%84%E7%9B%B8%E4%BC%BC%E5%BA%A6%E4%B8%89
http://lutaf.com/212.htm 词干化的主流方法
http://blog.sina.com.cn/s/blog_6d65717d0100z4hu.html
>>> from nltk.stem.lancaster import LancasterStemmer >>> st = LancasterStemmer() >>> wordtoken ['we', 'all', 'like', 'the', 'book', ',', 'it', 'is', 'so', 'interesting', '.'] >>> st.stem(wordtoken) Traceback (most recent call last): File "", line 1, in File "/usr/local/lib/python2.7/dist-packages/nltk/stem/lancaster.py", line 195, in stem AttributeError: 'list' object has no attribute 'lower' >>> for word in wordtoken: ... print st.stem(word) ... we al lik the book , it is so interest . >>>
两者各有优缺点
>>> from nltk.stem import PorterStemmer >>> wordtoken ['we', 'all', 'like', 'the', 'book', ',', 'it', 'is', 'so', 'interesting', '.'] >>> PorterStemmer().stem(wordtoken) Traceback (most recent call last): File "", line 1, in File "/usr/local/lib/python2.7/dist-packages/nltk/stem/porter.py", line 632, in stem AttributeError: 'list' object has no attribute 'lower' >>> PorterStemmer().stem('all') u'all' >>> for word in wordtoken: ... print PorterStemmer().stem(word) ... we all like the book , it is so interest . >>> PorterStemmer().stem("better") u'better' >>> PorterStemmer().stem("supplies") u'suppli' >>> st.stem('supplies') u'supply' >>>
# -*- coding:utf8 -*-
import nltk
import os
wordEngStop = nltk.corpus.stopwords.words('english')
english_punctuations = [',', '.', ':', ';', '?', '(', ')', '[', ']', '!', '@', '#', '%', '$', '*','=','abstract=', '{', '}']
porterStem=nltk.stem.PorterStemmer()
lancasterStem=nltk.stem.lancaster.LancasterStemmer()
fin = open('/home/xdj/myOutput.txt', 'r')
fout = open('/home/xdj/myOutputLancasterStemmer.txt','w')
for eachLine in fin:
eachLine = eachLine.lower().decode('utf-8', 'ignore') #小写
tokens = nltk.word_tokenize(eachLine) #分词(与标点分开)
wordLine = ''
for word in tokens:
if not word in english_punctuations: #去标点
if not word in wordEngStop: #去停用词
#word = porterStem.stem(word)
word = lancasterStem.stem(word)
wordLine+=word+' '
fout.write(wordLine.encode('utf-8')+'\n')
fin.close()
fout.close()
G、http://blog.csdn.net/huyoo/article/details/12188573
python的nltk中文使用和学习资料汇总帮你入门提高
版权声明:本文为博主原创文章,未经博主允许不得转载。
目录(?)[+]
nltk是一个Python工具包, 用来处理和自然语言处理相关的东西. 包括分词(tokenize), 词性标注(POS), 文本分类, 等等现成的工具.
1. nltk的安装
资料1.1: 黄聪:Python+NLTK自然语言处理学习(一):环境搭建 http://www.cnblogs.com/huangcong/archive/2011/08/29/2157437.html 这个图文并茂, 步骤清晰, 值得一看. 我想我没必要再重新写一遍了, 因为我当时也是按照他这样做的.
资料1.2: 把python自然语言处理的nltk_data打包到360云盘,然后共享给朋友们 http://www.cnblogs.com/ToDoToTry/archive/2013/01/18/2865941.html 这个是作者将接近300M的nltk_data上传到百度云了, 我觉得, 可以试试下载, 毕竟使用资料1中nltk自带的download()方法, 从官方网站下载所有的数据包需要很长时间.
补充: 有人说, 这个下载的链接已经失效了, 我把我用的nltk2.0的data目录里的zip文件打包传到百度云盘了, 290多M, 上传我费了好多时间, 你们可以去下载: http://pan.baidu.com/s/1hq7UUFU
资料1.3: Ubuntu上安装NLTK出现的问题与解决方法 http://www.cnblogs.com/mengshu-lbq/archive/2012/09/19/2694135.html 需要的看看吧
资料1.4: 安装nltk遇到的小问题 http://blog.upupbug.com/?p=106
资料1.5 安装nltk后导入语料的时候出错, 一般是一些依赖包没安装 http://blog.tianya.cn/blogger/post_show.asp?BlogID=762305&PostID=8954744
资料1.6 NLTK中文化處理及文字筆畫音調剖析工具整合套件 http://tm.itc.ntnu.edu.tw/CNLP/?q=node/5 台湾一个大学对nltk的介绍
资料1.7 windows下如何安装NLTK,并使用模块nltk?http://zhidao.baidu.com/question/567881533.html
2. nltk初步使用入门
资料2.2: 黄聪:Python+NLTK自然语言处理学习(二):常用方法(similar、common_contexts、generate) http://www.cnblogs.com/huangcong/archive/2011/08/29/2158054.html
这篇, 初步介绍了如何开始使用nltk的语料和他的一些常用方法. 有点python基础的可以直接看了.之所以放在这里, 还是因为, 只有安装好了才可以进行到这一步.
资料2.3 黄聪:Python+NLTK自然语言处理学习(三):计算机自动学习机制 http://www.cnblogs.com/huangcong/archive/2011/08/29/2158447.html
这一篇也挺浅显易懂的.
资料2.4 python中nltk.parse_cfg是干什么用的 求例子 http://zhidao.baidu.com/question/552627368.html
3.nltk初中级应用
资料3.1: 可爱的 Python: 自然语言工具包入门 http://www.ibm.com/developerworks/cn/linux/l-cpnltk/
这个是ibm的砖家写的资料, 但是这个不能作为入门资料, 可以归结到初级应用资料. 对于那些动手能力弱的人, 这个文章真的不是那么好懂的, 所以不适合入门看, 而适合那些喜欢写代码, 喜欢鼓捣折腾的人看.
资料3.2 词性标注 http://blog.csdn.net/fxjtoday/article/details/5841453 这篇文章介绍了默认的词性标注类(比如, 所有的词都标注为名词), 基于规则标注词性, 基于正则表达式标注词性, n-gram标注词性等等.
资料3.3: Classify Text With NLTK http://blog.csdn.net/fxjtoday/article/details/5862041 别看标题是英文的, 实际上内容是中英文混合的, 不过这个比上面一篇简单些. 主要就是使用nltk对一些姓名 性别进行训练, 并预测测试语料中的姓名是啥性别. 这篇文章能够让你对 分类, 样本特征稍微有个初步入门.
资料3.4 使用nltk从非结构化数据中抽取信息 http://blog.csdn.net/fxjtoday/article/details/5871386 这篇主要介绍了命名实体识别
4.使用nltk来处理中文资料
nltk 怎么样使用中文?这是个大问题。这么个工具目前只能比较好的处理英文和其他的一些拉丁语系,谁让别人的单词与单词之间有个空格隔开呢!中文汉字一个挨一个的,nltk在分词这一关就过不去了,分词没法分,剩下的就都做不了。唯一能做的, 就是对网上现有的中文语料进行处理,这些语料都分好了词,可以使用nltk进行类似与英文的处理。
python处理中文首先需要设置一下文本的编码, 文件的首行加上: #coding utf-8 这个是给python解释器识别的,然后文件保存的时候,还需要保存为utf-8的编码。
这些编码设置完了, ntlk还是处理不了中文。
nltk处理中文的第一步障碍就是中文资料不是分好词的, 词语与词语之间没有空格。要使用nltk对中文进行处理, 首先的第一步就是中文分词(台湾叫中文断词)。
目前python中文分词的包,我推荐使用结巴分词。 使用结巴分词,之后,就可以对输出文本使用nltk进行相关处理。
当然中文分词, 不应该成为使用nltk的障碍,或许很多人认为,既然用nltk,那么nltk就应该支持中文。但是我们得认清现实,现实就是nltk就是不支持处理中文,因此,这个给国内很多自然语言处理的研究人员有了研究的空间了,nltk既然没做中文分词,那么中国人就应该自己做了这个。一个口碑比较好的中文分词工具就是ICTCLAS中文分词。
当然,我个人觉得中国人自己开发的纯python实现的结巴分词也不错。
总的来说,nltk不提供中文分词,不应该纠结于此,并止步不前,我们完全可以使用其他的中文分词工具,将需要处理的资料分好词,然后再使用nltk进行处理,因此,这里就不多说中文分词的那点事了。如果你因为中文分词而分心,并转向到中文分词的研究之中,那么你就掉入了另外一个深坑之中。牢记本文的主题是nltk。当然需要多啰嗦一点的就是,nltk的默认词性标注集使用的是Penn Treebank 的词性标注集,因此,你选用中文分词模块的时候,最好能够使用和penn词性标注集差不多的中文分词工具,当然,不一样也没事。
资料4.1 使用python结巴分词对中文资料进行分词 https://github.com/fxsjy/jieba 结巴分词的github主页
资料4.2 基于python的中文分词的实现及应用 http://www.cnblogs.com/appler/archive/2012/02/02/2335834.html
资料4.3 对Python中文分词模块结巴分词算法过程的理解和分析 http://ddtcms.com/blog/archive/2013/2/4/69/jieba-fenci-suanfa-lijie/
资料4.4 宾州中文树库标记以及其解释, Penn Chinese Treebank Tag Set http://blog.csdn.net/neutblue/article/details/7375085
5.nltk的高级应用入门
啥叫高级啊? 就是基础掌握了之后,开始运用实际工作了,就叫高级。比如什么统计推荐,评分,机器翻译,文本分类,舆情监控等等都是高级应用。
下面是些入门资料。
资料1: 通过nltk的机器学习方法实现论坛垃圾帖的过滤 http://blog.sina.com.cn/s/blog_630c58cb0100vkw3.html
资料2:利用nltk建立一个简单的词库 http://blog.sina.com.cn/s/blog_630c58cb0100vkix.html
资料3:利用概率分布进行关联规则挖掘 http://blog.sina.com.cn/s/blog_630c58cb0100vll0.html
6. nltk的精通
何谓精通? 精通就是熟练的表达你的想法。
何谓精通一个工具? 就是你想做什么, 你就能用这个工具顺利的完成。do everything you want with nltk.
至于如何精通,建议多看英文资料和多动手操练。nltk官方文档, 一些参与nltk的大学研究机构,北大,清华的语言研究以及国际语言研究机构acl所发的论文等等。
假设你目前真的熟练的掌握了nltk的各种玩法了,那么, 你精通的标志就是改造nltk, 使它功能更强,更优,更快,更方便。
比如:
6.1 集成结巴分词到nltk的分词器之中
6.2 在国内多弄几个地方,放置nltk_data数据包,方便大家下载
6.3 给nltk提供语料
等等,剩下的由你来补充。
最后说一句: nltk的中文资料确实不多,坑爹吧?相信很多人卡在了中文分词那一步。。。坚定的要求用nltk进行中文分词的朋友,还是先跳过这一步吧. 另外, 喜欢python和自然语言处理的朋友可以加我的QQ群:Python自然语言处理群(220373876), 欢迎来参与讨论.
H、http://www.cnblogs.com/yuxc/archive/2011/08/29/2157415.html
I、http://www.cnblogs.com/baiboy/p/nltk1.html
【NLP】干货!Python NLTK结合stanford NLP工具包进行文本处理
干货!详述Python NLTK下如何使用stanford NLP工具包
作者:白宁超
2016年11月6日19:28:43
摘要:NLTK是由宾夕法尼亚大学计算机和信息科学使用python语言实现的一种自然语言工具包,其收集的大量公开数据集、模型上提供了全面、易用的接口,涵盖了分词、词性标注(Part-Of-Speech tag, POS-tag)、命名实体识别(Named Entity Recognition, NER)、句法分析(Syntactic Parse)等各项 NLP 领域的功能。而Stanford NLP 是由斯坦福大学的 NLP 小组开源的 Java 实现的 NLP 工具包,同样对 NLP 领域的各个问题提供了解决办法。斯坦福大学的 NLP 小组是世界知名的研究小组,能将 NLTK 和 Stanford NLP 这两个工具包结合起来使用,那对于自然语言开发者是再好不过的!在 2004 年 Steve Bird 在 NLTK 中加上了对 Stanford NLP 工具包的支持,通过调用外部的 jar 文件来使用 Stanford NLP 工具包的功能。本分析显得非常方便好用。本文主要介绍NLTK(Natural language Toolkit)下配置安装Stanford NLP ,以及对Standford NLP核心模块进行演示,使读者简单易懂的学习本章知识,后续会继续采用大秦帝国语料对分词、词性标注、命名实体识别、句法分析、句法依存分析进行详细演示。关于python基础知识,可以参看 【Python五篇慢慢弹】系列文章( 本文原创编著,转载注明出处: 干货!详述Python NLTK下如何使用stanford NLP工具包)
目录
【Python NLP】干货!详述Python NLTK下如何使用stanford NLP工具包(1)
【Python NLP】Python 自然语言处理工具小结(2)
【Python NLP】Python NLTK 走进大秦帝国(3)
【Python NLP】Python NLTK获取文本语料和词汇资源(4)
【Python NLP】Python NLTK处理原始文本(5)
1 NLTK和StandfordNLP简介
NLTK:由宾夕法尼亚大学计算机和信息科学使用python语言实现的一种自然语言工具包,其收集的大量公开数据集、模型上提供了全面、易用的接口,涵盖了分词、词性标注(Part-Of-Speech tag, POS-tag)、命名实体识别(Named Entity Recognition, NER)、句法分析(Syntactic Parse)等各项 NLP 领域的功能。
Stanford NLP:由斯坦福大学的 NLP 小组开源的 Java 实现的 NLP 工具包,同样对 NLP 领域的各个问题提供了解决办法。斯坦福大学的 NLP 小组是世界知名的研究小组,能将 NLTK 和 Stanford NLP 这两个工具包结合起来使用,那对于自然语言开发者是再好不过的!在 2004 年 Steve Bird 在 NLTK 中加上了对 Stanford NLP 工具包的支持,通过调用外部的 jar 文件来使用 Stanford NLP 工具包的功能。本分析显得非常方便好用。
本文在主要介绍NLTK 中提供 Stanford NLP 中的以下几个功能:
- 中英文分词: StanfordTokenizer
- 中英文词性标注: StanfordPOSTagger
- 中英文命名实体识别: StanfordNERTagger
- 中英文句法分析: StanfordParser
- 中英文依存句法分析: StanfordDependencyParser, StanfordNeuralDependencyParser
2 安装配置过程中注意事项
本文以Python 3.5.2和java version "1.8.0_111"版本进行配置,具体安装需要注意以下几点:
- Stanford NLP 工具包需要 Java 8 及之后的版本,如果出错请检查 Java 版本
- 本文的配置都是以 Stanford NLP 3.6.0 为例,如果使用的是其他版本,请注意替换相应的文件名
- 本文的配置过程以 NLTK 3.2 为例,如果使用 NLTK 3.1,需要注意该旧版本中 StanfordSegmenter 未实现,其余大致相同
- 下面的配置过程是具体细节可以参照:http://nlp.stanford.edu/software/
3 StandfordNLP必要工具包下载
必要包下载:只需要下载以下3个文件就够了,stanfordNLTK文件里面就是StanfordNLP工具包在NLTK中所依赖的jar包和相关文件
- stanfordNLTK :自己将所有需要的包和相关文件已经打包在一起了,下面有具体讲解
- Jar1.8 :如果你本机是Java 8以上版本,可以不用下载了
- NLTK :这个工具包提供Standford NLP接口
以上文件下载后,Jar如果是1.8的版本可以不用下载,另外两个压缩包下载到本地,解压后拷贝文件夹到你的python安装主路径下,然后cmd进入NLTK下通过python setup.py install即可。后面操作讲路径简单修改即可。(如果不能正常分词等操作,查看python是否是3.2以上版本,java是否是8以后版本,jar环境变量是否配置正确)
StanfordNLTK目录结构如下:(从各个压缩文件已经提取好了,如果读者感兴趣,下面有各个功能的源码文件)
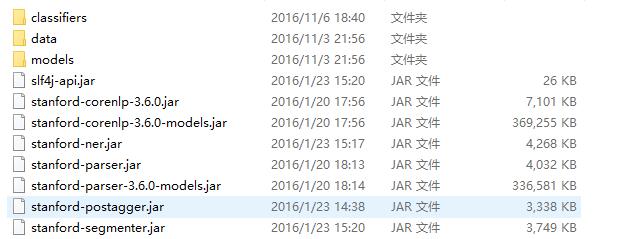
- 分词依赖:stanford-segmenter.jar、 slf4j-api.jar、data文件夹相关子文件
- 命名实体识别依赖:classifiers、stanford-ner.jar
- 词性标注依赖:models、stanford-postagger.jar
- 句法分析依赖:stanford-parser.jar、stanford-parser-3.6.0-models.jar、classifiers
- 依存语法分析依赖:stanford-parser.jar、stanford-parser-3.6.0-models.jar、classifiers
压缩包下载和源码分析:
- 分词压缩包:StanfordSegmenter和StanfordTokenizer:下载stanford-segmenter-2015-12-09.zip (version 3.6.0) 解压获取目录中的 stanford-segmenter-3.6.0.jar 拷贝为 stanford-segmenter.jar和 slf4j-api.jar
- 词性标注压缩包:下载stanford-postagger-full-2015-12-09.zip (version 3.6.0) 解压获取stanford-postagger.jar
- 命名实体识别压缩包:下载stanford-ner-2015-12-09.zip (version 3.6.0) ,将解压获取stanford-ner.jar和classifiers文件
- 句法分析、句法依存分析:下载stanford-parser-full-2015-12-09.zip (version 3.6.0) 解压获取stanford-parser.jar 和 stanford-parser-3.6.0-models.jar
4 StandfordNLP相关核心操作
4.1 分词
StanfordSegmenter 中文分词:下载52nlp改过的NLTK包nltk-develop ,解压后将其拷贝到你的python目录下,进去E:\Python\nltk-develop采用python 编辑器打开setup.py文件,F5运行,输入以下代码:
|
1
2
3
4
5
6
7
8
9
10
11
|
>>>
from
nltk.tokenize.stanford_segmenter import StanfordSegmenter
>>> segmenter = StanfordSegmenter(
path_to_jar=r
"E:\tools\stanfordNLTK\jar\stanford-segmenter.jar"
,
path_to_slf4j=r
"E:\tools\stanfordNLTK\jar\slf4j-api.jar"
,
path_to_sihan_corpora_dict=r
"E:\tools\stanfordNLTK\jar\data"
,
path_to_model=r
"E:\tools\stanfordNLTK\jar\data\pku.gz"
,
path_to_dict=r
"E:\tools\stanfordNLTK\jar\data\dict-chris6.ser.gz"
)
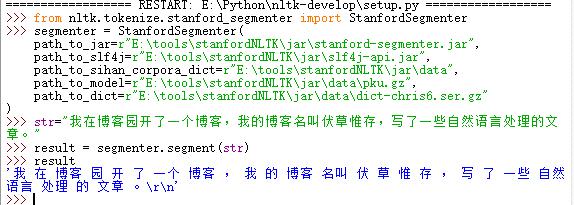
>>> str=
"我在博客园开了一个博客,我的博客名叫伏草惟存,写了一些自然语言处理的文章。"
>>> result = segmenter.segment(str)
>>> result
|
执行结果:
程序解读:StanfordSegmenter 的初始化参数说明:
- path_to_jar: 用来定位jar包,本程序分词依赖stanford-segmenter.jar(注: 其他所有 Stanford NLP 接口都有 path_to_jar 这个参数。)
- path_to_slf4j: 用来定位slf4j-api.jar作用于分词
- path_to_sihan_corpora_dict: 设定为 stanford-segmenter-2015-12-09.zip 解压后目录中的 data 目录, data 目录下有两个可用模型 pkg.gz 和 ctb.gz 需要注意的是,使用 StanfordSegmenter 进行中文分词后,其返回结果并不是 list ,而是一个字符串,各个汉语词汇在其中被空格分隔开。
StanfordTokenizer 英文分词 :相关参考资料
|
1
2
3
4
5
6
7
8
|
Python 3.5.2 (v3.5.2:4def2a2901a5, Jun 25 2016, 22:01:18) [MSC v.1900 32 bit (Intel)]
on
win32
Type
"copyright"
,
"credits"
or
"license()"
for
more information.
>>>
from
nltk.tokenize import StanfordTokenizer
>>> tokenizer = StanfordTokenizer(path_to_jar=r
"E:\tools\stanfordNLTK\jar\stanford-parser.jar"
)
>>> sent =
"Good muffins cost $3.88\nin New York. Please buy me\ntwo of them.\nThanks."
>>> print(tokenizer.tokenize(sent))
[
'Good'
,
'muffins'
,
'cost'
,
'$'
,
'3.88'
,
'in'
,
'New'
,
'York'
,
'.'
,
'Please'
,
'buy'
,
'me'
,
'two'
,
'of'
,
'them'
,
'.'
,
'Thanks'
,
'.'
]
>>>
|
执行结果:

4.2 命名实体识别
StanfordNERTagger 英文命名实体识别
|
1
2
3
4
|
>>>
from
nltk.tag import StanfordNERTagger
>>> eng_tagger = StanfordNERTagger(model_filename=r
'E:\tools\stanfordNLTK\jar\classifiers\english.all.3class.distsim.crf.ser.gz'
,path_to_jar=r
'E:\tools\stanfordNLTK\jar\stanford-ner.jar'
)
>>> print(eng_tagger.tag(
'Rami Eid is studying at Stony Brook University in NY'
.split()))
[(
'Rami'
,
'PERSON'
), (
'Eid'
,
'PERSON'
), (
'is'
,
'O'
), (
'studying'
,
'O'
), (
'at'
,
'O'
), (
'Stony'
,
'ORGANIZATION'
), (
'Brook'
,
'ORGANIZATION'
), (
'University'
,
'ORGANIZATION'
), (
'in'
,
'O'
), (
'NY'
,
'O'
)]
|
运行结果:

StanfordNERTagger 中文命名实体识别
|
1
2
3
4
5
6
|
>>> result
'四川省 成都 信息 工程 大学 我 在 博客 园 开 了 一个 博客 , 我 的 博客 名叫 伏 草 惟 存 , 写 了 一些 自然语言 处理 的 文章 。\r\n'
>>>
from
nltk.tag import StanfordNERTagger
>>> chi_tagger = StanfordNERTagger(model_filename=r
'E:\tools\stanfordNLTK\jar\classifiers\chinese.misc.distsim.crf.ser.gz'
,path_to_jar=r
'E:\tools\stanfordNLTK\jar\stanford-ner.jar'
)
>>>
for
word, tag
in
chi_tagger.tag(result.split()):
print(word,tag)
|
运行结果:

4.3 词性标注
StanfordPOSTagger 英文词性标注
|
1
2
3
|
>>>
from
nltk.tag import StanfordPOSTagger
>>> eng_tagger = StanfordPOSTagger(model_filename=r
'E:\tools\stanfordNLTK\jar\models\english-bidirectional-distsim.tagger'
,path_to_jar=r
'E:\tools\stanfordNLTK\jar\stanford-postagger.jar'
)
>>> print(eng_tagger.tag(
'What is the airspeed of an unladen swallow ?'
.split()))
|
运行结果:

StanfordPOSTagger 中文词性标注
|
1
2
3
4
5
|
>>>
from
nltk.tag import StanfordPOSTagger
>>> chi_tagger = StanfordPOSTagger(model_filename=r
'E:\tools\stanfordNLTK\jar\models\chinese-distsim.tagger'
,path_to_jar=r
'E:\tools\stanfordNLTK\jar\stanford-postagger.jar'
)
>>> result
'四川省 成都 信息 工程 大学 我 在 博客 园 开 了 一个 博客 , 我 的 博客 名叫 伏 草 惟 存 , 写 了 一些 自然语言 处理 的 文章 。\r\n'
>>> print(chi_tagger.tag(result.split()))
|
运行结果:


4.4 句法分析:参考文献资料
StanfordParser英文语法分析
|
1
2
3
|
>>>
from
nltk.parse.stanford import StanfordParser
>>> eng_parser = StanfordParser(r
"E:\tools\stanfordNLTK\jar\stanford-parser.jar"
,r
"E:\tools\stanfordNLTK\jar\stanford-parser-3.6.0-models.jar"
,r
"E:\tools\stanfordNLTK\jar\classifiers\englishPCFG.ser.gz"
)
>>> print(list(eng_parser.parse(
"the quick brown fox jumps over the lazy dog"
.split())))
|
运行结果:

StanfordParser 中文句法分析
|
1
2
3
4
|
>>>
from
nltk.parse.stanford import StanfordParser
>>> chi_parser = StanfordParser(r
"E:\tools\stanfordNLTK\jar\stanford-parser.jar"
,r
"E:\tools\stanfordNLTK\jar\stanford-parser-3.6.0-models.jar"
,r
"E:\tools\stanfordNLTK\jar\classifiers\chinesePCFG.ser.gz"
)
>>> sent = u
'北海 已 成为 中国 对外开放 中 升起 的 一 颗 明星'
>>> print(list(chi_parser.parse(sent.split())))
|
运行结果:

4.5 依存句法分析
StanfordDependencyParser 英文依存句法分析
|
1
2
3
4
5
|
>>>
from
nltk.parse.stanford import StanfordDependencyParser
>>> eng_parser = StanfordDependencyParser(r
"E:\tools\stanfordNLTK\jar\stanford-parser.jar"
,r
"E:\tools\stanfordNLTK\jar\stanford-parser-3.6.0-models.jar"
,r
"E:\tools\stanfordNLTK\jar\classifiers\englishPCFG.ser.gz"
)
>>> res = list(eng_parser.parse(
"the quick brown fox jumps over the lazy dog"
.split()))
>>>
for
row
in
res[0].triples():
print(row)
|
运行结果:

StanfordDependencyParser 中文依存句法分析
|
1
2
3
4
5
|
>>>
from
nltk.parse.stanford import StanfordDependencyParser
>>> chi_parser = StanfordDependencyParser(r
"E:\tools\stanfordNLTK\jar\stanford-parser.jar"
,r
"E:\tools\stanfordNLTK\jar\stanford-parser-3.6.0-models.jar"
,r
"E:\tools\stanfordNLTK\jar\classifiers\chinesePCFG.ser.gz"
)
>>> res = list(chi_parser.parse(u
'四川 已 成为 中国 西部 对外开放 中 升起 的 一 颗 明星'
.split()))
>>>
for
row
in
res[0].triples():
print(row)
|
运行结果:

5 参考文献和知识扩展
- NLTK官方网站
- NLTK的API
- NLTK中使用斯坦福中文分词器
- GitHub上NLTK源码
J、http://www.jb51.net/article/63732.htm
什么是词干提取?
在语言形态学和信息检索里,词干提取是去除词缀得到词根的过程─—得到单词最一般的写法。对于一个词的形态词根,词干并不需要完全相同;相关的词映射到同一个词干一般能得到满意的结果,即使该词干不是词的有效根。从1968年开始在计算机科学领域出现了词干提取的相应算法。很多搜索引擎在处理词汇时,对同义词采用相同的词干作为查询拓展,该过程叫做归并。
一个面向英语的词干提取器,例如,要识别字符串“cats”、“catlike”和“catty”是基于词根“cat”;“stemmer”、“stemming”和“stemmed”是基于词根“stem”。一根词干提取算法可以简化词 “fishing”、“fished”、“fish”和“fisher” 为同一个词根“fish”。
技术方案的选择
Python和R是数据分析的两种主要语言;相对于R,Python更适合有大量编程背景的数据分析初学者,尤其是已经掌握Python语言的程序员。所以我们选择了Python和NLTK库(Natual Language Tookit)作为文本处理的基础框架。此外,我们还需要一个数据展示工具;对于一个数据分析师来说,数据库的冗繁安装、连接、建表等操作实在是不适合进行快速的数据分析,所以我们使用Pandas作为结构化数据和分析工具。
环境搭建
我们使用的是Mac OS X,已预装Python 2.7.
安装NLTK
|
1
|
sudo
pip
install
nltk
|
安装Pandas
|
1
|
sudo
pip
install
pandas
|
对于数据分析来说,最重要的是分析结果,iPython notebook是必备的一款利器,它的作用在于可以保存代码的执行结果,例如数据表格,下一次打开时无需重新运行即可查看。
安装iPython notebook
|
1
|
sudo
pip
install
ipython
|
创建一个工作目录,在工作目录下启动iPython notebook,服务器会开启http://127.0.0.1:8080页面,并将创建的代码文档保存在工作目录之下。
|
1
2
3
|
mkdir
Codes
cd
Codes
ipython notebook
|
文本处理
数据表创建
使用Pandas创建数据表 我们使用得到的样本数据,建立DataFrame——Pandas中一个支持行、列的2D数据结构。
|
1
2
3
4
5
6
|
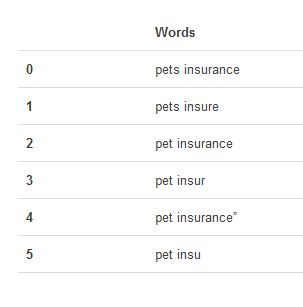
from
pandas
import
DataFrame
import
pandas as pd
d
=
[
'pets insurance'
,
'pets insure'
,
'pet insurance'
,
'pet insur'
,
'pet insurance"'
,
'pet insu'
]
df
=
DataFrame(d)
df.columns
=
[
'Words'
]
df
|
显示结果
NLTK分词器介绍
RegexpTokenizer:正则表达式分词器,使用正则表达式对文本进行处理,就不多作介绍。
PorterStemmer:波特词干算法分词器,原理可看这里:http://snowball.tartarus.org/algorithms/english/stemmer.html
第一步,我们创建一个去除标点符号等特殊字符的正则表达式分词器:
|
1
2
|
import
nltk
tokenizer
=
nltk.RegexpTokenizer(r
'w+'
)
|
接下来,对准备好的数据表进行处理,添加词干将要写入的列,以及统计列,预设默认值为1:
|
1
2
|
df[
"Stemming Words"
]
=
""
df[
"Count"
]
=
1
|
读取数据表中的Words列,使用波特词干提取器取得词干:
|
1
2
3
4
5
6
|
j
=
0
while
(j <
=
5
):
for
word
in
tokenizer.tokenize(df[
"Words"
][j]):
df[
"Stemming Words"
][j]
=
df[
"Stemming Words"
][j]
+
" "
+
nltk.PorterStemmer().stem_word(word)
j
+
=
1
df
|
Good!到这一步,我们已经基本上实现了文本处理,结果显示如下:
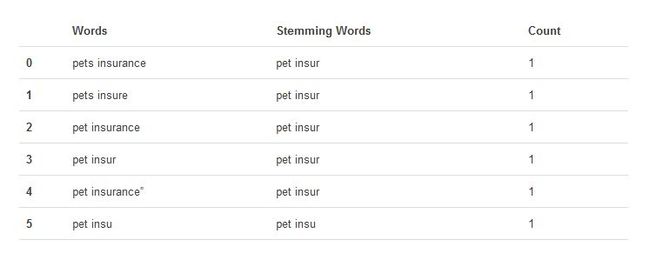
分组统计
在Pandas中进行分组统计,将统计表格保存到一个新的DataFrame结构uniqueWords中:
|
1
2
|
uniqueWords
=
df.groupby([
'Stemming Words'
], as_index
=
False
).
sum
().sort([
'Count'
])
uniqueWords
|

注意到了吗?依然还有一个pet insu未能成功处理。
拼写检查
对于用户拼写错误的词语,我们首先想到的是拼写检查,针对Python我们可以使用enchant:
|
1
|
sudo
pip
install
enchant
|
使用enchant进行拼写错误检查,得到推荐词:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
import
enchant
from
nltk.metrics
import
edit_distance
class
SpellingReplacer(
object
):
def
__init__(
self
, dict_name
=
'en'
, max_dist
=
2
):
self
.spell_dict
=
enchant.
Dict
(dict_name)
self
.max_dist
=
2
def
replace(
self
, word):
if
self
.spell_dict.check(word):
return
word
suggestions
=
self
.spell_dict.suggest(word)
if
suggestions
and
edit_distance(word, suggestions[
0
]) <
=
self
.max_dist:
return
suggestions[
0
]
else
:
return
word
from
replacers
import
SpellingReplacer
replacer
=
SpellingReplacer()
replacer.replace(
'insu'
)
'insu'
|
但是,结果依然不是我们预期的“insur”。能不能换种思路呢?
算法特殊性
用户输入非常重要的特殊性来自于行业和使用场景。采取通用的英语大词典来进行拼写检查,无疑是行不通的,并且某些词语恰恰是拼写正确,但本来却应该是另一个词。但是,我们如何把这些背景信息和数据分析关联起来呢?
经过一番思考,我认为最重要的参考库恰恰就在已有的数据分析结果中,我们回来看看:

已有的5个“pet insur”,其实就已经给我们提供了一份数据参考,我们已经可以对这份数据进行聚类,进一步除噪。
相似度计算
对已有的结果进行相似度计算,将满足最小偏差的数据归类到相似集中:
|
1
2
3
4
5
6
7
8
9
10
11
12
|
import
Levenshtein
minDistance
=
0.8
distance
=
-
1
lastWord
=
""
j
=
0
while
(j <
1
):
lastWord
=
uniqueWords[
"Stemming Words"
][j]
distance
=
Levenshtein.ratio(uniqueWords[
"Stemming Words"
][j], uniqueWords[
"Stemming Words"
][j
+
1
])
if
(distance > minDistance):
uniqueWords[
"Stemming Words"
][j]
=
uniqueWords[
"Stemming Words"
][j
+
1
]
j
+
=
1
uniqueWords
|
查看结果,已经匹配成功!
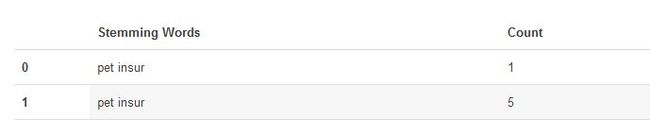
最后一步,重新对数据结果进行分组统计:
|
1
2
|
uniqueWords
=
uniqueWords.groupby([
'Stemming Words'
], as_index
=
False
).
sum
()
uniqueWords
|
到此,我们已经完成了初步的文本处理。
K、http://blog.sina.com.cn/s/blog_a1e412090102w8vs.html
NLTK学习笔记——Classify模块(3)
 (2015-11-26 23:50:28)
转载▼
(2015-11-26 23:50:28)
转载▼
标签: 分类 |
分类: NLTK |
本节介绍我的分类实战过程。
- 分词,程序采用了jieba的精确分词,可以试一试其他的分词模式
- 特征,程序采用词频以及是否含有该词为特征,或许有点片面,还需考量
- 训练集太少,测试集太大,导致结果有误差
- 程序有错误,因为有的职位是不存在的,而程序都将这类的职位归为13,即“市场总监”,因此还需要仔细推敲
- 为防中文编码错误,需要在程序的第一行加:#coding:utf-8
- 为使代码正常运行,需要引入几个包:
import jieba #调用结巴分词器
from nltk import FreqDistfrom nltk import classifyfrom nltk.classify.naivebayes import NaiveBayesClassifier
个人实战过程到此结束,有问题的地方户在后期的学习中慢慢改进。
L、http://www.nltk.org/api/nltk.stem.html
nltk.stem package¶
Submodules
nltk.stem.api module
-
class
nltk.stem.api.StemmerI[source] -
Bases:
objectA processing interface for removing morphological affixes from words. This process is known as stemming.
-
stem(token)[source] -
Strip affixes from the token and return the stem.
Parameters: token (str) – The token that should be stemmed.
-
nltk.stem.isri module
ISRI Arabic Stemmer
The algorithm for this stemmer is described in:
Taghva, K., Elkoury, R., and Coombs, J. 2005. Arabic Stemming without a root dictionary. Information Science Research Institute. University of Nevada, Las Vegas, USA.
The Information Science Research Institute’s (ISRI) Arabic stemmer shares many features with the Khoja stemmer. However, the main difference is that ISRI stemmer does not use root dictionary. Also, if a root is not found, ISRI stemmer returned normalized form, rather than returning the original unmodified word.
Additional adjustments were made to improve the algorithm:
1- Adding 60 stop words. 2- Adding the pattern (تفاعيل) to ISRI pattern set. 3- The step 2 in the original algorithm was normalizing all hamza. This step is discarded because it increases the word ambiguities and changes the original root.
-
class
nltk.stem.isri.ISRIStemmer[source] -
Bases:
nltk.stem.api.StemmerIISRI Arabic stemmer based on algorithm: Arabic Stemming without a root dictionary. Information Science Research Institute. University of Nevada, Las Vegas, USA.
A few minor modifications have been made to ISRI basic algorithm. See the source code of this module for more information.
isri.stem(token) returns Arabic root for the given token.
The ISRI Stemmer requires that all tokens have Unicode string types. If you use Python IDLE on Arabic Windows you have to decode text first using Arabic ‘1256’ coding.
-
end_w5(word)[source] -
ending step (word of length five)
-
end_w6(word)[source] -
ending step (word of length six)
-
norm(word, num=3)[source] -
normalization: num=1 normalize diacritics num=2 normalize initial hamza num=3 both 1&2
-
pre1(word)[source] -
normalize short prefix
-
pre32(word)[source] -
remove length three and length two prefixes in this order
-
pro_w4(word)[source] -
process length four patterns and extract length three roots
-
pro_w53(word)[source] -
process length five patterns and extract length three roots
-
pro_w54(word)[source] -
process length five patterns and extract length four roots
-
pro_w6(word)[source] -
process length six patterns and extract length three roots
-
pro_w64(word)[source] -
process length six patterns and extract length four roots
-
stem(token)[source] -
Stemming a word token using the ISRI stemmer.
-
suf1(word)[source] -
normalize short sufix
-
suf32(word)[source] -
remove length three and length two suffixes in this order
-
waw(word)[source] -
remove connective ‘و’ if it precedes a word beginning with ‘و’
-
nltk.stem.lancaster module
A word stemmer based on the Lancaster stemming algorithm. Paice, Chris D. “Another Stemmer.” ACM SIGIR Forum 24.3 (1990): 56-61.
-
class
nltk.stem.lancaster.LancasterStemmer[source] -
Bases:
nltk.stem.api.StemmerILancaster Stemmer
>>> from nltk.stem.lancaster import LancasterStemmer >>> st = LancasterStemmer() >>> st.stem('maximum') # Remove "-um" when word is intact 'maxim' >>> st.stem('presumably') # Don't remove "-um" when word is not intact 'presum' >>> st.stem('multiply') # No action taken if word ends with "-ply" 'multiply' >>> st.stem('provision') # Replace "-sion" with "-j" to trigger "j" set of rules 'provid' >>> st.stem('owed') # Word starting with vowel must contain at least 2 letters 'ow' >>> st.stem('ear') # ditto 'ear' >>> st.stem('saying') # Words starting with consonant must contain at least 3 'say' >>> st.stem('crying') # letters and one of those letters must be a vowel 'cry' >>> st.stem('string') # ditto 'string' >>> st.stem('meant') # ditto 'meant' >>> st.stem('cement') # ditto 'cem'-
parseRules(rule_tuple)[source] -
Validate the set of rules used in this stemmer.
-
rule_tuple= ('ai*2.', 'a*1.', 'bb1.', 'city3s.', 'ci2>', 'cn1t>', 'dd1.', 'dei3y>', 'deec2ss.', 'dee1.', 'de2>', 'dooh4>', 'e1>', 'feil1v.', 'fi2>', 'gni3>', 'gai3y.', 'ga2>', 'gg1.', 'ht*2.', 'hsiug5ct.', 'hsi3>', 'i*1.', 'i1y>', 'ji1d.', 'juf1s.', 'ju1d.', 'jo1d.', 'jeh1r.', 'jrev1t.', 'jsim2t.', 'jn1d.', 'j1s.', 'lbaifi6.', 'lbai4y.', 'lba3>', 'lbi3.', 'lib2l>', 'lc1.', 'lufi4y.', 'luf3>', 'lu2.', 'lai3>', 'lau3>', 'la2>', 'll1.', 'mui3.', 'mu*2.', 'msi3>', 'mm1.', 'nois4j>', 'noix4ct.', 'noi3>', 'nai3>', 'na2>', 'nee0.', 'ne2>', 'nn1.', 'pihs4>', 'pp1.', 're2>', 'rae0.', 'ra2.', 'ro2>', 'ru2>', 'rr1.', 'rt1>', 'rei3y>', 'sei3y>', 'sis2.', 'si2>', 'ssen4>', 'ss0.', 'suo3>', 'su*2.', 's*1>', 's0.', 'tacilp4y.', 'ta2>', 'tnem4>', 'tne3>', 'tna3>', 'tpir2b.', 'tpro2b.', 'tcud1.', 'tpmus2.', 'tpec2iv.', 'tulo2v.', 'tsis0.', 'tsi3>', 'tt1.', 'uqi3.', 'ugo1.', 'vis3j>', 'vie0.', 'vi2>', 'ylb1>', 'yli3y>', 'ylp0.', 'yl2>', 'ygo1.', 'yhp1.', 'ymo1.', 'ypo1.', 'yti3>', 'yte3>', 'ytl2.', 'yrtsi5.', 'yra3>', 'yro3>', 'yfi3.', 'ycn2t>', 'yca3>', 'zi2>', 'zy1s.')
-
stem(word)[source] -
Stem a word using the Lancaster stemmer.
-
unicode_repr()
-
nltk.stem.porter module
Porter Stemmer
This is the Porter stemming algorithm. It follows the algorithm presented in
Porter, M. “An algorithm for suffix stripping.” Program 14.3 (1980): 130-137.
with some optional deviations that can be turned on or off with the mode argument to the constructor.
Martin Porter, the algorithm’s inventor, maintains a web page about the algorithm at
http://www.tartarus.org/~martin/PorterStemmer/
which includes another Python implementation and other implementations in many languages.
-
class
nltk.stem.porter.PorterStemmer(mode='NLTK_EXTENSIONS')[source] -
Bases:
nltk.stem.api.StemmerIA word stemmer based on the Porter stemming algorithm.
Porter, M. “An algorithm for suffix stripping.” Program 14.3 (1980): 130-137.See http://www.tartarus.org/~martin/PorterStemmer/ for the homepage of the algorithm.
Martin Porter has endorsed several modifications to the Porter algorithm since writing his original paper, and those extensions are included in the implementations on his website. Additionally, others have proposed further improvements to the algorithm, including NLTK contributors. There are thus three modes that can be selected by passing the appropriate constant to the class constructor’s mode attribute:
PorterStemmer.ORIGINAL_ALGORITHM - Implementation that is faithful to the original paper.
Note that Martin Porter has deprecated this version of the algorithm. Martin distributes implementations of the Porter Stemmer in many languages, hosted at:
http://www.tartarus.org/~martin/PorterStemmer/and all of these implementations include his extensions. He strongly recommends against using the original, published version of the algorithm; only use this mode if you clearly understand why you are choosing to do so.
PorterStemmer.MARTIN_EXTENSIONS - Implementation that only uses the modifications to the
algorithm that are included in the implementations on Martin Porter’s website. He has declared Porter frozen, so the behaviour of those implementations should never change.PorterStemmer.NLTK_EXTENSIONS (default) - Implementation that includes further improvements devised by
NLTK contributors or taken from other modified implementations found on the web.For the best stemming, you should use the default NLTK_EXTENSIONS version. However, if you need to get the same results as either the original algorithm or one of Martin Porter’s hosted versions for compability with an existing implementation or dataset, you can use one of the other modes instead.
-
MARTIN_EXTENSIONS= 'MARTIN_EXTENSIONS'
-
NLTK_EXTENSIONS= 'NLTK_EXTENSIONS'
-
ORIGINAL_ALGORITHM= 'ORIGINAL_ALGORITHM'
-
stem(word)[source]
-
unicode_repr()
-
-
nltk.stem.porter.demo()[source] -
A demonstration of the porter stemmer on a sample from the Penn Treebank corpus.
nltk.stem.regexp module
-
class
nltk.stem.regexp.RegexpStemmer(regexp, min=0)[source] -
Bases:
nltk.stem.api.StemmerIA stemmer that uses regular expressions to identify morphological affixes. Any substrings that match the regular expressions will be removed.
>>> from nltk.stem import RegexpStemmer >>> st = RegexpStemmer('ing$|s$|e$|able$', min=4) >>> st.stem('cars') 'car' >>> st.stem('mass') 'mas' >>> st.stem('was') 'was' >>> st.stem('bee') 'bee' >>> st.stem('compute') 'comput' >>> st.stem('advisable') 'advis'Parameters: - regexp (str or regexp) – The regular expression that should be used to identify morphological affixes.
- min (int) – The minimum length of string to stem
-
stem(word)[source]
-
unicode_repr()
nltk.stem.rslp module
-
class
nltk.stem.rslp.RSLPStemmer[source] -
Bases:
nltk.stem.api.StemmerIA stemmer for Portuguese.
>>> from nltk.stem import RSLPStemmer >>> st = RSLPStemmer() >>> # opening lines of Erico Verissimo's "Música ao Longe" >>> text = ''' ... Clarissa risca com giz no quadro-negro a paisagem que os alunos ... devem copiar . Uma casinha de porta e janela , em cima duma ... coxilha .''' >>> for token in text.split(): ... print(st.stem(token)) clariss risc com giz no quadro-negr a pais que os alun dev copi . uma cas de port e janel , em cim dum coxilh .-
apply_rule(word, rule_index)[source]
-
read_rule(filename)[source]
-
stem(word)[source]
-
nltk.stem.snowball module
Snowball stemmers
This module provides a port of the Snowball stemmers developed by Martin Porter.
There is also a demo function: snowball.demo().
-
class
nltk.stem.snowball.DanishStemmer(ignore_stopwords=False)[source] -
Bases:
nltk.stem.snowball._ScandinavianStemmerThe Danish Snowball stemmer.
Variables: - __vowels – The Danish vowels.
- __consonants – The Danish consonants.
- __double_consonants – The Danish double consonants.
- __s_ending – Letters that may directly appear before a word final ‘s’.
- __step1_suffixes – Suffixes to be deleted in step 1 of the algorithm.
- __step2_suffixes – Suffixes to be deleted in step 2 of the algorithm.
- __step3_suffixes – Suffixes to be deleted in step 3 of the algorithm.
Note: A detailed description of the Danish stemming algorithm can be found underhttp://snowball.tartarus.org/algorithms/danish/stemmer.html
-
stem(word)[source] -
Stem a Danish word and return the stemmed form.
Parameters: word (str or unicode) – The word that is stemmed. Returns: The stemmed form. Return type: unicode
-
class
nltk.stem.snowball.DutchStemmer(ignore_stopwords=False)[source] -
Bases:
nltk.stem.snowball._StandardStemmerThe Dutch Snowball stemmer.
Variables: - __vowels – The Dutch vowels.
- __step1_suffixes – Suffixes to be deleted in step 1 of the algorithm.
- __step3b_suffixes – Suffixes to be deleted in step 3b of the algorithm.
Note: A detailed description of the Dutch stemming algorithm can be found underhttp://snowball.tartarus.org/algorithms/dutch/stemmer.html
-
stem(word)[source] -
Stem a Dutch word and return the stemmed form.
Parameters: word (str or unicode) – The word that is stemmed. Returns: The stemmed form. Return type: unicode
-
class
nltk.stem.snowball.EnglishStemmer(ignore_stopwords=False)[source] -
Bases:
nltk.stem.snowball._StandardStemmerThe English Snowball stemmer.
Variables: - __vowels – The English vowels.
- __double_consonants – The English double consonants.
- __li_ending – Letters that may directly appear before a word final ‘li’.
- __step0_suffixes – Suffixes to be deleted in step 0 of the algorithm.
- __step1a_suffixes – Suffixes to be deleted in step 1a of the algorithm.
- __step1b_suffixes – Suffixes to be deleted in step 1b of the algorithm.
- __step2_suffixes – Suffixes to be deleted in step 2 of the algorithm.
- __step3_suffixes – Suffixes to be deleted in step 3 of the algorithm.
- __step4_suffixes – Suffixes to be deleted in step 4 of the algorithm.
- __step5_suffixes – Suffixes to be deleted in step 5 of the algorithm.
- __special_words – A dictionary containing words which have to be stemmed specially.
Note: A detailed description of the English stemming algorithm can be found underhttp://snowball.tartarus.org/algorithms/english/stemmer.html
-
stem(word)[source] -
Stem an English word and return the stemmed form.
Parameters: word (str or unicode) – The word that is stemmed. Returns: The stemmed form. Return type: unicode
-
class
nltk.stem.snowball.FinnishStemmer(ignore_stopwords=False)[source] -
Bases:
nltk.stem.snowball._StandardStemmerThe Finnish Snowball stemmer.
Variables: - __vowels – The Finnish vowels.
- __restricted_vowels – A subset of the Finnish vowels.
- __long_vowels – The Finnish vowels in their long forms.
- __consonants – The Finnish consonants.
- __double_consonants – The Finnish double consonants.
- __step1_suffixes – Suffixes to be deleted in step 1 of the algorithm.
- __step2_suffixes – Suffixes to be deleted in step 2 of the algorithm.
- __step3_suffixes – Suffixes to be deleted in step 3 of the algorithm.
- __step4_suffixes – Suffixes to be deleted in step 4 of the algorithm.
Note: A detailed description of the Finnish stemming algorithm can be found underhttp://snowball.tartarus.org/algorithms/finnish/stemmer.html
-
stem(word)[source] -
Stem a Finnish word and return the stemmed form.
Parameters: word (str or unicode) – The word that is stemmed. Returns: The stemmed form. Return type: unicode
-
class
nltk.stem.snowball.FrenchStemmer(ignore_stopwords=False)[source] -
Bases:
nltk.stem.snowball._StandardStemmerThe French Snowball stemmer.
Variables: - __vowels – The French vowels.
- __step1_suffixes – Suffixes to be deleted in step 1 of the algorithm.
- __step2a_suffixes – Suffixes to be deleted in step 2a of the algorithm.
- __step2b_suffixes – Suffixes to be deleted in step 2b of the algorithm.
- __step4_suffixes – Suffixes to be deleted in step 4 of the algorithm.
Note: A detailed description of the French stemming algorithm can be found underhttp://snowball.tartarus.org/algorithms/french/stemmer.html
-
stem(word)[source] -
Stem a French word and return the stemmed form.
Parameters: word (str or unicode) – The word that is stemmed. Returns: The stemmed form. Return type: unicode
-
class
nltk.stem.snowball.GermanStemmer(ignore_stopwords=False)[source] -
Bases:
nltk.stem.snowball._StandardStemmerThe German Snowball stemmer.
Variables: - __vowels – The German vowels.
- __s_ending – Letters that may directly appear before a word final ‘s’.
- __st_ending – Letter that may directly appear before a word final ‘st’.
- __step1_suffixes – Suffixes to be deleted in step 1 of the algorithm.
- __step2_suffixes – Suffixes to be deleted in step 2 of the algorithm.
- __step3_suffixes – Suffixes to be deleted in step 3 of the algorithm.
Note: A detailed description of the German stemming algorithm can be found underhttp://snowball.tartarus.org/algorithms/german/stemmer.html
-
stem(word)[source] -
Stem a German word and return the stemmed form.
Parameters: word (str or unicode) – The word that is stemmed. Returns: The stemmed form. Return type: unicode
-
class
nltk.stem.snowball.HungarianStemmer(ignore_stopwords=False)[source] -
Bases:
nltk.stem.snowball._LanguageSpecificStemmerThe Hungarian Snowball stemmer.
Variables: - __vowels – The Hungarian vowels.
- __digraphs – The Hungarian digraphs.
- __double_consonants – The Hungarian double consonants.
- __step1_suffixes – Suffixes to be deleted in step 1 of the algorithm.
- __step2_suffixes – Suffixes to be deleted in step 2 of the algorithm.
- __step3_suffixes – Suffixes to be deleted in step 3 of the algorithm.
- __step4_suffixes – Suffixes to be deleted in step 4 of the algorithm.
- __step5_suffixes – Suffixes to be deleted in step 5 of the algorithm.
- __step6_suffixes – Suffixes to be deleted in step 6 of the algorithm.
- __step7_suffixes – Suffixes to be deleted in step 7 of the algorithm.
- __step8_suffixes – Suffixes to be deleted in step 8 of the algorithm.
- __step9_suffixes – Suffixes to be deleted in step 9 of the algorithm.
Note: A detailed description of the Hungarian stemming algorithm can be found underhttp://snowball.tartarus.org/algorithms/hungarian/stemmer.html
-
stem(word)[source] -
Stem an Hungarian word and return the stemmed form.
Parameters: word (str or unicode) – The word that is stemmed. Returns: The stemmed form. Return type: unicode
-
class
nltk.stem.snowball.ItalianStemmer(ignore_stopwords=False)[source] -
Bases:
nltk.stem.snowball._StandardStemmerThe Italian Snowball stemmer.
Variables: - __vowels – The Italian vowels.
- __step0_suffixes – Suffixes to be deleted in step 0 of the algorithm.
- __step1_suffixes – Suffixes to be deleted in step 1 of the algorithm.
- __step2_suffixes – Suffixes to be deleted in step 2 of the algorithm.
Note: A detailed description of the Italian stemming algorithm can be found underhttp://snowball.tartarus.org/algorithms/italian/stemmer.html
-
stem(word)[source] -
Stem an Italian word and return the stemmed form.
Parameters: word (str or unicode) – The word that is stemmed. Returns: The stemmed form. Return type: unicode
-
class
nltk.stem.snowball.NorwegianStemmer(ignore_stopwords=False)[source] -
Bases:
nltk.stem.snowball._ScandinavianStemmerThe Norwegian Snowball stemmer.
Variables: - __vowels – The Norwegian vowels.
- __s_ending – Letters that may directly appear before a word final ‘s’.
- __step1_suffixes – Suffixes to be deleted in step 1 of the algorithm.
- __step2_suffixes – Suffixes to be deleted in step 2 of the algorithm.
- __step3_suffixes – Suffixes to be deleted in step 3 of the algorithm.
Note: A detailed description of the Norwegian stemming algorithm can be found underhttp://snowball.tartarus.org/algorithms/norwegian/stemmer.html
-
stem(word)[source] -
Stem a Norwegian word and return the stemmed form.
Parameters: word (str or unicode) – The word that is stemmed. Returns: The stemmed form. Return type: unicode
-
class
nltk.stem.snowball.PorterStemmer(ignore_stopwords=False)[source] -
Bases:
nltk.stem.snowball._LanguageSpecificStemmer,nltk.stem.porter.PorterStemmerA word stemmer based on the original Porter stemming algorithm.
Porter, M. “An algorithm for suffix stripping.” Program 14.3 (1980): 130-137.A few minor modifications have been made to Porter’s basic algorithm. See the source code of the module nltk.stem.porter for more information.
-
class
nltk.stem.snowball.PortugueseStemmer(ignore_stopwords=False)[source] -
Bases:
nltk.stem.snowball._StandardStemmerThe Portuguese Snowball stemmer.
Variables: - __vowels – The Portuguese vowels.
- __step1_suffixes – Suffixes to be deleted in step 1 of the algorithm.
- __step2_suffixes – Suffixes to be deleted in step 2 of the algorithm.
- __step4_suffixes – Suffixes to be deleted in step 4 of the algorithm.
Note: A detailed description of the Portuguese stemming algorithm can be found underhttp://snowball.tartarus.org/algorithms/portuguese/stemmer.html
-
stem(word)[source] -
Stem a Portuguese word and return the stemmed form.
Parameters: word (str or unicode) – The word that is stemmed. Returns: The stemmed form. Return type: unicode
-
class
nltk.stem.snowball.RomanianStemmer(ignore_stopwords=False)[source] -
Bases:
nltk.stem.snowball._StandardStemmerThe Romanian Snowball stemmer.
Variables: - __vowels – The Romanian vowels.
- __step0_suffixes – Suffixes to be deleted in step 0 of the algorithm.
- __step1_suffixes – Suffixes to be deleted in step 1 of the algorithm.
- __step2_suffixes – Suffixes to be deleted in step 2 of the algorithm.
- __step3_suffixes – Suffixes to be deleted in step 3 of the algorithm.
Note: A detailed description of the Romanian stemming algorithm can be found underhttp://snowball.tartarus.org/algorithms/romanian/stemmer.html
-
stem(word)[source] -
Stem a Romanian word and return the stemmed form.
Parameters: word (str or unicode) – The word that is stemmed. Returns: The stemmed form. Return type: unicode
-
class
nltk.stem.snowball.RussianStemmer(ignore_stopwords=False)[source] -
Bases:
nltk.stem.snowball._LanguageSpecificStemmerThe Russian Snowball stemmer.
Variables: - __perfective_gerund_suffixes – Suffixes to be deleted.
- __adjectival_suffixes – Suffixes to be deleted.
- __reflexive_suffixes – Suffixes to be deleted.
- __verb_suffixes – Suffixes to be deleted.
- __noun_suffixes – Suffixes to be deleted.
- __superlative_suffixes – Suffixes to be deleted.
- __derivational_suffixes – Suffixes to be deleted.
Note: A detailed description of the Russian stemming algorithm can be found underhttp://snowball.tartarus.org/algorithms/russian/stemmer.html
-
stem(word)[source] -
Stem a Russian word and return the stemmed form.
Parameters: word (str or unicode) – The word that is stemmed. Returns: The stemmed form. Return type: unicode
-
class
nltk.stem.snowball.SnowballStemmer(language, ignore_stopwords=False)[source] -
Bases:
nltk.stem.api.StemmerISnowball Stemmer
The following languages are supported: Danish, Dutch, English, Finnish, French, German, Hungarian, Italian, Norwegian, Portuguese, Romanian, Russian, Spanish and Swedish.
The algorithm for English is documented here:
Porter, M. “An algorithm for suffix stripping.” Program 14.3 (1980): 130-137.The algorithms have been developed by Martin Porter. These stemmers are called Snowball, because Porter created a programming language with this name for creating new stemming algorithms. There is more information available at http://snowball.tartarus.org/
The stemmer is invoked as shown below:
>>> from nltk.stem import SnowballStemmer >>> print(" ".join(SnowballStemmer.languages)) # See which languages are supported danish dutch english finnish french german hungarian italian norwegian porter portuguese romanian russian spanish swedish >>> stemmer = SnowballStemmer("german") # Choose a language >>> stemmer.stem("Autobahnen") # Stem a word 'autobahn'Invoking the stemmers that way is useful if you do not know the language to be stemmed at runtime. Alternatively, if you already know the language, then you can invoke the language specific stemmer directly:
>>> from nltk.stem.snowball import GermanStemmer >>> stemmer = GermanStemmer() >>> stemmer.stem("Autobahnen") 'autobahn'Parameters: - language (str or unicode) – The language whose subclass is instantiated.
- ignore_stopwords (bool) – If set to True, stopwords are not stemmed and returned unchanged. Set to False by default.
Raises: ValueError – If there is no stemmer for the specified language, a ValueError is raised.
-
languages= ('danish', 'dutch', 'english', 'finnish', 'french', 'german', 'hungarian', 'italian', 'norwegian', 'porter', 'portuguese', 'romanian', 'russian', 'spanish', 'swedish')
-
class
nltk.stem.snowball.SpanishStemmer(ignore_stopwords=False)[source] -
Bases:
nltk.stem.snowball._StandardStemmerThe Spanish Snowball stemmer.
Variables: - __vowels – The Spanish vowels.
- __step0_suffixes – Suffixes to be deleted in step 0 of the algorithm.
- __step1_suffixes – Suffixes to be deleted in step 1 of the algorithm.
- __step2a_suffixes – Suffixes to be deleted in step 2a of the algorithm.
- __step2b_suffixes – Suffixes to be deleted in step 2b of the algorithm.
- __step3_suffixes – Suffixes to be deleted in step 3 of the algorithm.
Note: A detailed description of the Spanish stemming algorithm can be found underhttp://snowball.tartarus.org/algorithms/spanish/stemmer.html
-
stem(word)[source] -
Stem a Spanish word and return the stemmed form.
Parameters: word (str or unicode) – The word that is stemmed. Returns: The stemmed form. Return type: unicode
-
class
nltk.stem.snowball.SwedishStemmer(ignore_stopwords=False)[source] -
Bases:
nltk.stem.snowball._ScandinavianStemmerThe Swedish Snowball stemmer.
Variables: - __vowels – The Swedish vowels.
- __s_ending – Letters that may directly appear before a word final ‘s’.
- __step1_suffixes – Suffixes to be deleted in step 1 of the algorithm.
- __step2_suffixes – Suffixes to be deleted in step 2 of the algorithm.
- __step3_suffixes – Suffixes to be deleted in step 3 of the algorithm.
Note: A detailed description of the Swedish stemming algorithm can be found underhttp://snowball.tartarus.org/algorithms/swedish/stemmer.html
-
stem(word)[source] -
Stem a Swedish word and return the stemmed form.
Parameters: word (str or unicode) – The word that is stemmed. Returns: The stemmed form. Return type: unicode
-
nltk.stem.snowball.demo()[source] -
This function provides a demonstration of the Snowball stemmers.
After invoking this function and specifying a language, it stems an excerpt of the Universal Declaration of Human Rights (which is a part of the NLTK corpus collection) and then prints out the original and the stemmed text.
nltk.stem.util module
-
nltk.stem.util.suffix_replace(original, old, new)[source] -
Replaces the old suffix of the original string by a new suffix
nltk.stem.wordnet module
-
class
nltk.stem.wordnet.WordNetLemmatizer[source] -
Bases:
objectWordNet Lemmatizer
Lemmatize using WordNet’s built-in morphy function. Returns the input word unchanged if it cannot be found in WordNet.
>>> from nltk.stem import WordNetLemmatizer >>> wnl = WordNetLemmatizer() >>> print(wnl.lemmatize('dogs')) dog >>> print(wnl.lemmatize('churches')) church >>> print(wnl.lemmatize('aardwolves')) aardwolf >>> print(wnl.lemmatize('abaci')) abacus >>> print(wnl.lemmatize('hardrock')) hardrock-
lemmatize(word, pos='n')[source]
-
unicode_repr()
-
-
nltk.stem.wordnet.teardown_module(module=None)[source]
Module contents
NLTK Stemmers
Interfaces used to remove morphological affixes from words, leaving only the word stem. Stemming algorithms aim to remove those affixes required for eg. grammatical role, tense, derivational morphology leaving only the stem of the word. This is a difficult problem due to irregular words (eg. common verbs in English), complicated morphological rules, and part-of-speech and sense ambiguities (eg. ceil- is not the stem of ceiling).
StemmerI defines a standard interface for stemmers.