小白自学搭建单机版的Hadoop生态圈(持续更新)
安装虚拟机
VM免费版
下载这个免费的VM,用虚拟机装Linux,所以你本机的内存至少要8G,不然就很慢啦。
安装过程,复选框都可以去掉,除了选快捷方式的那一栏。注意不要装在C盘哦。
Ubuntu下载
下载16.04 64位的。
安装好VM之后打开,点击新建虚拟机 




安装过程中会出现让你下载VM tools,下载吧,不过这次可能会下载不成功,没关系,先取消,后面改了源之后,下次再开VM虚拟机时就会再次下载。
安装好后,输入密码,进入桌面,右击可以打开控制台,可以将控制台锁定在左侧栏。
选择设置,然后选择下面的软件与更新,在下载源中选择阿里的源。这样下载软件与更新就超级快了。选择好源后点击关闭,然后出现让你重新载入的对话框,选择重新载入。等待下载完毕就OK了。 
选择设置,语言支持,然后会先下载一些东西。等着它自己下好了后,选择安装/删除语音,选择简体中文,然后点击应用。
下载好之后,左键把中文拖到第一个。 
然后重启之后就变成中文的了。
输入下面的可以更新软件
sudo apt-get install 安装中文输入法:
在Ubuntu Software Center 搜索fcitx,安装fcitx输入法框架,一般来说应该是已经装好了。
在Terminal 下命令安装拼音输入法: sudo apt-get install fcitx-pinyin
然后修改下面的,改成fcitx,最后重启就可以了。 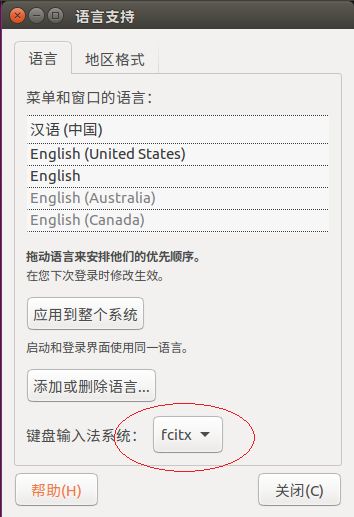
部署开发环境
1.安装JDK参考下面的博客
JDK
2.安装Scala
Scala
到页面下面下载.tgz格式的文件。
解压:
sudo tar -xvzf scala-2.10.6.tgz
修改配置文件:
sudo gedit ~/.bashrc
加入:
export SCALA_HOME=/home/xuyao/下载/scala-2.10.6
export PATH=SCALAHOME/bin:PATH
保存环境变量,退出编辑器,输入命令使之生效 source ~/.bashrc ,可输入 env 命令查看设置是否成功。
输入Scala之后: 
3.安装idea
到idea官网上下载Linux版本的tar.gz文件,选择没有JDK的版本,选择社区版,下载后解压:
sudo tar -xvzf ideaIC-2016.3-no-jdk.tar.gz在它的bin目录下:
./idea.sh默认设置,一直下一步 
建立新的工程,先建个Java的,进去之后,选择: 
如果直接在线不行,那么:
http://plugins.jetbrains.com/plugin/?idea&id=1347
找到对应的版本,下载压缩文件,把下载的.zip格式的scala插件放到Intellij的安装的plugins目录下;再安装刚刚放到Intellij的plugins目录下的scala插件(注:直接安装zip文件)即可。 
重启之后就OK 了。
根据下面的2个,配置idea的一些设置,以及新建Scala工程:
http://blog.csdn.net/xuyaoqiaoyaoge/article/details/52943606
http://blog.csdn.net/xuyaoqiaoyaoge/article/details/53375088
部署Hadoop
1.安装ssh
ssh localhostssh-keygen -t rsa -P ""cd ~/.ssh
cat id_rsa.pub >> authorized_keys ssh localhost2.安装rsync
sudo apt-get install rsync3.配置Hadoop
http://hadoop.apache.org/releases.html#Download
下载二进制的2.6.5,解压。
环节变量:
export HADOOP_HOME=/home/xuyao/下载/hadoop-2.6.5
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/conf:$PATH
export PATH=$PATH:$HADOOP_HOME/sbin
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib:$HADOOP_HOME/lib/native"/hadoop-2.6.5/etc/hadoop下面:
hadoop-env.sh
export JAVA_HOME=/usr/lib/jvm/jdk1.8.0yarn-env.sh
export JAVA_HOME=/usr/lib/jvm/jdk1.8.0hdfs-site.xml
<configuration>
<property>
<name>dfs.replicationname>
<value>1value>
property>
<property>
<name>dfs.namenode.name.dirname>
<value>/home/xuyao/下载/hadoop-2.6.5/dfs/namevalue>
property>
<property>
<name>dfs.datannode.data.dirname>
<value>/home/xuyao/下载/hadoop-2.6.5/dfs/datavalue>
property>
configuration>core-site.xml
<configuration>
<property>
<name>hadoop.tmp.dirname>
<value>/home/xuyao/下载/hadoop-2.6.5/tmpvalue>
property>
<property>
<name>fs.default.namename>
<value>hdfs://localhost:9000value>
property>
configuration>mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.namename>
<value>yarnvalue>
property>
configuration>yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-servicesname>
<value>mapreduce_shufflevalue>
property>
<property>
<name>yarn.resourcemanager.webapp.addressname>
<value>${yarn.resourcemanager.hostname}:8099value>
property>
configuration>4.启动Hadoop
hadoop namenode -formatsbin/start-dfs.sh
sbin/start-yarn.sh 5.JPS 
如果发现namenode没有启动,就再次格式化,再次启动。
6.
看yarn的web界面:
http://localhost:8099/cluster
看HDFS的web界面:
http://localhost:50070/
部署HBase
HBase下载
我下载的是1.2.3版本的。解压。
修改环境变量:
export HBASE_HOME=/home/xuyao/下载/hbase-1.2.3
export PATH=$HBASE_HOME/bin:$PATH
export HBASE_CONF_DIR=$HBASE_HOME/confhbase-env.sh:
export JAVA_HOME=/usr/lib/jvm/jdk1.8.0
export HBASE_CLASSPATH=/home/xuyao/下载/hbase-1.2.3/conf
export HBASE_MANAGES_ZK=true
export HBASE_HOME=/home/xuyao/下载/hbase-1.2.3
export HADOOP_HOME=/home/xuyao/下载/hadoop-2.6.5export HBASE_MANAGES_ZK=true//true表示单机伪分布式。FALSE表示集群。
hbase-site.xml:
<configuration>
<property>
<name>hbase.rootdirname>
<value>hdfs://localhost:9000/hbasevalue>
property>
<property>
<name>dfs.replicationname>
<value>1value>
property>
<property>
<name>hbase.cluster.distributedname>
<value>truevalue>
property>
<property>
<name>hbase.zookeeper.property.dataDirname>
<value>/home/xuyao/下载/hbase-1.2.3/data/zookeepervalue>
property>
configuration>启动:
start-hbase.sh查看进程:
3155 NameNode
3637 ResourceManager
3274 DataNode
4411 HMaster
3755 NodeManager
4637 Jps
3485 SecondaryNameNode
4526 HRegionServer
4319 HQuorumPeer
Hadoop的进程:NameNode,DataNode,SecondaryNameNode
yarn的进程:NodeManager,ResourceManager
HBase的进程:HMaster,HRegionServer,HQuorumPeer
一些简单的HBase shell操作:
进入shell:
hbase shell建立一个表:test表名,cf列簇名
create 'test' ,'cf'查看表的属性:
describe 'test'插入数据:test表名,row1行主键名,cf列簇名,a列名,value1值
put 'test','row1','cf:a','value1'
打印表中所有的数据:
scan 'test'获得某一行的数据:
get 'test','row1'列出所有的表名:
list退出:
exit部署Hive
到hive
下载:
apache-hive-2.0.1-bin.tar.gz
解压
修改环境变量:
export HIVE_HOME=/home/xuyao/下载/hive-2.0.1
export PATH=$HIVE_HOME/bin:$PATH修改hive-env.sh,通过模板先复制过来
HADOOP_HOME=/home/xuyao/下载/hadoop-2.6.5
export HIVE_CONF_DIR=/home/xuyao/下载/hive-2.0.1/conf将hive-default.xml.template复制重名为hive-site.xml
修改:
<property>
<name>hive.metastore.warehouse.dirname>
<value>/home/hive/warehousevalue>
<description>location of default database for the warehousedescription>
property>
<property>
<name>javax.jdo.option.ConnectionURLname>
<value>jdbc:derby:/home/xuyao/下载/hive-2.0.1/metastore_db;create=truevalue>
<description>JDBC connect string for a JDBC metastoredescription>
property>将hive-log4j.properties.template改为hive-log4j.properties
将hive-exec-log4j.properties.template改为hive-exec-log4j.properties
在hive目录下创建warehouse文件夹,然后修改权限:
chmod a+rwx /home/xuyao/下载/hive-2.0.1/warehouse初始化数据库:
schematool -initSchema -dbType derby出现如下则成功
Starting metastore schema initialization to 2.0.0
Initialization script hive-schema-2.0.0.derby.sql
Initialization script completed
schemaTool completed
输入hive,如果出现:
Exception in thread "main" java.lang.IllegalArgumentException: java.net.URISyntaxException: Relative path in absolute URI: ${system:java.io.tmpdir%7D/$%7Bsystem:user.name%7D修改hive-site.xml
<property>
<name>hive.exec.scratchdirname>
/home/xuyao/tmp/hive
HDFS root scratch dir for Hive jobs which gets created with write all (733) permission. For each connecting user, an HDFS scratch dir: ${hive.exec.scratchdir}/<username> is created, with ${hive.scratch.dir.permission}.
property>
<property>
<name>hive.exec.local.scratchdirname>
/home/xuyao/tmp/hive/local
Local scratch space for Hive jobs
property>
<property>
<name>hive.downloaded.resources.dirname>
/home/xuyao/tmp/hive/resources
Temporary local directory for added resources in the remote file system.
property>建立如下三个文件夹:
/home/xuyao/tmp/hive
/home/xuyao/tmp/hive/local
/home/xuyao/tmp/hive/resources再次启动hive,成功!
输入 set -v; 会出现一大堆配置信息
输入 quit; 退出
一些简单的Hive shell操作:
建一个存数据的目录:
hadoop fs -mkdir /xy/hive/warehouse
hadoop fs -chmod 777 /xy/hive/warehouse创建表:
Create Table dept (deptno Int,dname String) Row format delimited fields terminated By'\t';然后在/xy/hive/warehouse中就可以看到这个表。
查看有哪些表:
show tables;
查看表的属性:
describe dept;
hive并不支持insert into tablename values()
将已有的文件载入hive:
load data local inpath '/home/xuyao/dept.txt' overwrite into table dept;
文件字段必须以\t隔开,不同行用\n
查看内容:
select * from dept;