linux tcp实现
1. 前言
在产品应用中发现,当机器带宽足够大时,抓取火焰图,图中网络线程占用大量cpu,主要是内存的频繁申请释放导致的。为了处理该问题,查看了网络上的一些调优参数并阅读了linux内核中tcp相关源码,将过程和心得在这里做个记录。.
2. 本文分析内容安排
- 参数
- 结构
- 源码
3. 参数
这里的参数主要包含三部分:内存相关、窗口大小、tcp是否拆包
- 内存相关
这里主要包含5个参数,其中分别为tcp_mem[3]、tcp_rmem[3]、tcp_wmem[3]、rmem_max、wmem_max。其中tcp_mem[3]的单位是页,指代机器上所有socket的内存阈值;其余4个参数单位是字节,指代具体一个socket的内存阈值。 - tcp接收窗口
在tcp头中,指代接收window大小的字段仅有16位,所以最初接收窗口最大仅有64k;但是现在通过使接收窗口值左移可以增加指代的窗口大小,比如将该字段左移12位,那么可以指代的接收窗口就能达到256M。 - tcp是否拆包
为了达到以太网最佳性能,ip被设计为分片的,但分片过大丢包时重传数据变多,分片过小则ip头浪费太多带宽,在ip层分片的大小默认为1500B。
在tcp层,为了避免在ip层的拆包,直接将tcp拆成了1460大小的segment,剩余的40B分为作为tcp和ip的包头。如此分片后,tcp segment传输到ip层后就可以加上ip头然后直接传输。
另外还有一种处理方式就是在tcp层不拆包,直接发送一个大的tcp包,而拆包过程都交给tcp来做。如此,每个tcp包被拆分后,仅有第一个ip分片中含有tcp包头,而且,在接收端的ip层会接收到该tcp包含的所有ip分片并重组后才会发送给tcp层。如此的优势是tcp层可以一次申请整个包大小的内存来保存该tcp包,避免了频繁的小块内存申请;但劣势是,任何一个ip分片丢失,导致ip层不能重组成完整的tcp包发送给tcp层,则接收端tcp不会ack该包,发送端就会重发整个包。
可以使用ethtool -k bond0来查看特定网卡是否开启了tcp不拆包,其中tcp-segmentation-offload为该选项。
4. 结构
- struct socket: 面向用户空间,应用程序通过系统调用开始创建的socket都是该结构体,它是基于虚拟文件系统创建出来的;
- struct sock: 网络层的socket;对应有TCP、UDP、RAW三种,面向内核驱动;
- struct inet_sock: 它是INET域的socket表示,是对struct sock的一个扩展,提供INET域的一些属性,如TTL,组播列表,IP地址,端口等;
- struct raw_socket: 它是RAW协议的一个socket表示,是对struct inet_sock的扩展,它要处理与ICMP相关的内容;
- struct udp_sock: 它是UDP协议的socket表示,是对struct inet_sock的扩展;
- struct inet_connection_sock: 它是所有面向连接的socket表示,是对struct inet_sock的扩展;
- struct tcp_sock: 它是TCP协议的socket表示,是对struct inet_connection_sock的扩展,主要增加滑动窗口,拥塞控制一些TCP专用属性;
- struct sk_buff: 一个tcp包
5. 源码
5.1 系统初始化
首先,对tcp_mem、tcp_wmem和tcp_rmem初始化,根据这里的程序发现,应该是在tcp_init的时候设定了tcp_wmem和tcp_rmem的值,在tcp_init_mem中设置了tcp_mem的值,然后都写入/proc/sys/net/ipv4中的,这些函数在inet_init调用,而inet_init是通过fs_initcall在内核初始化的时候调用的,属于在系统启动时已经执行完成的
net/ipv4/af_inet.c
static int __init inet_init(void)
{
//为各协议注册protocal,tcp对应的是tcp_proc
for (q = inetsw_array; q < &inetsw_array[INETSW_ARRAY_LEN]; ++q)
inet_register_protosw(q);
tcp_init();
}
net/ipv4/tcp_ipv4.c
struct proto tcp_prot = {
.name = "TCP",
.init = tcp_v4_init_sock,
.setsockopt = tcp_setsockopt,
.getsockopt = tcp_getsockopt,
.recvmsg = tcp_recvmsg,
.sendmsg = tcp_sendmsg,
.sendpage = tcp_sendpage,
.sysctl_wmem = sysctl_tcp_wmem,
.sysctl_rmem = sysctl_tcp_rmem,
.obj_size = sizeof(struct tcp_sock),
};
net/ipv4/tcp.c
//该函数在inet_init函数中调用
void __init tcp_init(void)
{
sysctl_tcp_wmem[0] = SK_MEM_QUANTUM;
sysctl_tcp_wmem[1] = 16*1024;
sysctl_tcp_wmem[2] = max(64*1024, max_wshare);
sysctl_tcp_rmem[0] = SK_MEM_QUANTUM;
sysctl_tcp_rmem[1] = 87380;
sysctl_tcp_rmem[2] = max(87380, max_rshare);
}
void tcp_init_mem(struct net *net)
{
unsigned long limit = nr_free_buffer_pages() / 8;
limit = max(limit, 128UL);
net->ipv4.sysctl_tcp_mem[0] = limit / 4 * 3;
net->ipv4.sysctl_tcp_mem[1] = limit;
net->ipv4.sysctl_tcp_mem[2] = net->ipv4.sysctl_tcp_mem[0] * 2;
}
sysctl_wmem_max、sysctl_rmem_max、sysctl_wmem_default、sysctl_rmem_default都是全局变量,在初始化的时候直接赋值,然后会写入/proc/sys/net/core中。
net/core/sock.c
/* Run time adjustable parameters. */
__u32 sysctl_wmem_max __read_mostly = SK_WMEM_MAX;
EXPORT_SYMBOL(sysctl_wmem_max);
__u32 sysctl_rmem_max __read_mostly = SK_RMEM_MAX;
EXPORT_SYMBOL(sysctl_rmem_max);
__u32 sysctl_wmem_default __read_mostly = SK_WMEM_MAX;
__u32 sysctl_rmem_default __read_mostly = SK_RMEM_MAX;
但是,这四个值并未用到,仅有用户通过setsockopt设定接收或发送窗口大小时才会使用,而且仅仅是作为一个阈值限制窗口使用的内存的最大值。
net/core/sock.c
int sock_setsockopt(struct socket *sock, int level, int optname,
char __user *optval, unsigned int optlen)
{
case SO_SNDBUF:
val = min_t(u32, val, sysctl_wmem_max);
set_sndbuf:
sk->sk_userlocks |= SOCK_SNDBUF_LOCK;
sk->sk_sndbuf = max_t(u32, val * 2, SOCK_MIN_SNDBUF);
sk->sk_write_space(sk);
break;
case SO_RCVBUF:
val = min_t(u32, val, sysctl_rmem_max);
set_rcvbuf:
sk->sk_userlocks |= SOCK_RCVBUF_LOCK;
sk->sk_rcvbuf = max_t(u32, val * 2, SOCK_MIN_RCVBUF);
break;
}
5.2 套接字创建流程
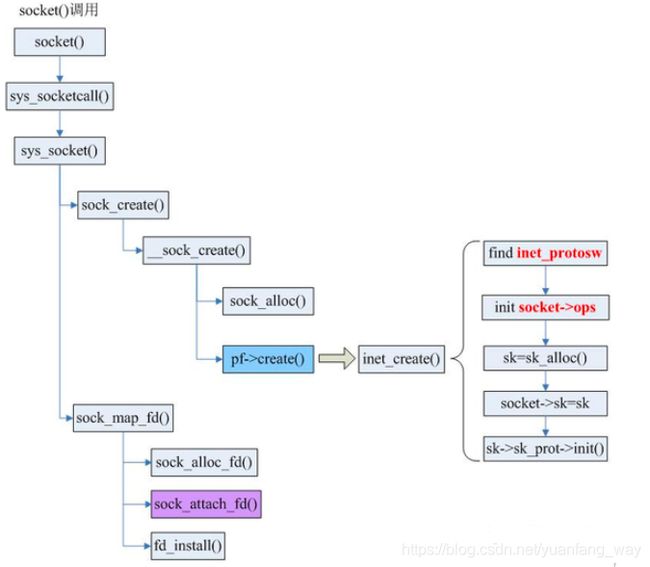
用户态程序通过包含sys/socket.h头文件创建socket,收件进入其对应的系统调用,在net/socket.c中:
SYSCALL_DEFINE3(socket, int, family, int, type, int, protocol)
{
int retval;
struct socket *sock;
int flags;
retval = sock_create(family, type, protocol, &sock);
if (retval < 0)
goto out;
//socket与文件系统关联
retval = sock_map_fd(sock, flags & (O_CLOEXEC | O_NONBLOCK));
if (retval < 0)
goto out_release;
out_release:
sock_release(sock);
return retval;
}
net/socket.c
···
int __sock_create(struct net *net, int family, int type, int protocol,
struct socket res, int kern)
{
//为socket结构本身分配内存,并为其分配一个inode
struct socket sock;
sock = sock_alloc();
if (!sock) {
net_warn_ratelimited(“socket: no more sockets\n”);
return -ENFILE; / Not exactly a match, but its the
closest posix thing */
}
//一般的tcp连接对应的是PF_INET家族协议,这里实际调用的是inet_create
const struct net_proto_family *pf;
err = pf->create(net, sock, protocol, kern);
if (err < 0)
goto out_module_put;
}
···
net/ipv4/af_inet.c
static int inet_create(struct net *net, struct socket *sock, int protocol,
int kern)
{
struct sock *sk;
struct inet_protosw *answer;
struct inet_sock *inet;
struct proto *answer_prot;
//分配sock结构
struct sock *sk;
sk = sk_alloc(net, PF_INET, GFP_KERNEL, answer_prot);
if (sk == NULL)
goto out;
inet = inet_sk(sk);
//初始化sock结构
sock_init_data(sock, sk);
//调用tcp_prot的init函数,net/ipv4/Tcp_ipv4.c:tcp_v4_init_sock(),它主要是对tcp_sock和inet_connection_sock进行一些初始化;
sk->sk_prot->init(sk);
}
struct sock *sk_alloc(struct net *net, int family, gfp_t priority,
struct proto *prot)
{
struct sock *sk;
//从slab或者伙伴系统中分配sock本身所占内存
sk = sk_prot_alloc(prot, priority | __GFP_ZERO, family);
if (sk) {
sk->sk_family = family;
//给sock的struct proto赋值,tcp实际对应的为struct proto tcp_prot
sk->sk_prot = sk->sk_prot_creator = prot;
sock_lock_init(sk);
sock_net_set(sk, get_net(net));
//sk_wmem_alloc为正在发送的字节数,在建立sock的时候初始化为1,发送包时增加包字节数,ack时释放包对应的sk_buff并减少sk_wmem_alloc,析构sock时置0
atomic_set(&sk->sk_wmem_alloc, 1);
sock_update_classid(sk);
sock_update_netprioidx(sk);
}
return sk;
}
void sock_init_data(struct socket *sock, struct sock *sk)
{
//初始化接收链表、发送链表,窗口大小sk_rcvbuf仅是一个数值,真正指的是sk_receive_queue的总字节数不能超过sk_rcvbuf值
skb_queue_head_init(&sk->sk_receive_queue);
skb_queue_head_init(&sk->sk_write_queue);
skb_queue_head_init(&sk->sk_error_queue);
//设置内存分配方式和窗口大小
sk->sk_allocation = GFP_KERNEL;
sk->sk_rcvbuf = sysctl_rmem_default;
sk->sk_sndbuf = sysctl_wmem_default;
sk->sk_state = TCP_CLOSE;
sk_set_socket(sk, sock);
}
static int tcp_v4_init_sock(struct sock *sk)
{
struct inet_connection_sock *icsk = inet_csk(sk);
tcp_init_sock(sk);
}
//这个函数中赋值了拥塞窗口、发送缓存以及接受缓存的大小,因为本函数在inet_create函数中是在sock_init_data之后执行的,所以会覆盖已有的sk_sndbuf和sk_rcvbuf设置
void tcp_init_sock(struct sock *sk)
{
struct inet_connection_sock *icsk = inet_csk(sk);
struct tcp_sock *tp = tcp_sk(sk);
skb_queue_head_init(&tp->out_of_order_queue);
tcp_init_xmit_timers(sk);
tcp_prequeue_init(tp);
INIT_LIST_HEAD(&tp->tsq_node);
tp->snd_cwnd = TCP_INIT_CWND;
tp->snd_ssthresh = TCP_INFINITE_SSTHRESH;
sk->sk_sndbuf = sysctl_tcp_wmem[1];
sk->sk_rcvbuf = sysctl_tcp_rmem[1];
}
创建好socket后需要与文件系统相关联,socket与文件系统关联后,以后便可以通过文件系统read/write对socket进行操作了,通过如下函数
static int sock_map_fd(struct socket *sock, int flags)
{
struct file *newfile;
//申请文件描述符,并分配file结构和目录项结构;
int fd = get_unused_fd_flags(flags);
if (unlikely(fd < 0))
return fd;
//关联socket相关的文件操作函数表和目录项操作函数表;
newfile = sock_alloc_file(sock, flags, NULL);
if (likely(!IS_ERR(newfile))) {
fd_install(fd, newfile);
return fd;
}
put_unused_fd(fd);
return PTR_ERR(newfile);
}
5.3 操作注册
上面已经说到内核将socket也当做文件处理,为其分配了inode,这里首先注册socket对应的文件操作,可见其写对应的是sock_aio_write,读对应sock_aio_read。
net/socket.c
static const struct file_operations socket_file_ops = {
.aio_read = sock_aio_read,
.aio_write = sock_aio_write,
.poll = sock_poll,
.unlocked_ioctl = sock_ioctl,
.mmap = sock_mmap,
.fasync = sock_fasync,
};
//写函数栈向下最终调用的是sendmsg
static ssize_t sock_aio_write(struct kiocb *iocb, const struct iovec *iov,
unsigned long nr_segs, loff_t pos)
{
struct sock_iocb siocb, *x;
x = alloc_sock_iocb(iocb, &siocb);
return do_sock_write(&x->async_msg, iocb, iocb->ki_filp, iov, nr_segs);
}
//最终调用的是readmsg
static ssize_t sock_aio_read(struct kiocb *iocb, const struct iovec *iov,
unsigned long nr_segs, loff_t pos)
{
struct sock_iocb siocb, *x;
x = alloc_sock_iocb(iocb, &siocb);
return do_sock_read(&x->async_msg, iocb, iocb->ki_filp, iov, nr_segs);
}
因为前面在tcp_prot中已经将sendmsg赋值为tcp_sendmsg,将recvmsg赋值为了tcp_recvmsg,随意网络收发包对应的实际操作即为这两个。
5.4 发送数据
net/ipv4/tcp.c
int tcp_sendmsg(struct kiocb *iocb, struct sock *sk, struct msghdr *msg,
size_t size)
{
struct iovec *iov;
struct tcp_sock *tp = tcp_sk(sk);
struct sk_buff *skb;
//iov结构即用户态空间中对应的要发送的数据
int iovlen = msg->msg_iovlen;
iov = msg->msg_iov;
copied = 0;
while (--iovlen >= 0) {
size_t seglen = iov->iov_len;
unsigned char __user *from = iov->iov_base;
iov++;
if (unlikely(offset > 0)) { /* Skip bytes copied in SYN */
if (offset >= seglen) {
offset -= seglen;
continue;
}
seglen -= offset;
from += offset;
offset = 0;
}
while (seglen > 0) {
int copy = 0;
int max = size_goal;
//skb是从发送队列sk_write_queue的尾部获取的sk_buff,这里max是一个sk_buff的最大长度,max-skb->len即是剩余仍可以写的空间,copy大于0时说明现有sk_buff仍然有剩余
skb = tcp_write_queue_tail(sk);
if (tcp_send_head(sk)) {
if (skb->ip_summed == CHECKSUM_NONE)
max = mss_now;
copy = max - skb->len;
}
if (copy <= 0) {
new_segment:
//判断现在正在发送的数据量小于发送缓存才可以
if (!sk_stream_memory_free(sk))
goto wait_for_sndbuf;
//select_size用于计算此次需要申请的payload空间,随后该函数申请payload大小的内存,并增加sk_forward_alloc计数;该函数中对tcp_mem、tcp_wmem、sk_sndbuf都做了判断,确定内存是否可以成功分配
skb = sk_stream_alloc_skb(sk,
select_size(sk, sg),
sk->sk_allocation);
//如果上一步申请内存不成功,首先将现有的包发送到网络,以便释放空间
if (!skb)
goto wait_for_memory;
if (tp->repair)
TCP_SKB_CB(skb)->when = tcp_time_stamp;
if (sk->sk_route_caps & NETIF_F_ALL_CSUM)
skb->ip_summed = CHECKSUM_PARTIAL;
//将sk_buff加入到sk_write_queue发送链表的尾部,增加本次申请字节数到sk_wmem_queued,减少sk_forward_alloc字节数
skb_entail(sk, skb);
copy = size_goal;
max = size_goal;
}
/* Try to append data to the end of skb. */
if (copy > seglen)
copy = seglen;
//skb_availroom计算sk_buff中还有多少申请的内存未使用,然后调用skb_add_data_nocache将copy和改剩余内存之间小值对应的数据从用户态的iovec拷贝到内核态的sk_buff
if (skb_availroom(skb) > 0) {
/* We have some space in skb head. Superb! */
copy = min_t(int, copy, skb_availroom(skb));
err = skb_add_data_nocache(sk, skb, from, copy);
if (err)
goto do_fault;
} else {
bool merge = true;
int i = skb_shinfo(skb)->nr_frags;
struct page_frag *pfrag = sk_page_frag(sk);
//sk_buff中没有剩余内存了,这里通过sk_page_frag_refill新申请内存页并附给sk_buff,具体的说会赋值给sk_buff中对应的skb_shared_info分片上
if (!sk_page_frag_refill(sk, pfrag))
goto wait_for_memory;
if (!skb_can_coalesce(skb, i, pfrag->page,
pfrag->offset)) {
if (i == MAX_SKB_FRAGS || !sg) {
tcp_mark_push(tp, skb);
goto new_segment;
}
merge = false;
}
copy = min_t(int, copy, pfrag->size - pfrag->offset);
//增加sk_forward_alloc计数,该函数中对tcp_mem、tcp_wmem、sk_sndbuf都做了判断,确定内存是否可以成功分配,超出了限制的话会将申请的内存释放掉
if (!sk_wmem_schedule(sk, copy))
goto wait_for_memory;
err = skb_copy_to_page_nocache(sk, from, skb,
pfrag->page,
pfrag->offset,
copy);
if (err)
goto do_error;
//如果需要拷贝的数据能合并到skb_shared_info正指向的page则合并,否则新建page,将copy的数据直接放到新page中
if (merge) {
skb_frag_size_add(&skb_shinfo(skb)->frags[i - 1], copy);
} else {
skb_fill_page_desc(skb, i, pfrag->page,
pfrag->offset, copy);
get_page(pfrag->page);
}
//更新整个sk_buff的offset加上新拷贝的字节数
pfrag->offset += copy;
}
if (!copied)
TCP_SKB_CB(skb)->tcp_flags &= ~TCPHDR_PSH;
//更新write_seq的值加上新copy的字节数,write_seq指向send_buffer中tail+1的位置
tp->write_seq += copy;
TCP_SKB_CB(skb)->end_seq += copy;
skb_shinfo(skb)->gso_segs = 0;
from += copy;
copied += copy;
if ((seglen -= copy) == 0 && iovlen == 0)
goto out;
if (skb->len < max || (flags & MSG_OOB) || unlikely(tp->repair))
continue;
if (forced_push(tp)) {
tcp_mark_push(tp, skb);
__tcp_push_pending_frames(sk, mss_now, TCP_NAGLE_PUSH);
} else if (skb == tcp_send_head(sk))
tcp_push_one(sk, mss_now);
continue;
wait_for_sndbuf:
set_bit(SOCK_NOSPACE, &sk->sk_socket->flags);
wait_for_memory:
if (copied)
tcp_push(sk, flags & ~MSG_MORE, mss_now, TCP_NAGLE_PUSH);
if ((err = sk_stream_wait_memory(sk, &timeo)) != 0)
goto do_error;
mss_now = tcp_send_mss(sk, &size_goal, flags);
}
}
out:
//tcp_push实际调用tcp_write_xmit函数,实际构造tcp segment并发送,该函数在下方介绍
if (copied)
tcp_push(sk, flags, mss_now, tp->nonagle);
release_sock(sk);
//返回成功拷贝到发送队列的字节数,因为发送缓存没有内存可以申请时,会跳出上面的while循环,所以这里的copied并不一定包含有全部iovec数据
return copied + copied_syn;
do_fault:
if (!skb->len) {
tcp_unlink_write_queue(skb, sk);
/* It is the one place in all of TCP, except connection
* reset, where we can be unlinking the send_head.
*/
tcp_check_send_head(sk, skb);
sk_wmem_free_skb(sk, skb);
}
do_error:
if (copied + copied_syn)
goto out;
out_err:
err = sk_stream_error(sk, flags, err);
release_sock(sk);
return err;
}
static bool tcp_write_xmit(struct sock *sk, unsigned int mss_now, int nonagle,
int push_one, gfp_t gfp)
{
//获取发送列表中的首元素
while ((skb = tcp_send_head(sk))) {
unsigned int limit;
//确定是否设置的tso,可以发送超出mtu的数据量
tso_segs = tcp_init_tso_segs(sk, skb, mss_now);
BUG_ON(!tso_segs);
//探测发送窗口的大小
cwnd_quota = tcp_cwnd_test(tp, skb);
if (!cwnd_quota) {
if (push_one == 2)
cwnd_quota = 1;
else
break;
}
//探测接收窗口大小
if (unlikely(!tcp_snd_wnd_test(tp, skb, mss_now)))
break;
limit = max_t(unsigned int, sysctl_tcp_limit_output_bytes,
sk->sk_pacing_rate >> 10);
limit = mss_now;
//这里给 limit 赋值为发送窗口、接收窗口、sk_buff本身的len和mtu乘以分片数量(mss_now * max_segs)的最小值
if (tso_segs > 1 && !tcp_urg_mode(tp))
limit = tcp_mss_split_point(sk, skb, mss_now,
min_t(unsigned int,
cwnd_quota,
sk->sk_gso_max_segs));
//如果sk_buff的len超过了limit大小,就会将sk_buff拆分为两个,先后发送
if (skb->len > limit &&
unlikely(tso_fragment(sk, skb, limit, mss_now, gfp)))
break;
TCP_SKB_CB(skb)->when = tcp_time_stamp;
//给sk_buff附加上tcp头,创建一个tcp包,最后通过ip_queue_xmit将其发送到ip层
if (unlikely(tcp_transmit_skb(sk, skb, 1, gfp)))
break;
//获取下一个要发送的sk_buff
tcp_event_new_data_sent(sk, skb);
}
}
//网络分层只是为了讲解认为划分的,实际实现时界限并不明显;tcp层给网络包申请了内存并附件上tcp头,然后通过参数传给ip层调用,并没有重新分配空间,依然使用的tcp层申请的sk_buff,另外添加上了ip头
int ip_queue_xmit(struct sk_buff *skb, struct flowi *fl)
{
struct rtable *rt;
struct iphdr *iph;
//确定ip地址是否可以路由
rt = skb_rtable(skb);
rt = (struct rtable *)__sk_dst_check(sk, 0);
//给sk_buff添加ip头
skb_push(skb, sizeof(struct iphdr) + (inet_opt ? inet_opt->opt.optlen : 0));
skb_reset_network_header(skb);
iph = ip_hdr(skb);
*((__be16 *)iph) = htons((4 << 12) | (5 << 8) | (inet->tos & 0xff));
if (ip_dont_fragment(sk, &rt->dst) && !skb->local_df)
iph->frag_off = htons(IP_DF);
else
iph->frag_off = 0;
iph->ttl = ip_select_ttl(inet, &rt->dst);
iph->protocol = sk->sk_protocol;
ip_copy_addrs(iph, fl4);
//调用ip_output将包发送出去,这里如果sk_buff长度大于mtu并且没有设置tso,则会调用ip_fragment进行分片并再次调用ip_out发送;如果设置了tso,则在该函数中直接添加以太网头部并发送
res = ip_local_out(skb);
rcu_read_unlock();
return res;
}
//最终完整的报文通过 dev_queue_xmit 传输
int dev_queue_xmit(struct sk_buff *skb)
{
struct net_device *dev = skb->dev;
struct netdev_queue *txq;
//重新设置以太网头
skb_reset_mac_header(skb);
if (!netif_xmit_stopped(txq)) {
__this_cpu_inc(xmit_recursion);
//调用网卡驱动实际发送数据,并且在网卡驱动这一层对设置了gso的sk_buff进行了分片,相当于在网卡上拆分的分片,这也导致了使用tcpdump抓到的分片和实际发送到网络上的并不相同
rc = dev_hard_start_xmit(skb, dev, txq);
__this_cpu_dec(xmit_recursion);
if (dev_xmit_complete(rc)) {
HARD_TX_UNLOCK(dev, txq);
goto out;
}
}
//释放sk_buff
kfree_skb(skb);
return rc;
}
5.5 接收数据
接收数据的流程大致就是从网络上接收到报文,然后一路网上送到 socket 接收缓存中。net_rx_action 是收到报文的软件中断处理函数,首先,请求 napi poll 的驱动被从 poll_list 中拿出来,然后调用驱动的 poll handler。
net/core/dev.c
static void net_rx_action(struct softirq_action *h)
{
n = list_first_entry(&sd->poll_list, struct napi_struct, poll_list);
//将rx_ring中的sk_buff数据拷贝到在内存中新建的sk_buff中,并将原来的sk_buff还给rx_ring
work = n->poll(n, weight);
//将数据发送给tcp层,实际调用的napi_gro_complete函数,继而调用了netif_receive_skb
napi_gro_flush(n, HZ >= 1000);
}
其中pool的定义在drivers/net/ethernet/intel/e1000e/netdev.c中,e1000e_poll函数。
static int e1000e_poll(struct napi_struct *napi, int weight)
{
struct e1000_adapter *adapter = container_of(napi, struct e1000_adapter, napi);
struct e1000_hw *hw = &adapter->hw;
struct net_device *poll_dev = adapter->netdev;
//使用在e1000_alloc_rx_buffers函数中给网卡驱动分配的sk_buff组成的rings,因为这里还在网卡这一层,收到的还仅是ip包,所以网卡的rx rings中的sk_buff分配的都是ip包大小1518字节, clean_rx函数就是用来从缓冲队列中接收全部数据,实际调用e1000_clean_rx_irq函数
adapter->clean_rx(adapter->rx_ring, &work_done, weight);
return;
}
static bool e1000_clean_rx_irq(struct e1000_ring *rx_ring, int *work_done,
int work_to_do)
{
//获取rx_ring中下一个需要处理的sk_buff
i = rx_ring->next_to_clean;
buffer_info = &rx_ring->buffer_info[i];
while (staterr & E1000_RXD_STAT_DD) {
//取出需要处理的sk_buff中的数据,并将待处理的buff向后移动一个
skb = buffer_info->skb;
buffer_info->skb = NULL;
prefetch(skb->data - NET_IP_ALIGN);
i++;
if (i == rx_ring->count)
i = 0;
next_buffer = &rx_ring->buffer_info[i];
//新建一个sk_buff结构,并将rx_ring中待处理的sk_buff中的数据拷贝给它
if (length < copybreak) {
struct sk_buff *new_skb = netdev_alloc_skb_ip_align(netdev, length);
if (new_skb) {
skb_copy_to_linear_data_offset(new_skb, -NET_IP_ALIGN, (skb->data - NET_IP_ALIGN), (length + NET_IP_ALIGN));
buffer_info->skb = skb;
skb = new_skb;
}
}
cleaned_count++;
//计算数据完整性
e1000_rx_checksum(adapter, staterr, skb);
//拆掉以太网包头
e1000_receive_skb(adapter, netdev, skb, staterr, rx_desc->wb.upper.vlan);
//当处理的rx_ring中的sk_buff超过一个阈值后,将其数据清空以便rx_ring继续使用
if (cleaned_count >= E1000_RX_BUFFER_WRITE) {
adapter->alloc_rx_buf(rx_ring, cleaned_count,
GFP_ATOMIC);
cleaned_count = 0;
}
}
int netif_receive_skb(struct sk_buff *skb)
{
//根据协议的类型将数据传递给了上层的的处理函数,这里对应的是ip_rcv
type = skb->protocol;
list_for_each_entry_rcu(ptype,
&ptype_base[ntohs(type) & PTYPE_HASH_MASK], list) {
if (ptype->type == type &&
(ptype->dev == null_or_dev || ptype->dev == skb->dev ||
ptype->dev == orig_dev)) {
if (pt_prev)
ret = deliver_skb(skb, pt_prev, orig_dev);
pt_prev = ptype;
}
}
}
net/ipv4/ip_input.c
//ip_rcv 函数执行 IP 层的任务,它会先检查报文的长度和头部的 checksum
int ip_rcv(struct sk_buff *skb, struct net_device *dev, struct packet_type *pt, struct net_device *orig_dev)
{
iph = ip_hdr(skb);
return NF_HOOK(NFPROTO_IPV4, NF_INET_PRE_ROUTING, skb, dev, NULL,
ip_rcv_finish);
}
static int ip_rcv_finish(struct sk_buff *skb)
{ //调用ip_route_input_slow,继而调用ip_local_deliver、ip_local_deliver_finish
ip_route_input_noref(skb, iph->daddr, iph->saddr, iph->tos, skb->dev);
}
//将ip包传递给上一层,这里还会对ip分片进程组装,合成在发送端发送时发送的完整的tcp包
int ip_local_deliver(struct sk_buff *skb)
{
//如果ip是tcp包的一个分片
if (ip_is_fragment(ip_hdr(skb))) {
//前面说到发送数据时在网卡驱动层对数据分片,接收数据时在此函数中对合并分片;网卡中收到的ip分片都是小于mtu大小的,保存在分散的sk_buff中,此处会将ip分片按照数据发送时的tcp包大小进行合并,合并成功后在ip_local_deliver_finish转给tcp层,否则丢弃
if (ip_defrag(skb, IP_DEFRAG_LOCAL_DELIVER))
return 0;
}
return NF_HOOK(NFPROTO_IPV4, NF_INET_LOCAL_IN, skb, skb->dev, NULL,
ip_local_deliver_finish);
}
//
static int ip_local_deliver_finish(struct sk_buff *skb)
{
//移除ip头部
__skb_pull(skb, skb_network_header_len(skb));
int protocol = ip_hdr(skb)->protocol;
const struct net_protocol *ipprot;
//此处对应的是tcp_protocol,对应的处理函数是tcp_v4_rcv
ret = ipprot->handler(skb);
}
int tcp_v4_rcv(struct sk_buff *skb)
{
const struct iphdr *iph;
const struct tcphdr *th;
th = tcp_hdr(skb);
//如果设置了DMA,则调用tcp_v4_do_rcv函数;否则写入prequeue
#ifdef CONFIG_NET_DMA
struct tcp_sock *tp = tcp_sk(sk);
ret = tcp_v4_do_rcv(sk, skb);
#endif
{
tcp_prequeue(sk, skb);
}
}
tcp_v4_do_rcv调用tcp_rcv_established,该函数中在收到乱序的tcp包、接收窗口为0或者没有足够的buffer的情况下执行慢速处理,否则执行fast path
int tcp_rcv_established(struct sock *sk, struct sk_buff *skb, const struct tcphdr *th, unsigned int len)
{
//判断是否能进入fast path
if ((tcp_flag_word(th) & TCP_HP_BITS) == tp->pred_flags &&
TCP_SKB_CB(skb)->seq == tp->rcv_nxt &&
!after(TCP_SKB_CB(skb)->ack_seq, tp->snd_nxt)) {
if (len <= tcp_header_len){
//如果接收端检测到有乱序数据这些情况时都会发送一个纯粹的ACK包给发送端
if (tcp_header_len == (sizeof(struct tcphdr) + TCPOLEN_TSTAMP_ALIGNED) && tp->rcv_nxt == tp->rcv_wup)
tcp_store_ts_recent(tp);
tcp_ack(sk, skb, 0);
__kfree_skb(skb);
tcp_data_snd_check(sk);
return 0;
} else {
int eaten = 0;
int copied_early = 0;
bool fragstolen = false;
//此数据包刚好是下一个读取的数据,并且用户空间可存放下该数据包
if (tp->copied_seq == tp->rcv_nxt && len - tcp_header_len <= tp->ucopy.len) {
#ifdef CONFIG_NET_DMA
if (tp->ucopy.task == current && sock_owned_by_user(sk) && tcp_dma_try_early_copy(sk, skb, tcp_header_len)) {
copied_early = 1;
eaten = 1;
}
#endif
//如果该函数在进程上下文中调用并且sock被用户占用的话
if (tp->ucopy.task == current && sock_owned_by_user(sk) && !copied_early) {
__set_current_state(TASK_RUNNING);
//直接拷贝到用户空间
if (!tcp_copy_to_iovec(sk, skb, tcp_header_len))
eaten = 1;
}
if (eaten) {
if(tcp_header_len == (sizeof(struct tcphdr) + TCPOLEN_TSTAMP_ALIGNED) && tp->rcv_nxt == tp->rcv_wup)
tcp_store_ts_recent(tp);
tcp_rcv_rtt_measure_ts(sk, skb);
__skb_pull(skb, tcp_header_len);
tp->rcv_nxt = TCP_SKB_CB(skb)->end_seq;
NET_INC_STATS_BH(sock_net(sk), LINUX_MIB_TCPHPHITSTOUSER);
}
if (copied_early)
tcp_cleanup_rbuf(sk, skb->len);
}
//如果没有直接拷贝到用户空间
if (!eaten) {
if (tcp_checksum_complete_user(sk, skb))
goto csum_error;
//如果
if ((int)skb->truesize > sk->sk_forward_alloc)
goto step5;
//进入receive queue 排队,以待tcp_recvmsg
eaten = tcp_queue_rcv(sk, skb, tcp_header_len,
&fragstolen);
}
//每次接收到来自对方的一个TCP数据报,且数据报长度大于128字节时,我们需要调用tcp_grow_window,
增加rcv_ssthresh的值,一般每次为rcv_ssthresh增长两倍的mss,增加的条件是rcv_ssthresh小于window_clamp,
并且 rcv_ssthresh小于接收缓存剩余空间的3/4,同时tcp_memory_pressure没有被置位
tcp_event_data_recv(sk, skb);
//如果直接复制到了用户空间,这里将sk_buff释放掉
if (eaten)
kfree_skb_partial(skb, fragstolen);
//sk->sk_data_ready的实例为sock_def_readable(),当sock有输入数据可读时,会调用此函数来处理。
sk->sk_data_ready(sk, 0);
return 0;
}
}
slow_path:
if (len < (th->doff << 2) || tcp_checksum_complete_user(sk, skb))
goto csum_error;
if (!th->ack && !th->rst)
goto discard;
if (!tcp_validate_incoming(sk, skb, th, 1))
return 0;
step5:
if (tcp_ack(sk, skb, FLAG_SLOWPATH | FLAG_UPDATE_TS_RECENT) < 0)
goto discard;
tcp_rcv_rtt_measure_ts(sk, skb);
tcp_urg(sk, skb, th);
tcp_data_queue(sk, skb);
tcp_data_snd_check(sk);
tcp_ack_snd_check(sk);
return 0;
}
net/core/sock.c
static void sock_def_readable(struct sock *sk, int len)
{
struct socket_wq *wq;
rcu_read_lock();
wq = rcu_dereference(sk->sk_wq);
//这里实际唤醒的是tcp_recvmsg函数,将sk_buff中的数据拷贝到用户空间
if (wq_has_sleeper(wq))
wake_up_interruptible_sync_poll(&wq->wait, POLLIN | POLLPRI |
POLLRDNORM | POLLRDBAND);
sk_wake_async(sk, SOCK_WAKE_WAITD, POLL_IN);
rcu_read_unlock();
}
net/ipv4/tcp.c
int tcp_recvmsg(struct kiocb *iocb, struct sock *sk, struct msghdr *msg, size_t len, int nonblock, int flags, int *addr_len)
{
// copied是指向用户空间拷贝了多少字节,即读了多少
int copied = 0;
// target指的是期望多少字节
int target;
//大循环
do {
u32 offset;
//小循环
skb_queue_walk(&sk->sk_receive_queue, skb) {
offset = *seq - TCP_SKB_CB(skb)->seq;
if (tcp_hdr(skb)->syn)
offset--;
//如果读取到的数据长度不够整个sk_buff
if (offset < skb->len)
goto found_ok_skb;
//如果读取了整个sk_buff
if (tcp_hdr(skb)->fin)
goto found_fin_ok;
}
//拷贝到用户态空间
found_ok_skb:
/* Ok so how much can we use? */
used = skb->len - offset;
if (len < used)
used = len;
//将本次读取到的数据发送给用户
skb_copy_datagram_iovec(skb, offset, msg->msg_iov, used);
*seq += used;
copied += used;
len -= used;
}while (len > 0);
//整个sk_buff已经拷贝完成
found_ok_skb:
used = skb->len - offset;
if (len < used)
used = len;
//释放sk_buff
sk_eat_skb(sk, skb, copied_early);
}
6. 总结
7. 作者介绍
梁明远,国防科大并行与分布式计算国家重点实验室(PDL)应届研究生,14年入学伊始便开始接触docker,准备在余下的读研时间在docker相关开源社区贡献自己的代码,毕业后准备继续从事该方面研究。邮箱:[email protected]
8. 参考文献
https://wwwx.cs.unc.edu/~sparkst/howto/network_tuning.php
http://www.zhongruitech.com/149155646.html
http://abcdxyzk.github.io/posts/40/
https://www.bbsmax.com/A/MyJxqORA5n/
https://blog.csdn.net/wenqian1991/article/details/46707521
https://cizixs.com/2017/07/27/understand-tcp-ip-network-stack/
https://blog.csdn.net/justlinux2010/article/details/17376711
https://zhuanlan.zhihu.com/p/25241630
https://www.cnblogs.com/listenerln/p/6393047.html
https://my.oschina.net/alchemystar/blog/1791017
https://blog.csdn.net/farmwang/article/details/54233975
9. 基础支持记录
- ack是累积校验,前面有小的ack未发送时,不会发送后面的编号大的;一旦发送端接收到大的ack,说明其前面左右的seq都已经成功发送
- 发送方发送多个包填充接收窗口后,必须等待ack再次通报接收窗口大小
- 接收窗口变小是因为应用程序读取慢
- 发送窗口和接收窗口耗尽的时候都需要等待ack
- 快速重传是指发送方连续接收到3个相同的ack,而超时是指长时间未接收到ack
- 若接收端接收到失序的datagram,TCP窗口会一直保存这些失序的报文,而不是交给用户进程,这将占用窗口大小;tcp层的datagram乱序到达接收端后,只要其前面没再有丢包,会重新排序;然后交由用户进程读取
- 开启tso后,tcp发送时不再分片,而是交由IP层分片,接收方IP层重组分片后借给tcp层;假如分片不完整则不再交付,该种方式有任何一个分片丢失都会导致整个tcp包重发;优势是tcp层可以一次分派更大内存,减少内存申请次数
- 关闭tso后,tcp层会根据1460字节分片后再发送给IP层,相当于tcp包大小与ip分片大小一直,分片丢失后仅需要重传该分片
- read()调用会尝试一次性读取其设定的数据,但由于tcp缓冲区不一定有足够的数据,所以该调用会返回成功读取的字节数,上层应用自己应该用循环保证可以读取所有数据
10.sendmsg()调用是将数据从用户态写入tcp缓冲,当缓冲区满足该次仅能写入部分数据,并返回写成功的字节数;上层数据应做考虑未能一次写入成功时剩余的数据再次发送