构造析构相关以及构造顺序,String类的实现
构造析构顺序
拷贝构造
String类
目录
1.构造函数和析构函数
1)使用初始化表来实现对数据成员的初始化
2)关于构造函数C++规定:
3)拷贝构造函数和默认拷贝构造函数
4)拷贝构造函数和赋值函数
5)类对象作为成员
6)关于类的两种初始化方式
7)派生类构造函数:
8)派生类析构函数
9)构造和析构顺序
10)析构顺序笔试题
2.String类
3.在类的派生类中实现类的基本函数
1.构造函数和析构函数
构造函数:在创建对象时,系统自动调用它来初始化数据成员。构造函数可以重载。
析构函数:在对象生命周期结束的时候,自动调用来释放该对象。一个类只能定义一个析构函数,析构函数不能重载。
class Cdate
{
public:
Cdate(int y, int m,int d);
private:
int year;
int month;
int day;
};1)使用初始化表来实现对数据成员的初始化
初始化表的一般格式:
类名::构造函数名(参数列表):初始化表
{
构造函数其他实现代码
}
初始化表的格式:
对象成员1(参数名或常量),对象成员2(参数名或常量),……对象成员n(参数名或常量)
例如CDate的构造函数可以改用以下形式:
Cdate:: Cdate(int y, int m,int d): year(y), month(m),day(d){ }
2)关于构造函数C++规定:
(1)每个类必须有一个构造函数,如果没有就不能创建任何对象;
(2)若没有定义任何一个构造函数,C++提供一个默认的构造函数,该构造函数没有参数,不做任何工作,相当一个空函数,例如:
Cdate::Cdate()
{ }
所以在讲构造函数以前也可以定义一个对象,就是因为系统提供的默认构造函数。
(3)只要C++提供一个构造函数(不一定是没有参数的),C++不再提供默认的构造函数。也就是说为类定义了一个带参数的构造函数,还想要创建无参的对象时,则需要自己定义一个默认构造函数 。
3)拷贝构造函数和默认拷贝构造函数
·拷贝构造函数的作用:用一个已知对象来初始化另一个对象。
·拷贝构造函数定义格式
类名::拷贝构造函数名(类名& 引用名)
Tdate ::Tdate(Tdate & d); //形参是一个对象的引用
CString( const CString & stringSrc );
·通常在下述三种情况下,需要用拷贝初始化构造函数:
(1)明确表示由一个对象初始化另一个对象时;如Cdate day3(d1);
(2)当对象作为函数实参传递给函数形参时;如 fun(Cdate day);
(3)当对象作为函数的返回值,创建一个临时对象时。(因为返回的局部变量在函数结束时已被销毁,所以编译器都会先建立一个此对象的临时拷贝,而在建立该临时拷贝时就会调用类的拷贝构造函数。)
#include
class CComplex
{
public:
CComplex(double, double);
CComplex(CComplex &c);
CComplex add(CComplex & x);
void Print();
private:
double real;
double imag;
};
CComplex::CComplex (double r=0.0, double i=0.0)
{
real = r;
imag = i;
cout<<"调用两个参数的构造函数"<
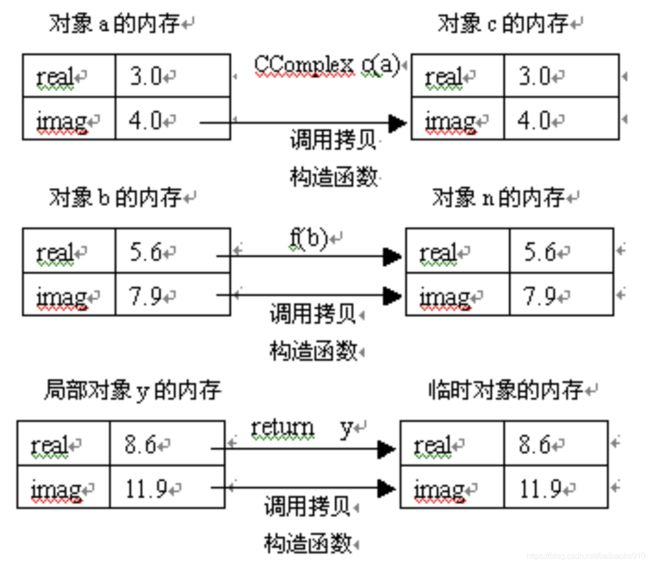
当用户自定义了拷贝构造函数,所用一个对象创建另一个对象时,系统自动调用了用户自定义拷贝构造函数。如果用户没有自己定义拷贝构造函数,那么编译系统会自动会提供一个默认的拷贝构造函数。
默认的拷贝构造函数所做的工作是将一个对象的全部数据成员赋值另一个对象的数据成员。C++把这种只进行对象数据成员简单赋值,称之为“浅拷贝”。
#include
#include
class CClass
{
public:
CClass (char *cName="",int snum=0);
~ CClass ();
void Print();
private:
char * pname;
int num;
};
CClass::CClass (char *cName,int snum)
{
int length = strlen(cName);
pname = new char[length+1];
if (pname!=NULL)
{
strcpy(pname,cName);
}
num=snum;
cout<<"创建班级:"<
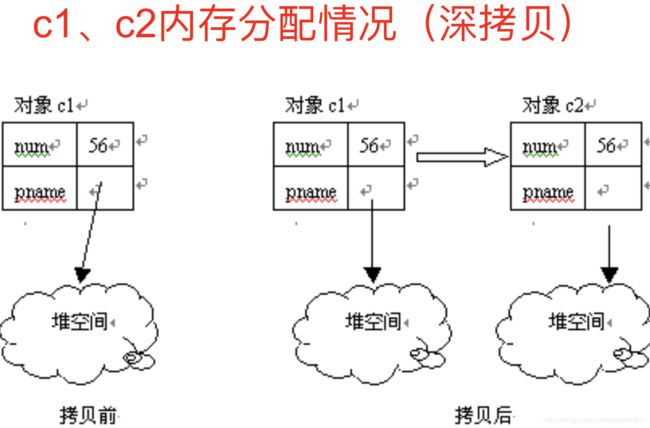
此时c1,c2内存分配情况(调用默认拷贝构造函数,浅拷贝)

默认构造函数的浅拷贝意味着执行c2.pname = c1.pname.这将造成三个错误:一是c1.pname和c2.pname指向同一块内存,c1或c2任意一方变动都会影响另一方。二是对象被析构时pnme被释放了两次。
应自定义一个深拷贝的拷贝构造函数
CClass (CClass &p)
{
pname = new char[strlen(p.pname )+1];
if (pname!=0)
{
strcpy(pname,p.pname);
}
num=p.num ;
cout<<"创建班级的拷贝:"<

4)拷贝构造函数和赋值函数
拷贝构造函数和赋值函数很容易混淆。拷贝构造函数时对象在创建时调用的,而赋值函数只能被已存在了的对象调用。
String a("hello");
String b("world");
String c = a;//调用了拷贝构造函数,最好写成c(a);
c = b;//调用了赋值函数
5)类对象作为成员
有类对象作为成员称为组合类
·通过构造函数的初始化表为内嵌对象初始化
格式为:
类名::构造函数(参数表):内嵌对象1(参数表1),内嵌对象2(参数表2),…
{
构造函数体
}
·组合类构造函数的执行顺序为:
(1)按内嵌对象的声明顺序依次调用内嵌对象的构造函数
(2)然后执行组合类本身的构造函数。
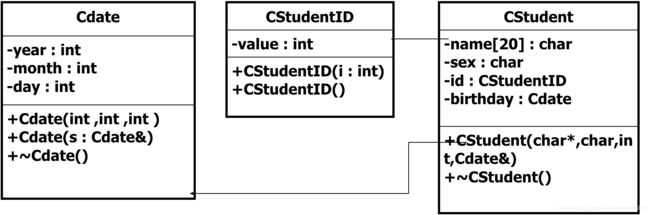
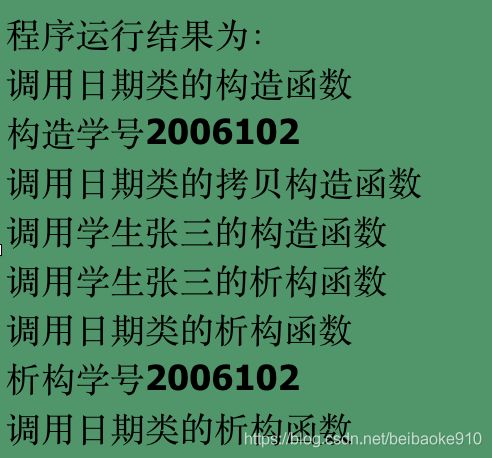
#include
#include
class Cdate
{
public:
Cdate(int y=1985, int m=1,int d=1)
{
year=y;
month=m;
day=d;
cout<<"调用日期类的构造函数"<
6)关于类的两种初始化方式
class A
{...
A(int x);//A的构造函数
};
class B: public A
{...
B(int x, int y);//B的构造函数
};
B::B(int x, int y): A(x)//在初始化表里调用A的构造函数
{
...
}
初始化表位于函数参数表之后,却在函数体{}之前。说明该表里的初始化工作发生在函数体内的任何代码被执行之前。
·如果类存在继承关系,派生类必须在其初始化表里调用基类的构造函数
·类的数据成员可以采用初始化表或函数体内赋值两种方式,这两种方式的效率不完全相同。
非内部数据类型的成员对象应当采用第一种方式初始化,以获取更高效率。例如:
class A
{...
A();//无参构造函数
A(const A &other);//拷贝构造函数
A & operate =(const A &other);//赋值函数
};
class B
{
public:
B(const A &a);//B的构造函数
private:
A m_a;//成员对象
};
示例(a)
B::B(const A &a) :m_a(a)
{
...
}
示例(b)
B::B(const A &a)
{
m_a = a;
...
}
示例(a)中,类B的构造函数在其初始化表里调用了类A的拷贝构造函数,从而将成员对象m_a初始化。
示例(b)中,类B的构造函数在函数体内用赋值的方式将成员对象m_a初始化。我们看到的只是一条赋值语句,但实际上B的构造函数干了两件事:先暗地里创建m_a对象(调用了A的无参构造函数),再调用类A的赋值函数,将参数a赋给m_a.
示例(a)成员对象在初始化表中被初始化,示例(b)在函数体内被初始化。
对于内部数据类型的数据成员而言,两种初始化方式的效率几乎没有区别,但后者的似乎更清晰些。
7)派生类构造函数:
构造函数和析构函数是不能被继承的。
派生类的成员是由基类中的数据成员和派生类中新增的数据成员共同构成。
对继承过来的基类成员的初始化工作也得由派生类的构造函数完成。也就是说在定义派生类的构造函数时,既要初始化派生类新增数据,又要初始化基类的成员。
所以,在定义派生类的构造函数时,有两步需要做:
l编写代码完成自己的数据成员进行初始化
l调用基类构造函数使基类数据成员得以初始化。
单一继承的构造函数的定义形式为:
派生类名: 派生类构造函数名(参数总表) : 基类构造函数名 (参数名表)
{
派生类新增成员的初始化语句
};
定义派生类的构造函数时,在构造函数的参数总表中包括基类构造函数所需的参数和派生类新增的数据成员初始化所需的参数。冒号后面基类构造函数名 (参数名表),表示要调用基类的构造函数。
一个派生类中新增加的成员可以是简单的数据成员,也可以是类对象。派生类可以是单一继承,也可以是多重继承。假如派生类是多重继承,并且新增数据成员有一个或多个类对象,那么派生类需要初始化的数据有三部分:继承的成员、新增类对象的成员和新增普通成员。这种复杂派生类的构造函数定义如下:
派生类名::派生类构造函数名(总参数表)
:基类构造函数名1 (参数表1),
基类构造函数名2 (参数表2), ……
子对象名1(参数表n),
子对象名2(数表n+1) ……
{
派生类新增普通数据成员的初始化;
}
8)派生类析构函数
析构函数的功能是做善后工作,析构函数无返回类型也没有参数。
派生类析构函数定义格式与非派生类无任何差异,只要在函数体内把派生类新增一般成员处理好就可以了。基类成员的善后工作,系统自己调用基类的析构函数来完成。
如果没有显示的定义析构函数,系统会自动生成一个默认的析构函数。
析构函数各部分执行次序与构造函数相反,首先对派生类新增成员析构,然后对基类成员析构。
9)构造和析构顺序
构造函数在创建对象时自动调用,调用的顺序是按照对象定义的次序。析构函数的调用顺序正好与构造函数相反。对于同一存储类别的对象是先构造的对象后析构,后构造的对象先析构。
派生类构造函数的调用顺序如下:
(1)基类构造函数。按它们在派生类定义中的先后顺序,依次调用。
(2)子对象的构造函数。按它们在派生类定义中的先后顺序(不受它们在初始化表中的次序的影响),依次调用。
(3)派生类的构造函数。
复杂派生类的析构函数,只需要编写对新增普通成员的善后处理,而对类对象和基类的善后工作是由类对象和基类的析构函数完成的。析构函数的调用顺序与构造函数相反。
10)析构顺序笔试题
下面代码输出是什么?
#include
using namespace std;
class C
{
int a;
public:
C(int aa=0) { a=aa; }
~C() { cout<<"Destructor C!"<
Destructor D!7
Destructor C!6
Destructor D!0
Destructor C!5
2.String类
每个类只有一个析构函数和一个赋值函数,但可以有多个构造函数(包括一个拷贝构造函数,其它的成为普通构造函数)。对于任意一个类A,如果不想编写上述函数,C++编译器将自动为A产生四个缺省的函数,如
A();//缺省的无参构造函数
A(const A &a);//缺省的拷贝构造函数
~A();//缺省的析构函数
A & operate =(const A &a);//缺省的赋值函数
既然能自动生成函数,为什么还要自己编写呢?
原因如下:
(1)如果使用“缺省的无参构造函数”和“缺省的析构函数”,等于放弃了自主“初始化”和“清除”的机会。
(2)“缺省的拷贝构造函数”和“缺省的赋值函数”均采用“位拷贝”而非“值拷贝”的方式实现,倘若类中含有指针变量,这两个函数注定将出错。
//String.h
#include
class String
{
public:
String(const char * str = NULL); //普通构造函数
String(const String &other); //拷贝构造函数
~String(); //析构函数
String & operator=(const String &other); //赋值函数
private:
char *m_data; //用于保存字符串
};
//String.cpp
#include "String.hpp"
#include
//String的普通构造函数
String::String(const char * str)
{
if(str == NULL)
{
m_data = new char[1];
*m_data = '\0';
}
else
{
int length = strlen(str);
m_data = new char[length+1];
strcpy(m_data, str);
}
}
//String的析构函数
String::~String()
{
if(m_data != NULL)
{
delete [] m_data;
}
}
//String的拷贝构造函数
String::String(const String &other)
{
//允许操作other的私有成员
int length = strlen(other.m_data);
m_data = new char[length+1];
strcpy(m_data, other.m_data);
}
//赋值函数
String & String::operator=(const String &other)
{
//(1)检查自赋值
if(this == &other)
{
return *this;
}
//(2)释放原有的内存资源
delete [] m_data;
//(3)分配新的内存资源,并复制内容
int length = strlen(other.m_data);
m_data = new char[length+1];
strcpy(m_data, other.m_data);
//(4)返回本对象的引用
return *this;
}
类String拷贝构造函数与普通构造函数的区别是:在函数入口处无需与NULL进行比较,这是因为“引用”不可能是NULL,而“指针”可以为NULL。
赋值函数分四步实现:
(1)第一步,检查自赋值。你可能会认为多此一举,难道有人会愚蠢到写出a=a这样的自赋值语句!的确不会。但是间接的自赋值仍有可能出现,例如
//内容自赋值
b = a;
...
c = b;
...
a = c;
//地址自赋值
b = &a;
...
a = *b;
也许有人会说“即使出现自赋值,可以不理睬,大不了花点时间让对象复制自己而已,反正不会出错。”
他真的说错了。看看第二步的delete,自杀后还能复制自己吗?所以,如果发现自赋值,应该立即终止函数。注意不要将检查自赋值的if语句
if(this == &other)
错写成
if(*this == other)
(2)第二步,用delete释放原有的内存资源。如果现在不释放,以后就没有机会了,将会造成内存泄漏。
(3)第三步,分配新的内存资源,并复制字符串。注意函数strlen返回的是有效字符串长度,不包含结束符'\0'。函数strcpy则连'\0'一起复制。
(4)第四步,返回本对象的引用,目的是为了实现对象a = b =c这样的链式表达。注意不要将return *this错写成 return this。那么能写成return other吗?效果不是一样?不可以,我们不知道参数other的生命周期。有可能other是个临时对象,在赋值结束后立马消失,那么return other返回的将是垃圾。另外,如果不采用“引用传递”的方式返回而采用“值传递”的方式,虽然功能仍然正确,但由于return语句要把*this拷贝到保存返回值的外部存储单元之中,增加了不必要的开销,降低了赋值函数的效率。如:
String a,b,c;
...
a = b;//如果用“值传递”,将产生一次*this拷贝
a = b = c;//如果用“值传递”,将产生两次*this拷贝
int a = 1;
int b = 2;
int c = 3;
a=b=c;
cout<
如果将a=b=c换成(a=b)=c,则输出结果就变成323,相当于是a=b,然后a=c(因为a=b返回的是对a的引用)。
若const A& operator=(const A& a);将返回值设成const是不正确的。a=b=c依然正确。(a=b)=c就不正确了。
在const A::operator=(const A& a)中,参数列表中的const的用法正确,而当这样连续赋值的时侯,问题就出现了:
A a,b,c:
(a=b)=c;
因为a.operator=(b)的返回值是对a的const引用,不能再将c赋值给const常量。
3.在类的派生类中实现类的基本函数
基类的构造函数、析构函数、赋值函数都不能被派生类继承。如果类之间存在继承关系,在编写上述基本函数时应该注意以下事项:
·派生类的构造函数应在其初始化表里调用基类的构造函数
·基类与派生类的析构函数应该为虚函数
·在编写派生类的赋值函数时,注意不要忘记对基类的数据成员重新赋值。例如:
class Base
{
public:
...
Base & operate =(const Base &other);//类Base的赋值函数
private:
int m_i;
int m_j;
int m_k;
};
class Derived : public Base
{
public:
...
Drived & operate =(const Derived &other);//类Drived的赋值函数
private:
int m_x;
int m_y;
int m_z;
};
Drived & Drived::operate =(const Derived &other)
{
//(1)检查自赋值
if(this == &other)
{
return *this;
}
//(2)对基类的数据成员重新赋值
Base::operate =(other);//因为不能直接操作私有数据成员
//(3)对派生类的数据成员赋值
m_x = other.m_x;
m_y = other.m_y;
m_z = other.m_z;
//(4)返回本对象的引用
return *this;
}
总结:构造析构顺序
不存在继承关系:对象成员(声明顺序),类本身
存在继承关系:基类,派生类对象成员,派生类
析构顺序则和构造顺序完全相反。