GAN做图像翻译的一点总结
作者丨洪佳鹏
学校丨北京大学
研究方向丨生成式对抗网络
本文经授权转载自公众号「学术兴趣小组」。
如今,随着 GAN 在生成清晰图像(sharp images)上的成功,GAN 在图像翻译任务上的方法越来越多,pix2pix,CycleGAN,UNIT,DTN,FaderNets,DistanceGAN,GeneGAN,pix2pixHD,StarGAN 等等。现在的方法太多了,图像质量也从 64x64 分辨率一路做到了 1024x2048。
我关注这个方向已经超过半年了,在这里总结一点小经验:
关于生成高质量图像
这里不谈怎么调参能够得到更好的结果,这里谈两个不用经过调参就能获得不错效果的方法。
有三个可以借鉴的经验,其一来自于 pix2pixHD,采用 multi-scale 的 Discriminator 和 coarse2fine 的 Generator 能够有效帮助提升生成的质量。
所谓 multi-scale 的 Discriminator 是指多个 D,分别判别不同分辨率的真假图像。比如采用 3 个 scale 的判别器,分别判别 256x256,128x128,64x64 分辨率的图像。至于获得不同分辨率的图像,直接经过 pooling 下采样即可。
Coarse2fine 的 Generator 是指先训一个低分辨率的网络,训好了再接一个高分辨率的网络,高分辨率网络融合低分辨率网络的特征得到更精细的生成结果。具体介绍可以参考 pix2pixHD [1]。
下图以及题图是 CelebA 数据上交换属性的实验,图像分辨率 256x256,如果单个 Discriminator,生成质量很差,加上 multi-scale 之后生成质量有了很大提升,并且没有经过调参哦。

△ 图1:交换刘海

△ 图2:交换眼镜
其二是采用 progressive growing 的训练方式,先训小分辨率,再逐渐增加网络层数以增大分辨率,这个跟 coarse2fine 有点像。具体可以参看 PGGAN [2],或者这里。
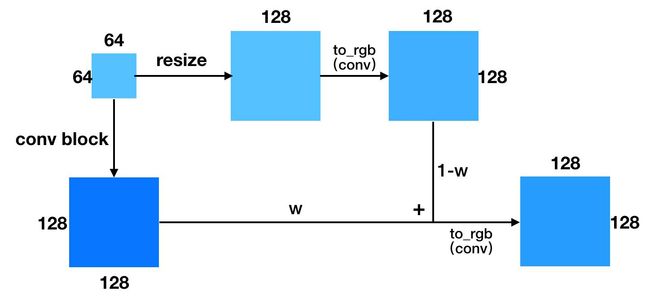
其三则是借鉴 LAPGAN 的做法,从低分辨率起步,通过不断生成高分辨率下的残差,累加得到高分辨率。图中 z1,z2,z3 是不同分辨率的输入。这个做法还没有尝试过,不知道生成质量怎样,图中的虚线是我认为可能不必要的连接。

关于生成样本多样性
这里其实有两个问题,一个是多模态多样性,一个是属性强弱的多样性。
对于多模态多样性,现有的技术不多,总结起来有三种。
其一,引入 noise,通过变分的方式让 noise 得到表达,获得多样性。这个方法来自于 BicycleGAN [3] 的 cVAE-GAN。

△ 图3:图片来自于 BicycleGAN [3]
其二,引入 noise,通过回归的方法在生成图像上预测所引入的 noise。这个方法失败率比较高。当然,它也可以跟第一种方法结合。具体介绍参考 BicycleGAN [3] 的 cLR-GAN。

△ 图4:图片来自于 BicycleGAN [3]
前两种方法都比较容易想到。在文章出来以前,我也曾经尝试过第二种方法,但是没有 work。这也印证了它失败率高。
第三种方法是通过交换来实现多模态。交换的图像可以是多种多样,一个不带属性的图,可以通过跟具有不同类型的刘海(眼镜、帽子等)的图片进行交换,以给目标人物加上不同类型的刘海(眼镜、帽子等)。这个方法可以参考 GeneGAN [4] 或者 DNA-GAN [5]。题图就是一个交换属性的例子。
另一种多样性是属性强弱。对于需要输入 label 的生成方法(如 FaderNets,StarGAN),可以通过控制喂给生成器的 label 强弱来得到生成图像的属性强弱。
关于属性强弱,有一类方法比较特殊,它没有办法实现,那就是 CycleGAN,因为它只需要输入图像,并不需要输入 label,没有控制 label 强弱的操作。
下面介绍一种原创的方法,能够对 CycleGAN 引入属性强弱的控制(不打算写成论文,因为没有什么特别的贡献,不想灌水。如使用该方法请注明出处)。
我们通过精简 CycleGAN 来实现,以两个域为例,原始 CycleGAN 需要 2 个 Generator 和 2 个 Discriminator,我们不难发现,可以把域转换称 condition,这样只需要一个 Generator 和 Discriminator 了。
不妨给两个域 X = {x_i} 和 Y = {y_j} 分别编码为 -1 和 1:
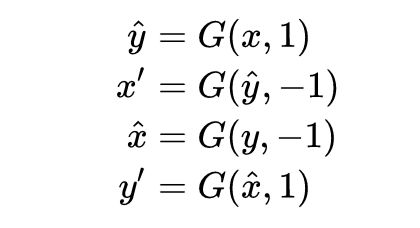
这样就实现了 x -> y -> x 和 y -> x -> y 的 cycle。剩下的跟 CycleGAN 一样即可。在测试的时候,就可以通过调节编码的强度来控制属性的强弱了。
关于 inference
模型训练好了,测试的时候还有一道关要过。虽然现在很多图像翻译方法训练的时候都不需要配对数据,但是它们都需要弱监督,也就是需要提供 label。
而测试集上我们不一定有 label,这其实是很常见的一个问题,用户上传的图像不会给你打好标签,况且还存在用户「故意」制造错误标签误导算法(测试算法性能)的可能。有什么解决方案呢?
我们很容易想到,加一个分类器,先分类具有什么属性,然后再转换属性。这个想法简单,但是需要额外的网络,会增加计算量。
有没有不引入分类器的方法呢?仍然以两个域互转的 CycleGAN 为例。训练的时候,我们强迫生成器具有分类器的功能。具体来说,生成器需要需要额外做两个任务(原创方法,没有发表,使用请注明出处):
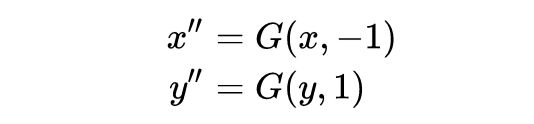
这两项的 loss 为重构误差:
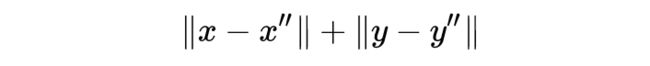
这可以说是一种自监督。这么做也就确保了生成器能够处理「故意误导」性的转换,也实现了 label-free 的 inference。
下图是季节转换的一个例子。图片从左到右依次为秋季原图、转成夏季图、夏季图转回秋季图、秋季原图转到秋季图。

△ 图5:label=0.5

△ 图6:label=1.0
注意到上图 checkerboard 效应很严重。怎么解决 checkerboard 呢?
关于 inference
生成模型很容易产生 checkerboard 效应,图像翻译任务尤为严重。据研究 [6],checkerboard 主要来自于反卷积(convolution transpose,通常也称 deconvolution)操作,而跟对抗训练关系不大。
[6] 指出,使用 nearest upsample + conv 替代 deconv 可以移除 checkerboard。在实验中我发现这个替换确实发现能够很好地解决问题。

△ 图7:反卷积带来了 overlap,从而引入了 checkerboard,图来自于[6]
替代 deconv 需要引入其他的上采样方法。上采样的方法除了 nearest upsample 和 bilinear upsample 等类型之外,还有一种不叫上采样,但是可以得到类似效果的操作:pixel shuffle [7]。它只改变了数据的摆放位置,(N, C*k^2, H, W) -> (N, C, kH, kW))。
这也是实现图像从小到大的方法,但是实验中我发现没有效果,可能是因为 channel 数太少。注意到 channel 数是增长是很快的,为了减少显存,减少卷积层数或者减少第一个卷积层的 channel 数都会影响网络的表达能力。
也就是说,目前比较好的解决方案还是使用 nearest upsample + conv 替代 deconv。
参考文献
1. Wang T C, Liu M Y, Zhu J Y, et al. High-Resolution Image Synthesis and Semantic Manipulation with Conditional GANs[J]. arXiv preprint arXiv:1711.11585, 2017.
2. Karras T, Aila T, Laine S, et al. Progressive growing of gans for improved quality, stability, and variation[J]. arXiv preprint arXiv:1710.10196, 2017.
3. Zhu J Y, Zhang R, Pathak D, et al. Multimodal Image-to-Image Translation by Enforcing Bi-Cycle Consistency[C]//Advances in Neural Information Processing Systems. 2017: 465-476.
备注:文章发表时是这个名字,但是后来改名了,找原文请搜 Toward Multimodal Image-to-Image Translation
4. Zhou S, Xiao T, Yang Y, et al. GeneGAN: Learning Object Transfiguration and Attribute Subspace from Unpaired Data[J]. arXiv preprint arXiv:1705.04932, 2017.
5. Xiao T, Hong J, Ma J. DNA-GAN: Learning Disentangled Representations from Multi-Attribute Images[J]. arXiv preprint arXiv:1711.05415, 2017.
6. https://distill.pub/2016/deconv-checkerboard
7. Shi W, Caballero J, Huszár F, et al. Real-time single image and video super-resolution using an efficient sub-pixel convolutional neural network[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2016: 1874-1883.
我是彩蛋
解锁新功能:热门职位推荐!
PaperWeekly小程序升级啦
今日arXiv√猜你喜欢√热门职位√
找全职找实习都不是问题
解锁方式
1. 识别下方二维码打开小程序
2. 用PaperWeekly社区账号进行登陆
3. 登陆后即可解锁所有功能
职位发布
请添加小助手微信(pwbot01)进行咨询
长按识别二维码,使用小程序
*点击阅读原文即可注册

关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。

