| 版权:本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接。如有问题,可以邮件:[email protected]
简介:
Multipath:这个多路径软件在Linux平台广泛使用,它的功能就是可以把一个快设备对应的多条路径聚合成一个单一的multipath device。主要目的有如下两点:
多路径冗余(redundancy):当配置在Active/Passive模式下,只有一半的路径会用来做IO,如果IO路径上有任何失败(包括,交换机故障,线路故障,后端存储故障等),可以自动切换的备用路线上,对上层应用做到基本无感知。
提高性能(Performance): 当配置在Active/Active模式下,所以路径都可以用来跑IO(如以round-robin模式),可以提高IO速率或者延时。
multipath不是本文的重点,如有需要,请移步:https://access.redhat.com/documentation/en-us/red_hat_enterprise_linux/7/html/dm_multipath/setup_overview
安装及使用:
Multipath:这个多路径软件在Linux平台广泛使用,在Debian/Ubuntu平台可以通过 sudo apt-get install multipath-tools 安装, RedHat/CentOS 平台可以通过 sudo yum install device-mapper-multipath 安装。
multipath.conf: multipath对于主流的存储阵列都有默认的配置,可以支持存储阵列的很多自带特性,如ALUA。当然用户可以在安装好后,手动创建/etc/multipath.conf
以下是VNX/Unity的参考配置(vnx cinder driver):
blacklist { # Skip the files under /dev that are definitely not FC/iSCSI devices # Different system may need different customization devnode "^(ram|raw|loop|fd|md|dm-|sr|scd|st)[0-9]*" devnode "^hd[a-z][0-9]*" devnode "^cciss!c[0-9]d[0-9]*[p[0-9]*]" # Skip LUNZ device from VNX device { vendor "DGC" product "LUNZ" } } defaults { user_friendly_names no flush_on_last_del yes } devices { # Device attributed for EMC CLARiiON and VNX series ALUA device { vendor "DGC" product ".*" product_blacklist "LUNZ" path_grouping_policy group_by_prio path_selector "round-robin 0" path_checker emc_clariion features "1 queue_if_no_path" hardware_handler "1 alua" prio alua failback immediate } }
Multipath在OpenStack中的应用及faulty device的产生:
OpenStack中,multipath可以使用在Nova和Cinder的节点上,提供对后端存储的高可用访问。在很早之前,这部分代码是分别在Nova和Cinder项目里面的,渐渐的为了维护方便,就单独拧出来一个项目:os-brick
os-brick里面很重要的两个interface是:connect_volume-负责链接一个存储上的LUN或者disk,disconnect_volume-辅助断开与存储上一个LUN的链接。
什么是faulty device
当host上multipath软件发现对应的host path不可访问时,就会显示为faulty状态。
关于所有状态的描述,可以参考:https://en.wikipedia.org/wiki/Linux_DM_Multipath
os-brick的代码我选择的是比较早期容易产生faulty device的版本:https://github.com/openstack/os-brick/blob/liberty-eol/os_brick/initiator/connector.py
1. connect_volume的主要逻辑如下:
1 @synchronized('connect_volume') 2 def connect_volume(self, connection_properties): 3 """Attach the volume to instance_name. 4 connection_properties for iSCSI must include: 5 target_portal(s) - ip and optional port 6 target_iqn(s) - iSCSI Qualified Name 7 target_lun(s) - LUN id of the volume 8 Note that plural keys may be used when use_multipath=True 9 """ 10 11 device_info = {'type': 'block'} 12 13 if self.use_multipath: 14 # Multipath installed, discovering other targets if available 15 try: 16 ips_iqns = self._discover_iscsi_portals(connection_properties) 17 except Exception: 18 raise exception.TargetPortalNotFound( 19 target_portal=connection_properties['target_portal']) 20 21 if not connection_properties.get('target_iqns'): 22 # There are two types of iSCSI multipath devices. One which 23 # shares the same iqn between multiple portals, and the other 24 # which use different iqns on different portals. 25 # Try to identify the type by checking the iscsiadm output 26 # if the iqn is used by multiple portals. If it is, it's 27 # the former, so use the supplied iqn. Otherwise, it's the 28 # latter, so try the ip,iqn combinations to find the targets 29 # which constitutes the multipath device. 30 main_iqn = connection_properties['target_iqn'] 31 all_portals = set([ip for ip, iqn in ips_iqns]) 32 match_portals = set([ip for ip, iqn in ips_iqns 33 if iqn == main_iqn]) 34 if len(all_portals) == len(match_portals): 35 ips_iqns = zip(all_portals, [main_iqn] * len(all_portals)) 36 37 for ip, iqn in ips_iqns: 38 props = copy.deepcopy(connection_properties) 39 props['target_portal'] = ip 40 props['target_iqn'] = iqn 41 self._connect_to_iscsi_portal(props) 42 43 self._rescan_iscsi() 44 host_devices = self._get_device_path(connection_properties) 45 else: 46 target_props = connection_properties 47 for props in self._iterate_all_targets(connection_properties): 48 if self._connect_to_iscsi_portal(props): 49 target_props = props 50 break 51 else: 52 LOG.warning(_LW( 53 'Failed to connect to iSCSI portal %(portal)s.'), 54 {'portal': props['target_portal']}) 55 56 host_devices = self._get_device_path(target_props) 57 58 # The /dev/disk/by-path/... node is not always present immediately 59 # TODO(justinsb): This retry-with-delay is a pattern, move to utils? 60 tries = 0 61 # Loop until at least 1 path becomes available 62 while all(map(lambda x: not os.path.exists(x), host_devices)): 63 if tries >= self.device_scan_attempts: 64 raise exception.VolumeDeviceNotFound(device=host_devices) 65 66 LOG.warning(_LW("ISCSI volume not yet found at: %(host_devices)s. " 67 "Will rescan & retry. Try number: %(tries)s."), 68 {'host_devices': host_devices, 69 'tries': tries}) 70 71 # The rescan isn't documented as being necessary(?), but it helps 72 if self.use_multipath: 73 self._rescan_iscsi() 74 else: 75 if (tries): 76 host_devices = self._get_device_path(target_props) 77 self._run_iscsiadm(target_props, ("--rescan",)) 78 79 tries = tries + 1 80 if all(map(lambda x: not os.path.exists(x), host_devices)): 81 time.sleep(tries ** 2) 82 else: 83 break 84 85 if tries != 0: 86 LOG.debug("Found iSCSI node %(host_devices)s " 87 "(after %(tries)s rescans)", 88 {'host_devices': host_devices, 'tries': tries}) 89 90 # Choose an accessible host device 91 host_device = next(dev for dev in host_devices if os.path.exists(dev)) 92 93 if self.use_multipath: 94 # We use the multipath device instead of the single path device 95 self._rescan_multipath() 96 multipath_device = self._get_multipath_device_name(host_device) 97 if multipath_device is not None: 98 host_device = multipath_device 99 LOG.debug("Unable to find multipath device name for " 100 "volume. Only using path %(device)s " 101 "for volume.", {'device': host_device}) 102 103 device_info['path'] = host_device 104 return device_info
其中重要的逻辑我都用红色标记了,用来发现host上的块设备device
2. disconnect_volume逻辑如下:
1 @synchronized('connect_volume') 2 def disconnect_volume(self, connection_properties, device_info): 3 """Detach the volume from instance_name. 4 connection_properties for iSCSI must include: 5 target_portal(s) - IP and optional port 6 target_iqn(s) - iSCSI Qualified Name 7 target_lun(s) - LUN id of the volume 8 """ 9 if self.use_multipath: 10 self._rescan_multipath() 11 host_device = multipath_device = None 12 host_devices = self._get_device_path(connection_properties) 13 # Choose an accessible host device 14 for dev in host_devices: 15 if os.path.exists(dev): 16 host_device = dev 17 multipath_device = self._get_multipath_device_name(dev) 18 if multipath_device: 19 break 20 if not host_device: 21 LOG.error(_LE("No accessible volume device: %(host_devices)s"), 22 {'host_devices': host_devices}) 23 raise exception.VolumeDeviceNotFound(device=host_devices) 24 25 if multipath_device: 26 device_realpath = os.path.realpath(host_device) 27 self._linuxscsi.remove_multipath_device(device_realpath) 28 return self._disconnect_volume_multipath_iscsi( 29 connection_properties, multipath_device) 30 31 # When multiple portals/iqns/luns are specified, we need to remove 32 # unused devices created by logging into other LUNs' session. 33 for props in self._iterate_all_targets(connection_properties): 34 self._disconnect_volume_iscsi(props)
上面的红色代码块,会把LUN对应的host path从kernel中,和multipath mapper中删除。
3. 竞态Race Condition分析
注意到,以上两个接口都是用的同一个叫(connect_volume)的锁(其实就是用flock实现的Linux上的文件锁)
为了方便描述faulty device的产生,我画了如下的图,来表示两个接口的关系
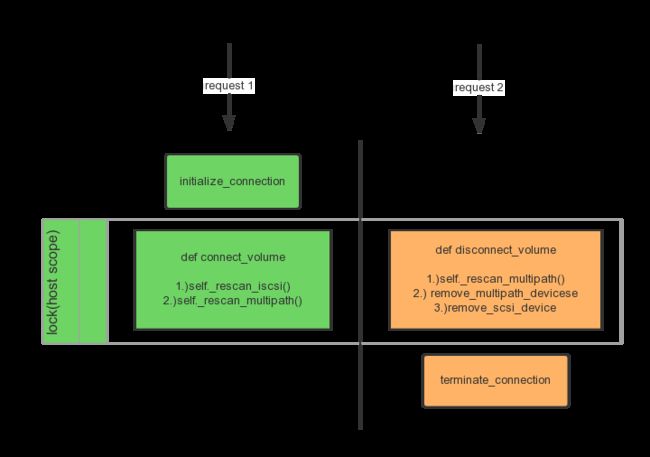
如上的流程在非并发的情况下是表现正常的,host上的device都可以正常连接和清理。
但是,以上逻辑有个实现上的问题,当高并发情况下,会产生faulty device, 考虑一下执行顺序:
- 右边的disconnect_volume执行完毕,存储上LUN对应的device path(在/dev/disk/by-path下可以看到)和multipath descriptor(multipath -l可以看到)。
- 这个时候,connect_volume锁被释放,左边的connect_volume开始执行,而右边的terminate_connection还没有执行,也就是说,存储上还没有移除host访问LUN的权限,任何host上的scsi rescan还是会发现这个LUN的device。
- 接着,connect_volume按正常执行,iscsi rescan 和multipath rescan都相继执行,造成在步骤 1)中已经删除的device有重新被scan出来。
- 然后,右边的terminate_connection在存储上执行完成,移除了host对LUN的访问,最终就形成的所谓的faulty device,看到的multipath 输出如下(两个multipath descriptor都是faulty的):
$ sudo multipath -ll 3600601601290380036a00936cf13e711 dm-30 DGC,VRAID size=2.0G features='1 retain_attached_hw_handler' hwhandler='1 alua' wp=rw |-+- policy='round-robin 0' prio=0 status=active | `- 11:0:0:151 sdef 128:112 failed faulty running `-+- policy='round-robin 0' prio=0 status=enabled `- 12:0:0:151 sdeg 128:128 failed faulty running 3600601601bd032007c097518e96ae411 dm-2 DGC,VRAID size=1.0G features='1 queue_if_no_path' hwhandler='1 alua' wp=rw |-+- policy='round-robin 0' prio=0 status=active `- #:#:#:# - #:# active faulty running
一般来说,有#:#:#:#输出的multipath是可以直接用 sudo multipath -f 3600601601bd032007c097518e96ae411 删除的。
作为第一部分,到这里faulty device的产生介绍完了,后面再找机会,介绍下在os-brick中如何尽量避免faulty device的出现。
参考资料:
RedHat官方multipath的介绍:https://access.redhat.com/documentation/en-us/red_hat_enterprise_linux/7/html/dm_multipath/mpio_description
EMC VNX driver doc:https://docs.openstack.org/cinder/queens/configuration/block-storage/drivers/dell-emc-vnx-driver.html
Go实现的块设备连接工具:https://github.com/peter-wangxu/goock
iSCSI Faulty Device Cleanup Script for VNX:https://github.com/emc-openstack/vnx-faulty-device-cleanup