python爬虫天猫商品数据及分析(3)
目的
获取商品关键词-智能手机的有关评价信息
评价信息(网络类型,机身颜色,套餐类型,存储容量,版本类型,评价内容,评价时间)
为后面的数据分析提供数据源
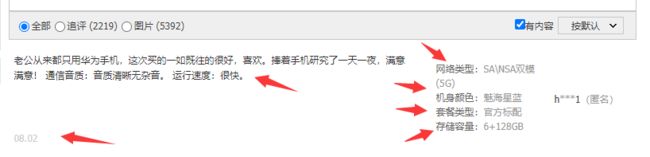
源码
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import requests
import re
from pyquery import PyQuery as pq
import time
from fake_useragent import UserAgent
# ------------------------------------------------------------------------------
# 第一步:获取请求头
# ------------------------------------------------------------------------------
# header请求头获取
def strheader():
print("一 正在获取https请求头")
headerDict, f = {}, open('../file/TXT/headers.txt', 'r') # 初始化字典,只读打开文件
headersText = f.read().replace(' ', '') # 读取文件并用替换句式去除文本空格
headers = re.split('\n', headersText) # 以换行键分割,返回列表形式数据
for header in headers: # 遍历列表
j, result = 0, re.split(':', header, maxsplit=1) # maxsplit是执行拆分的最高次数
for i in result:
j = j + 1
if j % 2 == 1:
key = i
if j % 2 == 0:
headerDict[key] = i
print("二 请求头获取完成")
f.close()
return headerDict
# ------------------------------------------------------------------------------
# 第二步:拼接关键字搜索链接
# ------------------------------------------------------------------------------
def get_search_URL(key):
url = 'https://list.tmall.com/search_product.htm?q=' + str(
key) + '&type=p&vmarket=&spm=a2156.1676643.a2227oh.d100&from=mallfp..pc_1_searchbutton'
print('三 搜素链接已生成')
with open('../file/CSV/手机_评价.csv', 'a+', encoding='utf-8') as f:
productlist = '网络类型' + ',' + '机身颜色' + ',' + '套餐类型' + ',' + '存储容量' + ',' + '版本类型' + ',' + '评价内容' + ',' + '评价时间' + '\n'
f.write(productlist)
return url
# ------------------------------------------------------------------------------
# 第三步:获取返回的商品店铺的评价链接
# ------------------------------------------------------------------------------
def get_productlist(url):
try:
print("四 正在尝试获取商品网页")
head['user-agent'] = UserAgent().chrome
response = requests.get(url, headers=head) # 请求网页
if response.status_code == 200: # 获取网页的状态码
doc = pq(response.text) # 网页解析
productshoplink = [] # 商品店铺评价链接
k = doc('.product .productImg-wrap ').items() # 从html文件中过滤符合条件的内容,返回的是列表形式
print("五 正在分析商品ID与卖家ID")
for i in k:
k = i('a').attr('href') # 获取a标签中的链接,即店铺链接
nk = re.findall('id=(.*?)&.*?&user_id=(.*?)&', k) # 获取商品ID与店铺卖家ID,用于后面拼接
URL = 'https://rate.tmall.com/list_detail_rate.htm?itemId=' + nk[0][0] + '&sellerId=' + nk[0][
1] + '¤tPage=1' # 拼接店铺商品的评价链接
productshoplink.append(URL) # 添加到商品链接的列表中
print("六 返回商品评价链表")
return productshoplink # 返回商品评价链接列表
else:
print(response.status_code)
print("请求" + url + "失败")
except Exception as e:
print(e)
# ------------------------------------------------------------------------------
# 第四步:获取商品店铺的评价链接的最大页数
# ------------------------------------------------------------------------------
def get_assesslink(url):
try:
response = requests.get(url, headers=head)
if response.status_code == 200:
# 获取评价的最大页数
page = (re.findall('lastPage":(.*?),', response.text))
return page[0]
else:
print('请求最大页数失败')
except Exception as e:
print('获取最大页数失败,请处理错误')
print(e)
# ------------------------------------------------------------------------------
# 第五步:获取商品店铺的评价页数
# ------------------------------------------------------------------------------
def get_information(list):
print("七 生成评价页数-ing")
pingjia_link = []
for url in list: # 遍历列表中所有的店铺链接
maxpage = int(get_assesslink(url)) # 获取该商品评价的最大页数
for k in range(1, maxpage): # 遍历该商品所有的评价
request_page = url[:-1] + str(k) # 拼接评价链接的页数
pingjia_link.append(request_page)
# print(pingjia_link)
parse_url(pingjia_link)
# ------------------------------------------------------------------------------
# 第六步:评价页信息获取(商品属性+评价内容+评价时间)
# ------------------------------------------------------------------------------
def parse_url(links):
for request_page in links:
print(request_page)
try:
response = requests.get(request_page, headers=head)
if response.status_code == 200:
auctionSku = (re.findall('"auctionSku":"(.*?)"', response.text)) # 商品属性(包含多个)
ratecontent = (re.findall('"rateContent":"(.*?)"', response.text)) # 评价内容
ratedate = (re.findall('"rateDate":"(.*?)"', response.text)) # 评价时间
sort(auctionSku, ratecontent, ratedate)
else:
print(response.text)
print("请求评价" + request_page + "失败")
except Exception as e:
print(e)
print('爬虫被检测,睡眠10秒后,再次执行')
time.sleep(10)
# ------------------------------------------------------------------------------
# 第七步:商品属性格式整理与本地存储
# ------------------------------------------------------------------------------
def sort(auctionSku, ratecontent, ratedate):
# print('格式整理')
for i in range(0, len(auctionSku)): # 遍历该评价页的所有条目
h1, h2, h3, h4, h5 = 'j', 'j', 'j', 'j', 'j'
m = 0
items = str(auctionSku[i]).split(";")
# print(items)
for item in list(items):
k = item.split(':')
# print(k[0], k[1])
if k[0] == '网络类型' and m == 0:
h1 = k[1]
elif k[0] == '机身颜色':
h2 = k[1]
elif k[0] == '套餐类型':
h3 = k[1]
elif k[0] == '存储容量':
h4 = k[1]
elif k[0] == '版本类型':
h5 = k[1]
m = 1
# 4G全网通,绮境森林,官方标配,8+128GB,全网通
# 中国大陆,赛博金属,官方标配,6+128GB,中国大陆
if m == 0:
h5 = '中国大陆'
else:
h1 = '全网通'
product = h1 + ',' + h2 + ',' + h3 + ',' + h4 + ',' + h5 + ','
# print(product)
# print(item)
content = str(ratecontent[i]).replace(',', '.').replace(' ', '').replace(',', '') # 获取第i个评价内容
times = ratedate[i][:-9] # 获取第i个的评价时间
with open('../file/CSV/手机_评价.csv', 'a+', encoding='utf-8') as f:
productlist = product + content + ',' + times + '\n'
f.write(productlist)
if __name__ == '__main__':
start_time = time.time()
head = strheader() # 调用类,获取https请求头
key = '智能手机' # 天猫搜索关键字
URL = get_search_URL(key) # 拼接搜索链接
shoplist = get_productlist(URL) #
get_information(shoplist) # 获取所有评价链接17秒
# TODO 用时: 1197.9221110343933,大约20分钟
print("用时:", time.time() - start_time)
评价信息本地写入
