Python借助爬虫Requests+BS4爬取人民教育出版社义务教育下学期课本(一)
经过一晚上的休息,我已经重新从阴影中站了起来,并重新发现了一个人性化的网站,一起来看看这个网站吧
来到了人民教育出版社的官网,一看,顿时晕眩三秒,我昨天的努力不都白费了吗,只得重新打起精神,研究一下这个网站了。
文章目录
- 思路梳理
- 代码实现
- 第一步
- 思路介绍
- 源代码
- 第二步
- 思路介绍
- 源代码
- 第三步
- 思路介绍
- 源代码
- 第四步
- 效果
- 最终代码
- 重要提示
- 系列文章
思路梳理
打开人民教育出版社官网一看,这清新简约的风格,一看就利于爬虫去访问
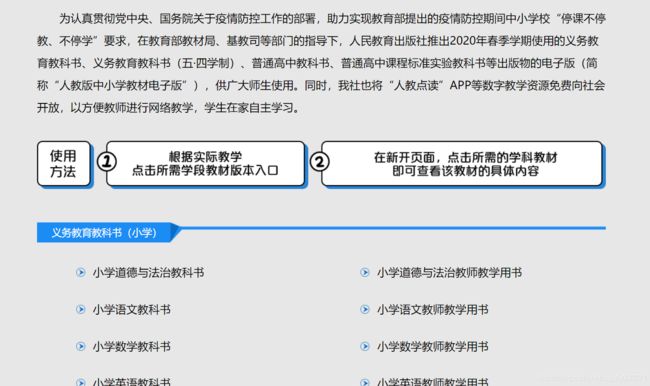
还带图书PDF下载页面,OMG,真的是太人性化了

别人有存储空间的就是不一样,下载看一下
小巧精悍呀,才只有14MB
由此可以得出,官网下载还是最佳选择
代码实现
第一步
思路介绍
既然我们已经知道如何下载了,我们就来编写一下规则
我们已这个页面为基础,编写规则

打开开发者模式,可以看见,PDF格式文件就藏在下载XHR中
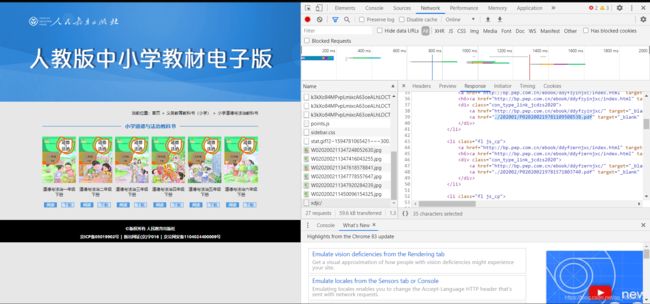
编写代码,请求这个界面,暂时不编写请求头
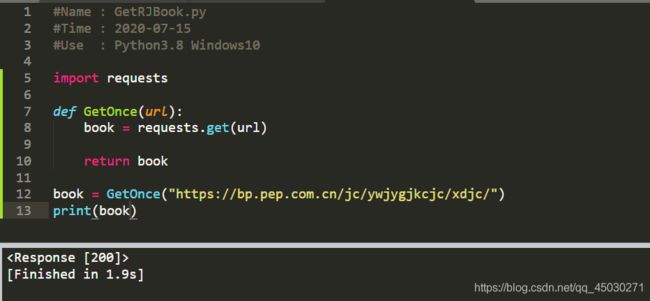
我们成功请求了这个界面,接下来打印一下内容,看一下是否真正爬取到了信息,还是一个404的禁止页面
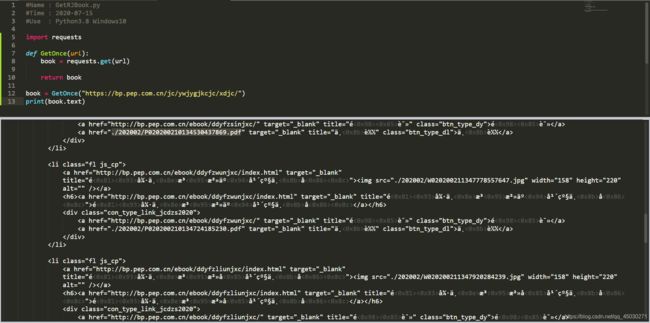
我们可以看见成功打印,但是乱码比较严重
我们用encoding模块转换一下请求数据,可以发现,乱码已经消失。关于这个问题的出现原因呢,就是应为requests的默认编码格式是gbk,这种格式读取不了中文,所以我们要把它转换成utf-8读取中文
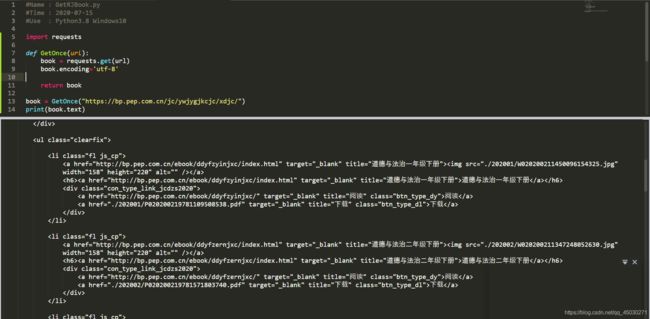
源代码
#Name : GetRJBook.py
#Time : 2020-07-15
#Use : Python3.8 Windows10
import requests
def GetOnce(url):
book = requests.get(url)
book.encoding='utf-8'
return book
book = GetOnce("https://bp.pep.com.cn/jc/ywjygjkcjc/xdjc/")
print(book.text)
第二步
思路介绍
接下来,我们就要来获取PDF的下载链接

我们经过阅读可以发现,这些文档都是存储在li中的,所以我们可以使用BS4来获取这个页面的链接

经过在li与a标签中查找,我们最终找到了这些链接
新建连个列表,存储数据

我们可以看到,它已经成功保存了
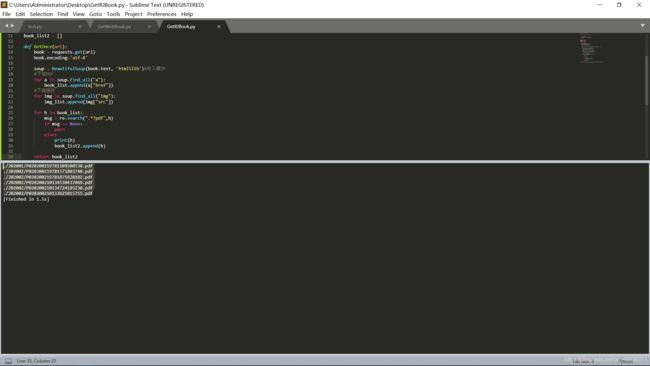
我们已经成功洗出了这些pdf文件地址
源代码
#Name : GetRJBook.py
#Time : 2020-07-15
#Use : Python3.8 Windows10
import requests
from bs4 import BeautifulSoup
import re
book_list = []
img_list = []
book_list2 = []
def GetBookPdf(url):
book = requests.get(url)
book.encoding='utf-8'
soup = BeautifulSoup(book.text, 'html5lib')#导入模块
#下载PDF
for a in soup.find_all("a"):
book_list.append(a["href"])
#下载图片
for img in soup.find_all("img"):
img_list.append(img["src"])
for h in book_list:
msg = re.search(".*?pdf",h)
if msg == None:
pass
else:
print(h)
book_list2.append(h)
return book_list2
book = GetBookPdf("https://bp.pep.com.cn/jc/ywjygjkcjc/xdjc/")
第三步
思路介绍
首先我们来获取pdf地址,就是在前面加上一行地址,这一行抵制就是最初的我们使用的地址,然后返回值
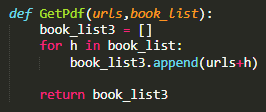
然后我们编写一个可以下载的代码,就是一次次地循环然后进行爬取和保存
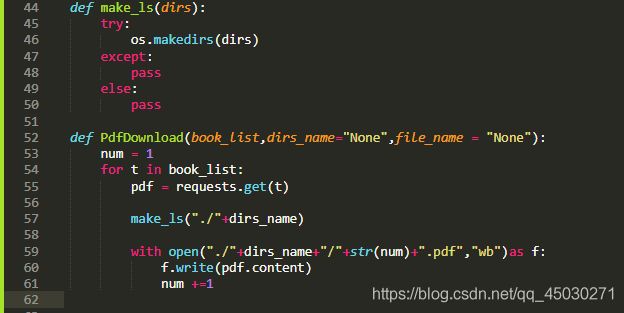
最后,终于可以爬取电子书了

源代码
#Name : GetRJBook.py
#Time : 2020-07-15
#Use : Python3.8 Windows10
import requests
from bs4 import BeautifulSoup
import re
import os
book_list = []
img_list = []
book_list2 = []
def GetBookAddress(url):
book = requests.get(url)
book.encoding='utf-8'
soup = BeautifulSoup(book.text, 'html5lib')#导入模块
#下载PDF
for a in soup.find_all("a"):
book_list.append(a["href"])
#下载图片
for img in soup.find_all("img"):
img_list.append(img["src"])
for h in book_list:
msg = re.search(".*?pdf",h)
if msg == None:
pass
else:
book_list2.append(h)
return book_list2
book = GetBookAddress("https://bp.pep.com.cn/jc/ywjygjkcjc/xdjc/")
def GetPdf(urls,book_list):
book_list3 = []
for h in book_list:
book_list3.append(urls+h)
return book_list3
def make_ls(dirs):
try:
os.makedirs(dirs)
except:
pass
else:
pass
def PdfDownload(book_list,dirs_name="None",file_name = "None"):
num = 1
for t in book_list:
pdf = requests.get(t)
make_ls("./"+dirs_name)
with open("./"+dirs_name+"/"+str(num)+".pdf","wb")as f:
f.write(pdf.content)
num +=1
a = GetPdf("https://bp.pep.com.cn/jc/ywjygjkcjc/xdjc/",book)
PdfDownload(a,"政治电子书","电子课本")
第四步
在这一步中,我们来美化一下这个代码
效果

最终代码
#Name : GetRJBook.py
#Time : 2020-07-15
#Use : Python3.8 Windows10
import requests
from bs4 import BeautifulSoup
import re
import os
book_list = []
img_list = []
book_list2 = []
def GetBookAddress(url):
book = requests.get(url)
print("Python3 Requests ---------- 我已成功访问了网站")
book.encoding='utf-8'
soup = BeautifulSoup(book.text, 'html5lib')#导入模块
#下载PDF
for a in soup.find_all("a"):
book_list.append(a["href"])
print("Python3 Requests ---------- 我已成功获取所有链接位置")
#下载图片
for img in soup.find_all("img"):
img_list.append(img["src"])
print("Python3 Requests ---------- 我已成功获取Img位置")
for h in book_list:
msg = re.search(".*?pdf",h)
if msg == None:
pass
else:
book_list2.append(h)
print("Python3 Re ---------- 我已成功清洗PDF链接")
return book_list2
book = GetBookAddress("https://bp.pep.com.cn/jc/ywjygjkcjc/xdjc/")
def GetPdf(urls,book_list):
book_list3 = []
for h in book_list:
book_list3.append(urls+h)
return book_list3
def make_ls(dirs):
try:
os.makedirs(dirs)
except:
pass
else:
print("Python3 OS ---------- 我已成功创建文件夹")
def PdfDownload(book_list,dirs_name="None",file_name = "None"):
num = 1
for t in book_list:
pdf = requests.get(t)
print("Python3 Requests ---------- 我已成功获取真实PDF位置")
make_ls("./"+dirs_name)
with open("./"+dirs_name+"/"+str(num)+".pdf","wb")as f:
f.write(pdf.content)
print("Python3 File ---------- 我已成功写入PDF")
num +=1
a = GetPdf("https://bp.pep.com.cn/jc/ywjygjkcjc/xdjc/",book)
PdfDownload(a,"政治电子书","电子课本")
print("----------程序执行结束----------")
重要提示
如需转载,请附上原文链接
系列文章
Python借助爬虫Requests+BS4爬取人民教育出版社义务教育下学期课本(二)