英汉电子词典小项目总结
最近通过所学习的c语言的知识,我们几个小伙伴们合作写了一个功能不完整的电子词典,有一些注意的地方,在这里总结下。下面是电子词典的需求分析
C语言项目——查字典
【项目需求描述】
一、单词查询
给定文本文件“dict.txt”,该文件用于存储词库。词库为“英-汉”,“汉-英”双语词典,每个单词和其解释的格式固定,如下所示:
#单词
Trans:解释1@解释2@…解释n
每个新单词由“#”开头,解释之间使用“@”隔开。一个词可能有多个解释,解释均存储在一行里,行首固定以“Trans:”开头。下面是一个典型的例子:
#abyssinian
Trans:a. 阿比西尼亚的@n. 阿比西尼亚人;依索比亚人
该词有两个解释,一个是“a.阿比西尼亚的”;另一个是“n.阿比西尼亚人;依索比亚人”。
要求编写程序将词库文件读取到内存中,接受用户输入的单词,在字典中查找单词,并且将解释输出到屏幕上。用户可以反复输入,直到用户输入“exit”字典程序退出。
程序执行格式如下所示:
./app –text
-text表示使用文本词库进行单词查找。
二、建立索引,并且使用索引进行单词查询
要求建立二进制索引,索引格式如下图所示。将文本文件“dict.txt”文件转换为上图所示索引文件“dict.dat”,使用索引文件实现单词查找。程序执行格式如下:
./app –index
-index表示使用文本词库dict.txt建立二进制索引词库dict.dat
./app –bin
-bin表示使用二进制索引词库进行单词查找。
三、支持用户自添加新词
用户添加的新词存放在指定文件中。如果待查单词在词库中找不到,则使用用户提供的词库。用户的词库使用文本形式保存,便于用户修改。程序执行格式图1-1所示。
./app 词库选择选项 -f 用户词库文件名
词库选项为-test1,或者-test2,表示使用文本词库或者二进制索引词库。-f为固定参数,用来指定用户词库文件名。
图1-1
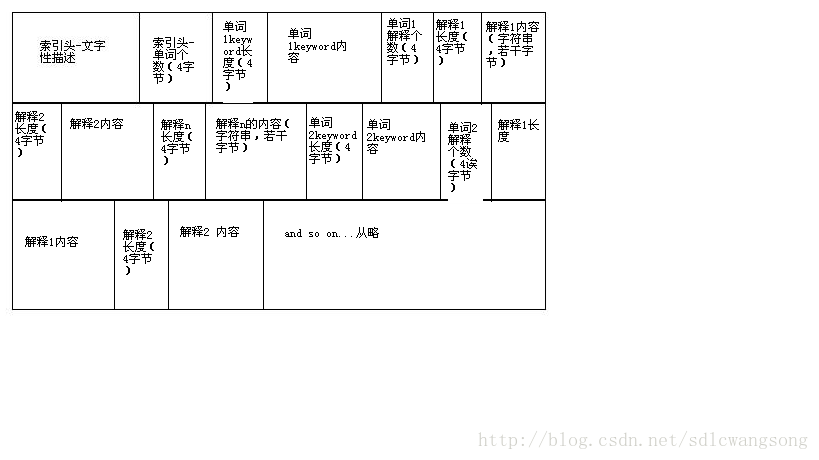
项目共有四个功能,1、用系统所给的文本词库进行查词;2、将txt格式的文本词库转化为dat二进制格式的索引词库;3、用二进制的索引词库进行查词;4、用户若在词库中找不到单词,可自行添加。
由于我负责的是第二个功能,所以我仔细的总结这个模块。
由于用文本查词需要将所有的单词都加载到内存中去,所以程序占用内存很大,造成了不必要的浪费,因此要用二进制查找的方法。思路是将文本词库写成上图所示的dat格式,这里,读懂格式是关键。
索引头—文字性描述,开始我们以为这只是整个dat文件的简单介绍,随便写写就ok了,其实不然,而且这里还是整个索引查词的关键所在。刚才在上面说了,用文本形式查词浪费空间,那么用dat索引查词就节省吗?答案是肯定的,索引,就相当于一本书的目录,即这里的电子词典的目录喽!在查词的时候只需将索引头加载到内存中去,当遍历到单词时再回到dat文件中去打印单词的内容和解释就好了嘛,这样节省了大量的内存。具体的索引这样来写:首先是一个单词的长度,然后是单词内容,接着就是单词在dat文件中的偏移量,一个单词包含这三项内容,所以将一个单词定义为一个结构体,这样索引头就ok了。
索引头单词个数—就是所有单词的总个数,这个在写单词时用一个变量i记录就好。
接下来就是所有单词的内容了,一个单词包含:单词长度,单词内容,解释个数,第一个解释长度,第一个解释内容,第二个解释长度,第二个解释内容……接下来的单词都这个写完就ok。
这样就写完了dat文件,可是里边有很多的问题,什么时候写索引头,什么时候写单词的内容和解释。方法1:首先把文本文件读一遍,写进dat一个索引头,然后再读一遍文本文件把单词和解释写进dat,这样得读两遍,好费时间。方法二:一边写索引头一边写单词和解释,同时进行,由于索引头比较好些,我们可以先把单词和解释挨个写进dat文件中,暂时把索引头写成一个链表,当写完单词和解释后再把索引头链表读入dat中去,问题解决了。可是又产生了新的问题,当要把索引头加载到内存中去的时候,文件指针怎么才可以找到索引头呢,这时可以用一个变量来记录索引头的偏移量,写完之后把它放在文件的最开头四个字节(int)OK!
还有一个问题忘记了,单词解释的个数是不确定的(最麻烦这个不确定量了),由于解释在文本中以@符分隔,这里就用strtok这个字符串分段函数,用一次strtok写一个翻译。
到这里写dat的思路就完成了,然后我用两三个小时的时间写完代码,剩下的工作就在无尽的出错调试、出错调试…………
我遇到的一些错误及问题:
1、malloc: *** error for object 0x7e84390: double free *** set a breakpoint in malloc_error_break to debug 是 NSData *responseData = [NSURLConnection sendSynchronousRequest:request returningResponse:&response error:&error];
代码如下
/*
filename:creat_dat.c
function:create dict.dat file for index
author:ws
date:2013/8/26
*/
#include
#include
#include
#include "mydictionary.h"
FILE *fp_dat;
FILE *fp_txt;
int offset;
int index_offset;
void creat_dat()
{
index_node *head,*p,*new;
char *line=NULL;
char word[60];
int len=0,length;
int last_offset=0;
int i,count=0;
new=(index_node*)malloc(sizeof(index_node)); /*open up a new index_node space */
head=p=new;
while((length=getline(&line,&len,fp_txt))!=EOF){
if(line[0]=='#'){
for(i=1;iword_length=length; /* write the length of word to index_node*/
strcpy(&word[0],line);
for(i=0;iword[i]=word[i];
}
fwrite(&length,4,1,fp_dat); /*write the length of word to dict.dat */
fwrite(line,length,1,fp_dat); /*write the word to dict.dat */
offset=offset+4+length+4; /*calcuate the offset of word,4 bytes of space word length,word space and 4 bytes of translation number space */
length=getline(&line,&len,fp_txt); /*read dict.txt again,the content of this line is translation*/
strtok_trans(line,length); /* break written translation to index_node */
p->word_offset=last_offset; /*write the offset of word to index_node*/
last_offset=offset; /*record the first offset of wrod*/
count++; /*record the number of all word*/
p->next=new;
p=p->next;
new=(index_node*)malloc(sizeof(index_node)); /*open up next index_node*/
}
fwrite(&count,4,1,fp_dat);
index_offset=offset+4; /* index_offset was used to record the offset of index*/
p=head;
while(p!=NULL){
fwrite(&p->word_length,4,1,fp_dat);
fwrite(p->word,strlen(p->word),1,fp_dat);
fwrite(&p->word_offset,4,1,fp_dat);
p=p->next;
} /*write the content of index_node to dict.dat*/
}
原来是我把57行的malloc代码写在了21行,while之前已经malloc过了,在这里当然会错误喽。
2、***stack smashing detected***
出现堆栈溢出错误,在网上查了很多资料,很多都是说由于linux自带的堆栈保护器的原因,因为的系统默认使用了GCC的“-fstack-protector"参数导致的,我们只需要在编译的时候exportCFLAGS="-fno-stack-protector"就好。我使用这个方法改了之后,错误依然存在。最后我用笨法子,gdb一步一步的调试,在一千多个单词的时候错误出现了,原来是一个50个字符长度的单词在作怪,而我只自以为的定义了单词的长度为50。(在后边我还遇到了乱码的问题,那次是解释的个数定义的不对)
3、写完看着都没有错误了,就交给别人创建哈希表查单词了,可是不成功,只能查一部分,后来我又对我写的程序进行调试、修改,终于发现了,我把单词和解释都定义为了char*类型,所以要在每次使用它们的时候都用memset函数初始化为0,以防止出现乱码的情况。(在今后定义了一些数组等等用作字符串时都要在使用前进行清0处理以防乱码)
4、还有很多很多的小错误……
注意几点:1、汉字编码,一般的utf8编码汉字所占字节数为(2—6)个,这里环境下的汉字占了3个字节;
2、strlen与sizeof的区别,sizeof是算符,strlen是函数。sizeof可以用类型做参数,strlen只能用char*做参数,且必须是以''\0''结尾的。eg:char str[20]="0123456789";
int a=strlen(str); //a=10;
int b=sizeof(str); //而b=20;
3、fseek的使用,在写偏移量的时候用到过很多次,尤其是回去写偏移量时,一定要就算好fseek的长度问题。
总结:开始拿到项目的需求分析时,感到太难了,本来就什么项目都没有做过,有种无从下手的感觉,现在想想,无非就是文件的读写,然后再注意些细节的问题,仔细点,就没什么太大的问题。
做项目时,用策略与机制的原则首先将项目分解为几个大的块,每个块再细分,分为不同功能的小函数,再逐个完成,做到分层的概念。策略与机制。
小记:先写这么些吧,事后很多都忘了,今后要做笔记。