pytorch用法
1.nn.Module
torch.nn是专门为神经网络设计的模块化接口。nn构建于autograd之上,可以用来定义和运行神经网络。
在实际使用中,最常见的做法是继承nn.Module,撰写自己的网络/层。
定义自已的网络:
torch.nn.Module类是PyTorch中用于表示多层网络的。构建自己的网络就是定义torch.nn.Module的一个子类,这时需要重写初始化函数__init__()和前向过程forward()。__init__()函数中需要调用父类的初始化函数;forward()函数用于构建网络从输入到输出的过程。
只要在nn.Module的子类中定义了forward函数,backward函数就会被自动实现(利用Autograd)。
在forward函数中可以使用任何Variable支持的函数,毕竟在整个pytorch构建的图中,是Variable在流动。还可以使用
if,for,print,log等python语法.
注:Pytorch基于nn.Module构建的模型中,只支持mini-batch的Variable输入方式,
比如,只有一张输入图片,也需要变成 N x C x H x W 的形式:
input_image = torch.FloatTensor(1, 28, 28)
input_image = Variable(input_image)
input_image = input_image.unsqueeze(0) # 1 x 1 x 28 x 28
import torch.nn as nn
import torch.nn.functional as F
class MyNet(nn.Module):
def __init__(self):
super(MyNet, self).__init__() #调用父类的初始化函数
self.f1 = nn.Linear(100, 200)
self.f2 = nn.Linear(200, 10)
def forward(self, x):
x = self.f1(x)
x = F.relu(x)
x = self.f2(x)
x = F.softmax(x)
return x
网络中的每一层既可以以类的形式在初始函数中定义,也可以以函数的形式在forward()函数中定义。
nn.Module作为基类,其结构如下所示:
def __init__(self):
self._parameters = OrderedDict() #用来保存用户设置的参数字典,key:params Value:
#用户自定义的关键字和值。系统定义的不存与此。
self._modules=OrderedDict() #存放子module,使用submodule生成的module会存于此。
self._buffers=OrderedDict() #存放一些缓存结果。
self._backward=OrderedDict()
self._forward=OrderedDict()
self.training=True #dropout在训练和测试中采取的模式
#不同,通过training决定前向传播策略。
2.nn.Linear的用法
Linear继承于nn.Module,内部函数主要有__init__,reset_parameters, forward和extra_repr函数
1.init(self, in_features, out_features, bias=True)
in_features:前一层网络神经元的个数
out_features: 该网络层神经元的个数
以上两者决定了weight的形状[out_features , in_features]
bias: 网络层是否有偏置,默认存在,且维度为[out_features ],若bias=False,则该网络层无偏置。
2.reset_parameters(self)
参数初始化函数
在__init__中调用此函数,权重采用Xvaier initialization 初始化方式初始参数。
3.forward(self, input)
在Module的__call__函数调用此函数,使得类对象具有函数调用的功能,同过此功能实现pytorch的网络结构堆叠。
class torch.nn.Linear(in_features,out_features,bias = True )[来源]
对传入数据应用线性变换:y = A x+ b
参数:
in_features - 每个输入样本的大小
out_features - 每个输出样本的大小
bias - 如果设置为False,则图层不会学习附加偏差。默认值:True
代码理解:
import torch
x = torch.randn(128, 20) # 从标准正态分布(均值为0,方差为1)中抽取的一组随机数
#输入的维度是(128,20)
m = torch.nn.Linear(20, 30) # 输入维度是20,输出维度是30
output = m(x)
print('m.weight.shape:\n ', m.weight.shape)
print('m.bias.shape:\n', m.bias.shape)
print('output.shape:\n', output.shape)
output:
m.weight.shape:
torch.Size([30, 20])
m.bias.shape:
torch.Size([30])
output.shape:
torch.Size([128, 30])
说明:
m是类对象,而直接像函数一样调用m,m(x)。
重点:
1.nn.Module 是所有神经网络单元(neural network modules)的基类
2.pytorch在nn.Module中,实现了__call__方法,而在__call__方法中调用了forward函数。
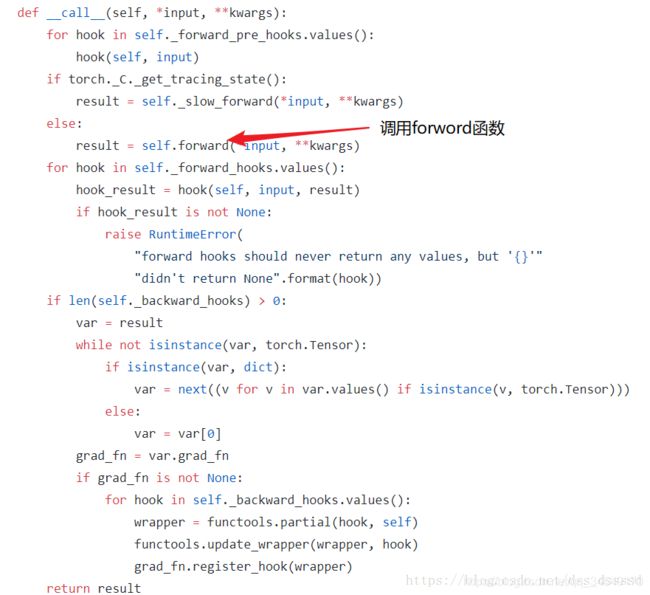
nn.Linear实现的forward函数:

返回的是:
input∗weight+bias
首先创建类对象m,然后通过m(input)实际上调用__call__(input),然后__call__(input)调用
forward()函数,最后返回计算结果为:
[128,20]×[20,30]=[128,30]
所以自己创建多层神经网络模块时,只需要再实现__init__和forward即可.
# define three layers
class simpleNet(nn.Module):
def __init__(self, in_dim, n_hidden_1, n_hidden_2, out_dim):
super().__init__()
self.layer1 = nn.Linear(in_dim, n_hidden_1)
self.layer2 = nn.Linear(n_hidden_1, n_hidden_2)
self.layer3 = nn.Linear(n_hidden_2, out_dim)
def forward(self, x):
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
return x
以下为各层神经元个数:
输入: in_dim
第一层: n_hidden_1
第二层:n_hidden_2
第三层(输出层):out_dim
3.squeeze和unsqueeze的用法
squeeze用来缩减维度
unsqueeze()函数用来增加维度
1.初始化a
a = t.arange(0,6)
a.view(2,3)
output:
tensor([[0,1,2],
[3,4,5]])
2.在第二维增加一个维度,使其维度变为(2,1,3)
a.unsqueeze(1)
output:
tensor([[[0,1,2],
[3,4,5]]])
4.DataLoader 和 Dataset的用法
Pytorch中数据集被抽象为一个抽象类torch.utils.data.Dataset,所有的数据集都应该继承这个类,并override以下两项:
__len__:代表样本数量。len(obj)等价于obj.__len__()。
__getitem__:返回一条数据或一个样本。obj[index]等价于obj.__getitem__。建议将节奏的图片等高负
-
dataloader本质是一个可迭代对象,使用iter()访问,不能使用next()访问;
-
使用iter(dataloader)返回的是一个迭代器,然后可以使用next访问;
-
也可以使用
for inputs, labels in dataloaders进行可迭代对象的访问; -
一般我们实现一个datasets对象,传入到dataloader中;然后内部使用yeild返回每一次batch的数据;
① DataLoader本质上就是一个iterable(跟python的内置类型list等一样),并利用多进程来加速batch data的处理,使用yield来使用有限的内存
② Queue的特点
当队列里面没有数据时: queue.get() 会阻塞, 阻塞的时候,其它进程/线程如果有queue.put() 操作,本线程/进程会被通知,然后就可以 get 成功。
当数据满了: queue.put() 会阻塞
③ DataLoader是一个高效,简洁,直观的网络输入数据结构,便于使用和扩展
输入数据PipeLine
pytorch 的数据加载到模型的操作顺序是这样的:
① 创建一个 Dataset 对象
② 创建一个 DataLoader 对象
③ 循环这个 DataLoader 对象,将img, label加载到模型中进行训练
dataset = MyDataset()
dataloader = DataLoader(dataset)
num_epoches = 100
for epoch in range(num_epoches):
for img, label in dataloader:
…
所以,作为直接对数据进入模型中的关键一步, DataLoader非常重要。
首先简单介绍一下DataLoader,它是PyTorch中数据读取的一个重要接口,该接口定义在dataloader.py中,只要是用PyTorch来训练模型基本都会用到该接口(除非用户重写…),该接口的目的:将自定义的Dataset根据batch size大小、是否shuffle等封装成一个Batch Size大小的Tensor,用于后面的训练。
官方对DataLoader的说明是:“数据加载由数据集和采样器组成,基于python的单、多进程的iterators来处理数据。”关于iterator和iterable的区别和概念请自行查阅,在实现中的差别就是iterators有__iter__和__next__方法,而iterable只有__iter__方法。
1.DataLoader
先介绍一下DataLoader(object)的参数:
dataset(Dataset): 传入的数据集
batch_size(int, optional): 每个batch有多少个样本
shuffle(bool, optional): 在每个epoch开始的时候,对数据进行重新排序
sampler(Sampler, optional): 自定义从数据集中取样本的策略,如果指定这个参数,那么shuffle必须为False
batch_sampler(Sampler, optional): 与sampler类似,但是一次只返回一个batch的indices(索引),需要注意的是,一旦指定了这个参数,那么batch_size,shuffle,sampler,drop_last就不能再制定了(互斥——Mutually exclusive)
num_workers (int, optional): 这个参数决定了有几个进程来处理data loading。0意味着所有的数据都会被load进主进程。(默认为0)
collate_fn (callable, optional): 将一个list的sample组成一个mini-batch的函数
pin_memory (bool, optional): 如果设置为True,那么data loader将会在返回它们之前,将tensors拷贝到CUDA中的固定内存(CUDA pinned memory)中.
drop_last (bool, optional): 如果设置为True:这个是对最后的未完成的batch来说的,比如你的batch_size设置为64,而一个epoch只有100个样本,那么训练的时候后面的36个就被扔掉了…
如果为False(默认),那么会继续正常执行,只是最后的batch_size会小一点。
timeout(numeric, optional): 如果是正数,表明等待从worker进程中收集一个batch等待的时间,若超出设定的时间还没有收集到,那就不收集这个内容了。这个numeric应总是大于等于0。默认为0
worker_init_fn (callable, optional): 每个worker初始化函数 If not None, this will be called on each
worker subprocess with the worker id (an int in [0, num_workers - 1]) as
input, after seeding and before data loading. (default: None)
5.nn.Sequential的用法
torch.nn.Sequential是一个Sequential容器,模块将按照构造函数中传递的顺序添加到模块中。另外,也可以传入一个有序模块。 为了更容易理解,官方给出了一些案例:
# Sequential使用实例
model = nn.Sequential(
nn.Conv2d(1,20,5),
nn.ReLU(),
nn.Conv2d(20,64,5),
nn.ReLU()
)
# Sequential with OrderedDict使用实例
model = nn.Sequential(OrderedDict([
('conv1', nn.Conv2d(1,20,5)),
('relu1', nn.ReLU()),
('conv2', nn.Conv2d(20,64,5)),
('relu2', nn.ReLU())
]))
Sequential源码:
初始化函数的实现:
def __init__(self, *args):
super(Sequential, self).__init__()
if len(args) == 1 and isinstance(args[0], OrderedDict):
for key, module in args[0].items():
self.add_module(key, module)
else:
for idx, module in enumerate(args):
self.add_module(str(idx), module)
初始化函数__init__,在初始化函数中,首先是if条件判断,如果传入的参数为1个,并且类型
为OrderedDict,通过字典索引的方式将子模块添加到self._module中,否则,通过for循环
遍历参数,将所有的子模块添加到self._module中。注意,Sequential模块的初始换函数
没有异常处理,所以在写的时候要注意,注意,注意了
forward函数的实现:
因为每一个module都继承于nn.Module,都会实现__call__与forward函数,具体讲解点击这里,所以forward函数中通过for循环依次调用添加到self._module中的子模块,最后输出经过所有神经网络层的结果
def forward(self, input):
for module in self._modules.values():
input = module(input)
return input
torch.nn.Sequential快速搭建神经网络
为了方便比较,我们先用普通方法搭建一个神经网络。
class Net(torch.nn.Module):
def __init__(self, n_feature, n_hidden, n_output):
super(Net, self).__init__()
self.hidden = torch.nn.Linear(n_feature, n_hidden)
self.predict = torch.nn.Linear(n_hidden, n_output)
def forward(self, x):
x = F.relu(self.hidden(x))
x = self.predict(x)
return x
net1 = Net(1, 10, 1)
上面class继承了一个torch中的神经网络结构, 然后对其进行了修改;
接下来我们来使用torch.nn.Sequential来快速搭建一个神经网络。
net2 = torch.nn.Sequential(
torch.nn.Linear(1, 10),
torch.nn.ReLU(),
torch.nn.Linear(10, 1)
)
我们来打印一下2个神经网络的数据,查看区别:
print(net1)
"""
output:
Net (
(hidden): Linear (1 -> 10)
(predict): Linear (10 -> 1)
)
"""
print(net2)
"""
output:
Sequential (
(0): Linear (1 -> 10)
(1): ReLU ()
(2): Linear (10 -> 1)
)
"""
我们可以发现,使用torch.nn.Sequential会自动加入激励函数, 但是 net1 中, 激励函数实际上是在 forward() 功能中才被调用的.
torch.nn.Sequential与torch.nn.Module区别与选择:
使用torch.nn.Module,我们可以根据自己的需求改变传播过程,如RNN等
如果你需要快速构建或者不需要过多的过程,直接使用torch.nn.Sequential即可。
6.torchvision.transforms
pytorch团队提供了一个torchvision.transforms包,我们可以用transforms进行以下操作:
- PIL.Image/numpy.ndarray与Tensor的相互转化;
transforms.ToTensor()
#把像素值范围为[0, 255]的PIL.Image或者numpy.ndarray型数据,shape=(H x W x C)转换
成的像素值范围为[0.0, 1.0]的torch.FloatTensor,shape为(N x C x H x W) 待确认。
- 归一化
transforms.Normalize(mean, std)
此转换类作用于torch.*Tensor。给定均值(R, G, B)和标准差(R, G, B),用公式channel = (channel - mean) / std进行规范化。(是对tensor进行归一化,所以需要放在transforms.ToTensor()之后)
- 对PIL.Image进行裁剪、缩放等操作。
transforms.Scale(256),
transforms.RandomSizedCrop(224),
transforms.RandomHorizontalFlip()
- transforms.Compose(transforms)将多个transform组合起来使用。其中,transforms: 由transform构成的列表.
normalize = transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
all_transforms = transforms.Compose([
transforms.Scale(256),
transforms.RandomSizedCrop(224),
transforms.RandomHorizontalFlip(), # 对PIL.Image图片进行操作
transforms.ToTensor(),
normalize])
#其中,transforms.Compose中的操作是按照顺序执行的。
7.Conv2d()的用法
torch 包 nn 中 Conv2d 的用法与 tensorflow 中类似,但不完全一样。
在 torch 中,Conv2d 有几个基本的参数,分别是
in_channels 输入图像的深度
out_channels 输出图像的深度
kernel_size 卷积核大小,正方形卷积只为单个数字
stride 卷积步长,默认为1
padding 卷积是否造成尺寸丢失,1为不丢失
与tensorflow不一样的是,pytorch中的使用更加清晰化,我们可以使用这种方法定义输入与输出图像的深度并同时指定使用的卷积核的大小。
而我们的输入则由经由 Conv2d 定义的参数传入,如下所示:
# 定义一个输入深度为1,输出为深度6,卷积核大小为 3*3 的 conv1 变量
self.conv1 = nn.Conv2d(1, 6, 3)
# 传入原始输入x,以获得长宽与x相当,深度为6的卷积部分
x = self.conv1(x)
注意:Conv2d中所需要的输入顺序为batchsize, nChannels, Height, Width
8.TensorDataset的用法
通过索引进行索引,返回第一维的索引的值
import torch
import torch.utils.data as Data
torch.manual_seed(1) # reproducible
BATCH_SIZE = 5
x = torch.linspace(1, 10, 10) # this is x data (torch tensor)
y = torch.linspace(10, 1, 10) # this is y data (torch tensor)
'''先转换成 torch 能识别的 Dataset'''
torch_dataset = Data.TensorDataset(x, y)
print(torch_dataset[0]) #输出(tensor(1.), tensor(10.))
print(torch_dataset[1]) #输出(tensor(2.), tensor(9.))
print(torch_dataset.tensors)
#输出:
(tensor([ 1., 2., 3., 4., 5., 6., 7., 8., 9., 10.]),
tensor([ 10., 9., 8., 7., 6., 5., 4., 3., 2., 1.]))
print(torch_dataset[0])
#输出:
(tensor(1.), tensor(10.))
print(torch_dataset[1])
#输出:
(tensor(2.), tensor(9.))
9.自定义参数初始化方式
PyTorch提供了多种参数初始化函数:
torch.nn.init.constant(tensor, val)
torch.nn.init.normal(tensor, mean=0, std=1)
torch.nn.init.xavier_uniform(tensor, gain=1)
等等。
注意上面的初始化函数的参数tensor,虽然写的是tensor,但是也可以是Variable类型的。而神经网络的参数类型Parameter是Variable类的子类,所以初始化函数可以直接作用于神经网络参数。
对网络的某一层参数进行初始化:
self.conv1 = nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3)
init.xavier_uniform(self.conv1.weight)
init.constant(self.conv1.bias, 0.1)
对整个网络的参数进行初始化:
def weights_init(m):
classname=m.__class__.__name__
if classname.find('Conv') != -1:
xavier(m.weight.data)
xavier(m.bias.data)
net = Net()
net.apply(weights_init) #apply函数会递归地搜索网络内的所有module并把参数表示的函数应用到所有的module上。
不建议访问以下划线为前缀的成员,他们是内部的,如果有改变不会通知用户。更推荐的一种方法是检查某个module是否是某种类型:
def weights_init(m):
if isinstance(m, nn.Conv2d):
xavier(m.weight.data)
xavier(m.bias.data)
10.self.modules() 和 self.children()的区别
参考:https://blog.csdn.net/dss_dssssd/article/details/83958518
11.apply()函数的用法
在pytorch中对卷积层和批归一层权重进行初始化,也就是weight和bias。
主要会用到torch的apply()函数。
apply(fn):将fn函数递归地应用到网络模型的每个子模型中,主要用在参数的初始化。
使用apply()时,需要先定义一个参数初始化的函数。
def weight_init(m):
classname = m.__class__.__name__ # 得到网络层的名字,如ConvTranspose2d
if classname.find('Conv') != -1: # 使用了find函数,如果不存在返回值为-1,所以让其不等于-1
m.weight.data.normal_(0.0, 0.02)
elif classname.find('BatchNorm') != -1:
m.weight.data.normal_(1.0, 0.02)
m.bias.data.fill_(0)
之后,定义自己的网络,得到网络模型,使用apply()函数,就可以分别对conv层和bn层进行参数初始化。
model = net()
model.apply(weight_init)
以上就可以对各层进行参数初始化。
如何查看效果呢?也就是如何查看各层的weight和bias。
需要用到state_dict()函数,返回网络的所有参数。具体如下:
params = model.state_dict()
for k, v in params.items():
print k # 打印网络中的变量名,找出自己想查看的参数名字,这个与自己定义网络时起的名字有关。
print params['net.convt1.weight'] # 打印convt1的weight
print params['net.convt1.bias'] # 打印convt1的bias
12.state_dict()的用法
state_dict(): 返回一个包含模型所有状态的字典
load_state_dict(): 加载预训练模型的参数
13.train/eval的用法
eval即evaluation模式,train即训练模式。仅仅当模型中有Dropout和BatchNorm时才会有影响。因为训练时dropout和BN都开启,而一般而言测试时dropout被关闭,BN中的参数也是利用训练时保留的参数,所以测试时应进入评估模式。
14.optimizer.zero_grad()的用法
optimizer.zero_grad()意思是把梯度置零,也就是把loss关于weight的导数变成0.
有两种方式直接把模型的参数梯度设成0:
model.zero_grad()
optimizer.zero_grad()
#当optimizer=optim.Optimizer(model.parameters())时,两者等效
如果想要把某一Variable的梯度置为0,只需用以下语句:
Variable.grad.data.zero_()
为什么每一轮batch需要设置optimizer.zero_grad:
根据pytorch中的backward()函数的计算,当网络参量进行反馈时,梯度是被积累的而不是被替换掉;但是在每一个batch时毫无疑问并不需要将两个batch的梯度混合起来累积,因此这里就需要每个batch设置一遍zero_grad 了。
15.损失函数和优化器的用法
1.损失函数:
损失函数也是nn.Module的子类,这些LOSS都定义在torch.nn.functional下,可以直接使用。
Pytorch 提供的交叉熵相关的函数有:
Mean Squared Error
MSE即均方误差,常用在数值型输出上。计算 output 和 target 之差的均方差。
torch.nn.CrossEntropyLoss
针对单目标分类问题, 结合了 nn.LogSoftmax() 和 nn.NLLLoss() 来计算 loss.
交叉熵损失既可以用于二分类,也适用于多分类,并且往往和Softmax激活函数搭配使用。
torch.nn.KLDivLoss
相对熵, 也叫 KL 散度, Kullback-Leibler divergence Loss.
计算 input 和 target 之间的 KL 散度。KL 散度可用于衡量不同的连续分布之间的距离, 在连续的输出分布的空间上(离散采样)上进行直接回归时 很有效.
torch.nn.BCELoss
计算 target 和 output 间的二值交叉熵(Binary Cross Entropy)
torch.nn.BCEWithLogitsLoss
该 loss 层包括了 Sigmoid 层和 BCELoss 层. 单类别任务.
数值计算稳定性更好( log-sum-exp trick), 相比与 Sigmoid + BCELoss.
torch.nn.MultiLabelSoftMarginLoss
基于 max-entropy 计算输入 input x 和 target x 间的 multi-label one-versus-all loss.
2.优化器:
所有的优化方法都封装在torch.optim里面,他的设计很灵活,可以扩展为自定义的优化方法。
所有的优化方法都是继承了基类optim.Optimizer。并实现了自己的优化步骤。
16.pytorch可视化的用法
参考:https://www.jianshu.com/p/46eb3004beca
因此,在python中,结合 pytorch 使用 tensorboard 分为两步:
第一步 写文件。 python 包是 tensorboardX,用 pip install tensorboardX 来安装。
import torch
from tensorboardX import SummaryWriter
# 设计一个小网络
class Net(torch.nn.Module):
def __init__(self):
super(Net,self).__init__()
self.dense = torch.nn.Linear(in_features=10,out_features=1)
def forward(self,x):
return self.dense(x)
# 根据小网络实例化一个模型 net
net = Net()
# 创建文件写控制器,将之后的数值以protocol buffer格式写入到logs文件夹中,空的logs文件夹将被自动创建。
writer = SummaryWriter(log_dir='logs')
# 将网络net的结构写到logs里:
data = torch.rand(2,10)
writer.add_graph(net,input_to_model=(data,))
# 注意:pytorch模型不会记录其输入输出的大小,更不会记录每层输出的尺寸。
# 所以,tensorbaord需要一个假的数据 `data` 来探测网络各层输出大小,并指示输入尺寸。
# 写一个新的数值序列到logs内的文件里,比如sin正弦波。
for i in range(100):
x = torch.tensor(i/10,dtype=torch.float)
y = torch.sin(x)
# 写入数据的标注指定为 data/sin, 写入数据是y, 当前已迭代的步数是i。
writer.add_scalar('data/sin',y,i)
writer.close()
第二步 在命令行里使用tensorboard读取protocol buffer 格式的数值:
tensorboard --logdir logs --port 80
这样就从logs里读取数值,并在本机80端口开启了一个web服务器
根据命令行的最后提示,访问网址