小全读论文《Momentum Contrast for Unsupervised Visual Representation Learning》(MoCo)
小全读论文《Momentum Contrast for Unsupervised Visual Representation Learning》
- 1.浅谈无监督问题
- 1.1 什么是无监督问题?
- 1.2 图片无监督问题有什么意义?
- 1.3 图片无监督问题的难点是什么呢?
- 2.MoCo(本文方法)
- 2.1 前备知识
- 2.2 本文Motivation
- 2.3 方法Momentum Contrast
- 2.3.1 Dictionary as a queue
- 2.3.2 Momentum update
- 2.3.3 算法的伪代码
- 3.实验
- 3.1 无监督设置下的分类任务
- 3.2 下游任务的结果
- 3.2.1 检测和分割
- 3.2.2 pose和densepose等
- 4.总结
这是何恺明大大的新作,当然论文上满满都是赫赫有名的大佬们,Ross Girshick、Saining Xie等。这篇文章是做图片无监督问题的,自己虽然不是做无监督问题的,冲着一众大佬的光环,忍不住仔细钻研了一把,嘻嘻嘻(*_*),恺明小迷弟石锤了。 全文均根据自己理解整理的,如有纰漏欢迎指出。
1.浅谈无监督问题
1.1 什么是无监督问题?
有监督问题就是利用监督信息(也就是标注信息)去设计和训练模型,无监督问题就是不需要依赖于监督信息也能去设计和训练相应的模型,达成某些目的,如本文关注的图片无监督问题,就是在只给了你海量的图片的前提下而没有任何图片标签信息,依然能训练得到一个很好的特征提取器。他的目的是这个特征提取器能放之四海而皆准,就是你以后来了一个新任务,不需要设计新的feature了,直接用我的这个特征提取器就ok了,连finetune都不需要了。
1.2 图片无监督问题有什么意义?
我们可以参考一个无监督问题的应用,如nlp里面的word2vector算法,如GloVe和Bert,像cv很多领域都直接利用了这些算法,作为直接的external knowledge来使用。因此,图片无监督问题其实也希望能达到像Bert这种效果,我能有一个通用的图片特征模型,这个模型可以用于任何的图片提取feature,特别是,对于某些领域,如医疗,数据特别少,仅仅基于这些稀少的数据是很难提取到很好的feature的,但是通过这种通用的图片特征模型就能提取到较好的特征。
1.3 图片无监督问题的难点是什么呢?
为什么NLP领域能出现像Bert这样子的无监督模型,但是为什么目前CV领域却没有出现像Bert这样的模型?文章也指出了这个问题的难点,这里我也适当加入了自己的理解:
- NLP是以单词为输入的,而CV是以图片为输入(这个“输入”的意思是作为模型的输入)。单词是相对离散化的输入,他的输入可以采取one-hot的形式,可变的程度不高。而图片的输入维度太高,而且相对来说连续化一些,可变的程度高得多,如一个20x20的输入图片,就可以有无数种的可能,而一个单词最后也就n种变化(n是总词库的大小,在不同的位置取1而形成不同的one-hot)
- NLP的信息更加偏向于结构化,而CV不具备这种结构化信息。这种结构化信息可以举例来看,如NLP中很多模型是以句子为单位去设计模型的,一个句子往往是根据语法结构以及单词的词性构建的,主谓宾,宾语从句,状语从句和动词,名词等,而语法结构往往是有限的。而CV中的图片是很难有一致的结构化信息,如图片的变换太多,图片中物体的相互组合、物体的相互遮挡、物体的环境因素等,模型需要控制和适应的点会很多。
2.MoCo(本文方法)
在理解本文之前,首先先简要介绍一下图片无监督的方法,好理解论文老是提到的几个词(dictionary,key)的含义,我一开始看文章的时候,刚看到这几个词,真是云里雾里,绕有一种众人皆醒我独醉的感觉。
2.1 前备知识
我们都知道,有监督问题就是基于预测结果和监督信息设计一个损失函数loss function,但是无监督问题应该怎么设计loss function呢?图片无监督问题的一个经典的方法是contrastive learning里的instance discrimination method(因为论文提到了,我就称之为经典方法吧啊哈哈哈哈哈),他的设计原理是:
从一张图片中进行采样(crop),如果当前采样图片与另外一张图片来源于同一张图片,那么该图片就被为当前图片的一个正样本,否则则认为是负样本
所以当前采样图片我们称之为query,同时我们会将一系列的图片保存起来,形成一个图片集,并集合成一个dictionary,这些图片的特征作为这个dictionary的key(文章也没说dictionary的value是什么,我理解为是每个key对应的图片id吧,这其实不碍于理解整篇文章)
基于上述的设计原理,可以设计一个loss函数(InfoNCE):
L q = − l o g e x p ( q ⋅ k + / τ ) ∑ i = 0 K e x p ( q ⋅ k i / τ ) L_q=-log \frac{exp(q \cdot k_+/\tau)}{\sum^K_{i=0}exp(q \cdot k_i/\tau)} Lq=−log∑i=0Kexp(q⋅ki/τ)exp(q⋅k+/τ)
乍一看,这个式子还蛮熟悉的,和softmax有点像。其中 q q q表示query的特征, k i k_i ki表示dictionary中key的特征, k + k_+ k+表示 q q q在dictionary中的一个正样本(假设有且只有一个), τ \tau τ是一个超参数,用于调整上述loss的。细看的话,其实这和交叉熵本质就是一样的,区别在于,通过query与各个key点乘运算,获得他们的相似性(与正常的分类模型的FC raw output对应),但是点乘后的结果的量级不适合softmax运算,通过一个 τ \tau τ系数控制。所以这个loss的本质就是希望网络对于相同图片采样出来的输入,得到的feature要尽可能的相似。
2.2 本文Motivation
本文希望能构建一个large和consistent的dictionary:
large:希望dictionary的容量够大,才能更好地采样到这么高维的视觉信息
consistent:希望key的特征是通过相似或者相同的encoder得到的,使得在与query进行特征比较的时候,保持特征的一致性
(文章似乎没有对“为什么要引入一致性”这一点做比较多的分析和说明,即“引入了一致性,好处是什么?而如果缺少了这种一致性,会带来怎样的问题”,如果有的话,欢迎指出来呀~)
2.3 方法Momentum Contrast
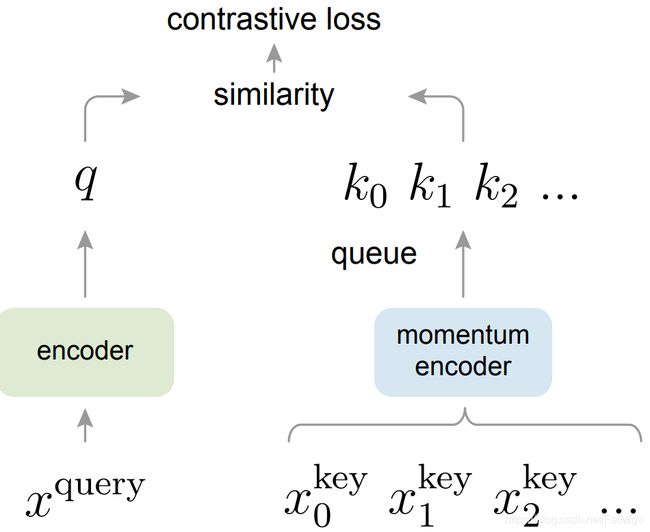
本文主要提出了两个重要的改进点:
2.3.1 Dictionary as a queue
用队列queue的形式更新dictionary:当前mini-batch的数据将会进入队列,旧的数据会被提出队列。这样的好处在于:将dictionary的大小和batch size解耦出来,即dictionary的大小不需要受batchsize的约束,可以设置成任意大小。
2.3.2 Momentum update
采取基于动量的移动平均(momentum-based moving average)方式去更新key的encoder:因为dictionary的key来自于不同的mini-batch,通过这种方式缓慢更新(slowly progressing)key的encoder,使得key的特征保持一致性。好处在于:避免了因为encoder的剧烈变化导致特征丢失一致性,同时也保持encoder一直处于被更新的状态。
具体地,
记 q = f q ( x q ) , k = f k ( x k ) q = f_q(x^q),k=f_k(x^k) q=fq(xq),k=fk(xk), f q f_q fq和 f k f_k fk分别表示query和key的encoder,其参数记为 θ q \theta_q θq和 θ k \theta_k θk。更新的方式是:
θ k ← m θ k + ( 1 − m ) θ q \theta_k\gets m\theta_k + (1-m)\theta_q θk←mθk+(1−m)θq
实验发现,适当增加m会带来更好地效果,因此本文 m = 0.999 m=0.999 m=0.999,也印证了缓慢更新key的encoder是使用队列dictionary的核心。
2.3.3 算法的伪代码

这是一个整体的算法的流程,看了会有更加清晰的认识~
3.实验
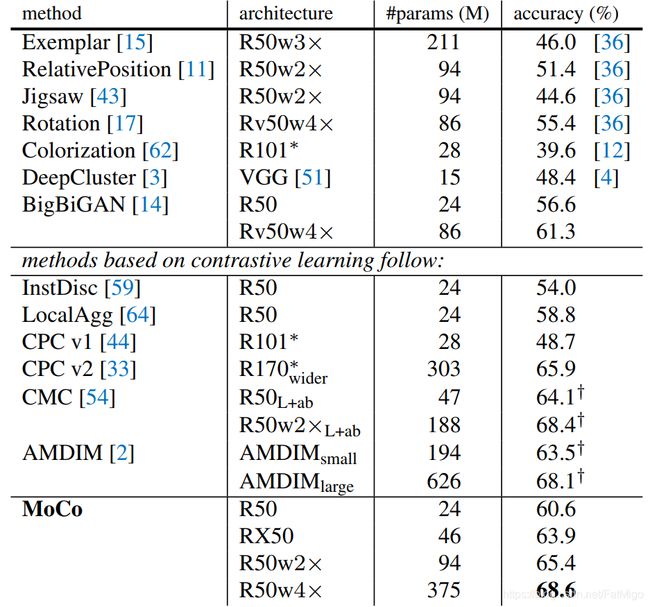
3.1 无监督设置下的分类任务
不出意外,state-of-the art不在话下,在ImageNet的无监督setting下,实验结果如下图
3.2 下游任务的结果
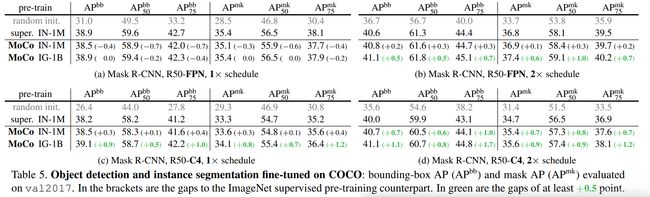
此外,本文还很详详详详详详详详~~~~~~~~~~~~~~~~~~~~~详尽地在很多下游任务,验证了MoCo的有效性,包括物体检测、物体分割等。
在很多下游任务,大家都爱用ImageNe上pretrain参数作为初始化,然后进行finetune,本章直接用MoCo和ImageNet的有监督pretrain开撕,很多领域上都达到了相当甚至远超于的效果。实验实在太详详详详详详详详~~~~~~~~~~~~~~~~~~~~~详尽了,所以只是简单地展示几个。
super In-1M表示用ImageNet的监督信息训练的pretrain参数
MoCo In-1M表示在ImageNet上用无监督的方式训练出的pretrain参数
MoCo IG-1B表示在Instagram爬去的1billion数据上用无监督的方式训练出的pretrain参数
3.2.1 检测和分割
3.2.2 pose和densepose等

4.总结
不出意外,这个无监督模型需要用64个卡炼足72小时。可想而知,整个探索过程,得需要多少张卡多少时间才能得到最终模型的参数以及结构。真的,不得不佩服恺明的工作,尽管有人说别人就是卡多,但是如果缺乏对问题和模型精准的嗅觉以及判断,再多的卡都是白费。
从实验结果来看,这实验也太solid了吧,不是在某个benchmark上实现提升,而是在很多基础领域都实现了超越,太可怕了吧!!!!真的给恺明团队给跪了。
同样是炼丹,为什么别人炼的就是仙丹金丹,我炼的就是菜鸡的眼泪〒_〒