HashMap数据结构在JDK1.8长度为8不一定会转成红黑树哦
第一次使用画思维导图的方式做笔记。这篇先写数据结构

数据结构
- JDK1.7 数组+链表
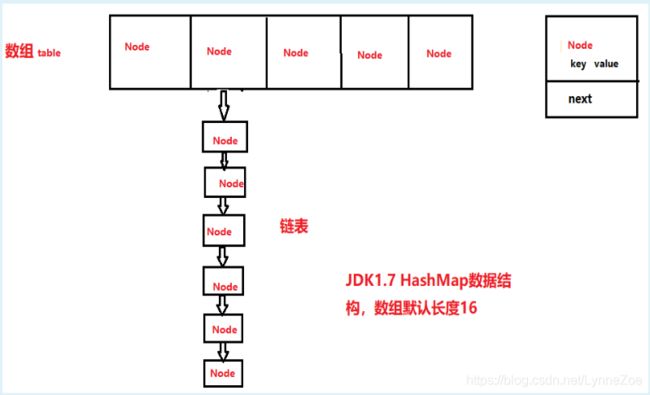
结构
HashMap基本结构是一个数组,每个数组的元素,都是一个链表的节点,包含的内容就是我们要存储的:key,value和链表指向下个节点的地址next
添加——寻址
HashMap在put一组key-value值的时候,是怎么确定它们该放在哪个位置呢?这里用了一个Hash算法公式
index = HashCode(key) & (length-1)
index 最终放元素的索引
HashCode(key) 得到key也就是键值的HashCode值
length 指的的是当前数组的长度,默认16。
源码是这样


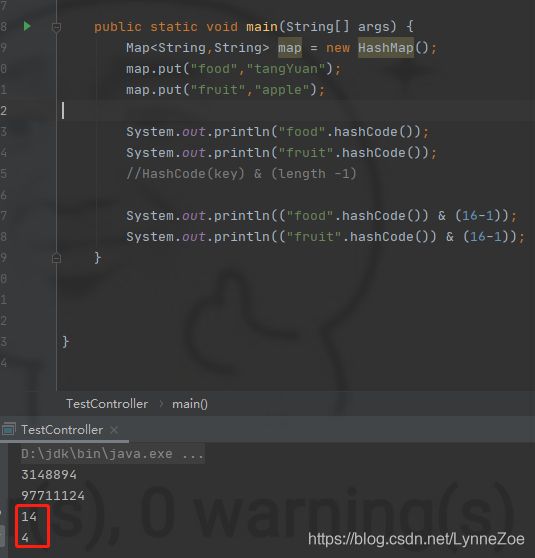
现在向一个key-value都为String的HashMap中插入两组值
Map<String,String> map = new HashMap();
map.put("food","tangYuan");
map.put("fruit","apple");
计算HashCode值

计算在HashMap中索引,分别是14和4,知道了索引,相当于知道了他们在HashMap中的位置。可以输出HashMap来验证是不是这样,遍历数组可以肯定先输出fruit-apple.
输出结果
此时它们在HashMap中存储位置,就是。。。。。。
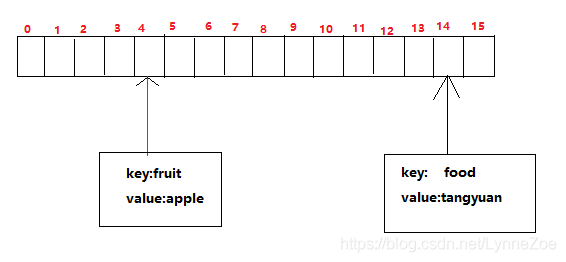
像这样通过计算一个个插入一直都是一个数组,直到插入元素个数为负载因子的值的时候再扩容,length值变成32,重新计算重新放入不就好了吗?那什么时候会变成一个链表的结构呢?
Hash碰撞(这个大佬出现时候就会用链表方式存储)
什么是哈希碰撞?
简单来说就是不同值的通过Hash算法得到的哈希值一样

比如“Aa”和“BB”这两个字符串,他们的hash值就是一样的,此时把它们分别put到HashMap中,就出现下标为0的地方,两个Node(或者说两个Entry)。
碰撞,先put进去的人占了位置,后来的人发现我也该在这个位置,这可怎么办呢(打一架,是可不能的)
解决哈希碰撞的方法: —— 链地址法(拉链法)
当然这只是解决hash碰撞的方法之一,HashMap采用的这种方法,所以HashMap的数据结构就从数组又加入了链表,然后最后结果是:
以下是HashMap在JDK1.7和JDK1.8的第一点不同
- JDK1.7采用头部插入法,所以后put进去的值,排在前面,和我们平时的先来后到刚好相反。(都让让,让让)

- JDK1.8就变了,变成了尾部插入,变成了我们熟悉的先来后到(新来的,自己去后边排队)

接下来是第二点不同:在hash碰撞的值数量达到8的时候(当前长度为8,添加第9个元素的时候,就转成红黑树)
JDK1.8要么扩容,要么变成红黑树
JDK1.7仍然是单链表

从算法角度分析,
查找过程中,链表的复杂度:O(n)
红黑树复杂度:O(log(n))
当然它不会一直都是红黑树,树长度小于等于6的时候,又会转回链表
为什么要转回链表呢?
红黑树,也叫自平衡二叉树,红黑树根节点是黑色,它的自平衡体现在,插入或删除元素的时候,它自平衡会通过两种方式调整
- 红黑树怎么保持平衡?
1.变色
2.旋转(左旋或者右旋)
所以如果树节点长度太小,再往里面put值得时候,红黑树就会不断去通过变色,旋转来保持平衡。这样跟链表比起来,当然链表性能更好些
红黑树后面专门写吧
