Hadoop2.X的安装部署
**
任务一、配置基础环境(主机名、名字解析、ssh免密码登录、jdk环境) 运用centos7镜像
**
1. 克隆3台虚拟机,设置IP地址和主机名,使得3台虚拟机以及主机互通
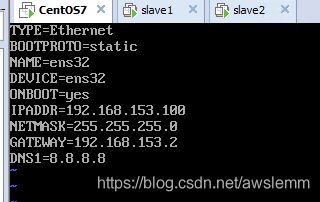
a) 编辑/etc/sysconfig/network-scripts/ifcfg-ens32文件,修改IP地址
![]()
master
slave1
修改IP为192.168.153.101
slave2
修改IP为192.168.153.102
修改 vim /etc/hosts

这里三个都一样
修改 vim /etc/hostname
分别为master slave1 slave2
然后三台虚拟机重启
检查三台虚拟机是否可以通过ping slave1通
2. 配置ssh免密码登录,使得3台虚拟机可以免密码互相登录
a) 在每台虚拟机上安装openssh-clients,并使用#ssh-keygen -t rsa生成密钥对
b) 把三台虚拟机的公钥集中到一个authorized_keys文件中,并发送到所有虚拟机
cd /root/.ssh
cp id_rsa.pub authorized_keys
编辑vim authorized_keys把其他slave1和slave2的pub文件都复制过来
scp -r authorized_keys root@slave1:/root/.ssh
scp -r authorized_keys root@slave2:/root/.ssh
c) 在master上使用ssh免密码登录slave1和slave2
ssh slave1
ssh slave2
3. 安装jdk,配置环境变量
a) 下载jdk,解压到/usr/local/jdk1.8
b) 编辑/etc/profile文件,设置环境变量
export JAVA_HOME=/usr/local/jdk1.8
CLASSPATH=.:${JAVA_HOME}/jre/lib/rt.jar:${JAVA_HOME}/lib/dt.jar:${JAVA_HOME}/lib/tools.jar
export PATH=$PATH:${JAVA_HOME}/bin
c) 使用#source /etc/profile命令执行脚本
d) 使用# java -version 检查java环境
**
任务二、安装hadoop集群
** 1. 在master上安装hadoop
a) 建立hadoop工作目录/var/hadoop
mkdir /var/hadoop/tmp
mkdir /var/hadoop/var
mkdir /var/hadoop/dfs
mkdir /var/hadoop/dfs/name
mkdir /var/hadoop/dfs/data
b) 下载hadoop软件并上传到master虚拟机,并解压到/usr/local/hadoop2
c) 编辑/usr/local/hadoop2/etc/hadoop下的配置文件
i. hadoop-env.sh
export JAVA_HOME=/usr/local/jdk1.8
ii. yarn-env.sh
export JAVA_HOME=/usr/local/jdk1.8
iii. mapred-env.sh
export JAVA_HOME=/usr/local/jdk1.8
iv. core-site.xml
hadoop.tmp.dir
/var/hadoop/tmp
fs.default.name
hdfs://master
v. hdfs-site.xml
dfs.name.dir
/var/hadoop/dfs/name
dfs.data.dir
/var/hadoop/dfs/data
dfs.replication
2
vi. yarn-site.xml
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.resourcemanager.address
master:8032
yarn.resourcemanager.scheduler.address
master:8030
yarn.resourcemanager.resource-tracker.address
master:8031
yarn.resourcemanager.admin.address
master:8033
yarn.resourcemanager.webapp.address
master:8088
vii. mapred-site.xml
cp mapred-site.xml.template mapred-site.xml
mapreduce.framework.name
yarn
viii. slaves
slave1
slave2
- 在其它虚拟机安装hadoop
a) 从master拷贝jdk到slave1和slave2
scp -r /usr/local/jdk1.8 root@slave1:/usr/lcoal
scp -r /usr/local/jdk1.8 root@slave1:/usr/lcoal
b) 从master拷贝/etc/profile到slave1和slave2并执行脚本
先配置一下Hadoop
vim /etc/profile
export PATH=$PATH:/usr/local/hadoop2/bin
scp /etc/profile root@slave1:/etc/profile
scp /etc/profile root@slave2:/etc/profile
c) 从master拷贝工作目录到slave1和slave2
scp /var/hadoop root@slave1:/var
scp /var/hadoop root@slave2:/var
d) 从master拷贝hadoopslave1和slave2
scp /usr/local/hadoop2/ root@slave1:/usr/local
scp /usr/local/hadoop2/ root@slave2:/usr/local
- 在master上执行hdfs初始化
cd /usr/local/hadoop2/bin
./hadoop namenode -format
任务三、启动、停止hadoop集群
cd /usr/local/hadoop2/sbin
./start-all.sh
jps查看是否完全启动
访问以下端口
50070:hdfs文件管理
8088:ResourceManager
8042:NodeManager