网络层概念学习之一(基本概念、路由器、选路算法)
网络层建立在链路层之上,它的最主要的功能是使得网络中的各个主机之间可以互相通信。在因特网中,IP层是TCP/IP协议族中最为核心的协议,也是最复杂的层次之一。
一、概述
1.转发和选路
2.网络服务功能
- 确保服务:确保能最终到达目的地
- 具有时延上届的确保交付:不仅确保交付,而且确保在时延上届内交付
- 有序分组交付:确保分组按照它们被发送的顺序到达目的地
- 确保最小带宽:只要发送主机以低于特定比特率的速录传输,分组就不会丢失
- 确保最大时延抖动:发送方发送两个连续分组的时间间隔和接收方接收它们的时间间隔之间的差值在一定范围内
- 安全性服务:使用仅仅发送方和接收方所知晓的密钥通信。
但是因特网的网络层提供的是无连接的不可靠的服务,尽力而为的服务,其含义是:
- 不可靠:IP层不保证IP数据报能成功到达目的地。如果需要保证可靠传输,则需要使用其它协议,比如TCP。
- 无连接:IP不维护任何关于后续数据报状态的信息,每个数据报的处理是相互独立的。因此两个IP之间的多个报文可能乱序到达,可能走不同的路径。。。
3.分组转发
在因特网中,每当一个主机要发送一个分组时, 它就为该分组加上目的主机的地址,然后将该分组发送出去。
当分组在网络中向目的地传输时,它会经过一系列路由器。每个路由器都使用该分组的目的地址来转发给分组。每台路由器都由一个将目的地址映射到链路接口的转发表,每当分组到达时,路由器就利用分组的目的地址在转发表中查找一个合适的输出链路接口,然后路由器将分组从该输出链路接口发送出去。
在因特网中,路由器的转发表可以由选路算法或者管理员更新。由于转发表的修改可能发生在任意时刻,因而两个主机之间的分组在不同的时刻走的可能是不同的网络路径,并可能无序到达。
1.最长前缀匹配规则
网络前缀:是网络地址的前边某些连续比特。比如对于地址 11101111 11011110 1000000 00000001,其对应的8比特前缀为11101111 , 16比特前缀为11101111 11011110
在该规则下,路由器的转发表中记录的是网络前缀和输出链路接口之间的对应关系。当查转发表时,仍然利用目的地址来进行匹配,但是可能会有很多歌匹配,这个时候取匹配到的比特数目最多的表象作为命中表项,并根据它来转发分组。
二、路由器

输入端口:它接入输入的物理链路,和链路远端的数据链路层交互,并完成查找和转发功能,以使得输入分组能够进入到合适输出链路接口。对于控制分组,它则会进入选路处理器。
交换结构:它将路由器的输入接口连接到它的输出接口。
输出端口:存储经过交换结构发送给它的分组,并将分组发送出去。同时它执行和输入端口相反的链路层功能和物理层功能。
选路处理器:执行选路协议,维护选路信息和转发表。
1.输入端口
- 以树形结构存储转发表,树的每一级对应目的地址中的一个比特,如果地址比特位0则搜索其左子树,否则搜索右子树。采用这种结构,N比特的目的地址可以在N步之内找到相应的转发表项。
- 内容可寻址内存CAM,采用树形结构对于主干路由器来说还是太慢了,CAM允许将一个IP地址交给CAM,然后由CAM在常数时间内返回该地址对应的转发表项的内容。
- 将最近访问的转发表保存在高速缓存。
2.交换结构
通过交换结构,分组可以从一个输入端口交换到一个输出接口。三种交换技术:
经内存交换:输入端口和输出端口之间的交换是在CPU的直接控制下完成。分组到达时,端口通过中断方式通知选路处理器,该分组从输入端口被拷贝到处理器内存,然后选路处理器取出分组的目的地址,查找转发表找到输出端口,并将分组拷贝到输出端口的缓存中。这种模式下,转发吞吐量受限于内存带快。PC一般采用该方式。有些现代路由器也采用内存交换,但是与PC的区别在于查表和将分组存储到适当的存储位置是由输入线路卡上的处理器来执行的。
经总线交换:输入端口经一根共享总线直接将分组送到输出接口,不需要选路处理器的干预。这种模式下,路由器的交换带宽受限于总线带宽。
经一个互联网络交换:高端路由器一般采用该方式,它可以克服单一、共享式总线的带宽限制。纵横式交换机时一个由2n条总线组成的互联网络,它将n个输入接口和n个输入接口连接。

在这种由纵横式交换机构成的互联网络中任意两个端口之间都有自己的专用总线,因而可以克服单一、共享式总线的带宽限制。使用这种网络时,往往把长度变化的IP分组分片成固定尺寸的信元,加上标签通过互联网络进行交换,这些信元在输出接口再被装配成初始分组。这种方式能够极大的简化并加快通过互联网络的分组交换。
3.输出端口
4.排队
1.分组调度
- 先来先服务FCFS
- 加权公平队列,它在具有排队等待传输的分组的不同的端到端连接之间公平的共享输出链路。
2.队列管理
另外的一个问题是如果没有足够的缓存来缓存一个分组,是丢弃该分组,还是丢弃一个已排队的分组来为新的分组腾出空间。相关的策略通常为主动队列管理算法AQM。随机早期检测算法RED是一种常见的算法,其思想是为输出队列长度维护一个加权平均值:
- 当队列长度小于低的门限值Tmin时,不丢弃新到达的分组;
- 当队列长度介于Tmin和Tmax之间时,以一定的概率丢弃分组,且分组概率随着队列长度的增长线性增加,
- 当队列长度达到Tmax时,到达的分组全部被丢弃。
3.HOL
- 所有链路速率都相同
- 一个分组能够以与一个输入链路接收一个分组相同的时间从任意一个输入端口移动分组到给定的输出端口
- 输入队列按照FCFS工作

三、选路算法
1.选路算法的分类
- 全局选路算法:用完整的,全局性的网络信息来计算从源到目的的最低费用路径。这种算法通常称为链路状态算法即LS算法,因为该算法必须知道网络中每条链路的费用。
- 分布式选路算法:以迭代的、分布式的方式计算出最低费用路径。没有节点拥有关于所有网络链路费用的完整信息,而每个节点仅有与其直接相连链路的费用信息即可开始工作。然后通过迭代计算过程并与相邻节点交换信息,一个节点逐渐计算出到达目的节点或者一组目的节点的最低费用路径。
- 静态选路算法:随着时间的推移,路由的变化非常缓慢,同时是在人的干预下进行调整。
- 动态选路算法:能够在网络流量负载或者拓扑发生变化时改变选路路径。动态选路算法可以周期性的运行或者在拓扑或链路费用发生变化时直接运行。
2.链路状态选路算法
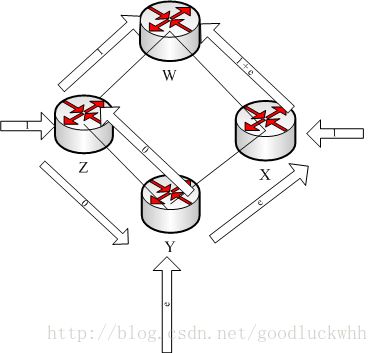
- 节点X和Z都发送到目的地W的一个单位的流量,且都选择它们与W直接相连的链路。
- Y有目的地为W的流量e,并走通过X到达W的链路。
- X,W之间的链路费用为1+e
- Y,X之间的链路费用为e
- Z,W之间的链路费用为1
- 节点X发现,它与W直接相连的链路的费用是1+e,而Y->Z->W这条路径的总费用是1,因而它选择走该链路
- 节点Y发现,它走X->W的费用是1+e,而走Z->W的费用是1,因而选择Z->W的路径。
- 节点Z的选路不变
- X,Y之间的链路费用为1
- Y,Z之间的链路费用为1+e
- Z,W之间的链路费用为2+e
- 节点X发现,它与W直接相连的链路的费用是0,而Y->Z->W这条路径的总费用是3+2e,因而它选择走与W直接相连的路径
- 节点Y发现,它走X->W的费用是0,而走Z->W的费用是2+e,因而选择走X->W
- 节点Z发现,它走Y->X->W的费用为0,而走直接连接W的链路的费用是2+e,因而它选择Y->X->W的路径
- Z,Y之间的链路费用为1
- Y,X之间的链路费用为1+e
- X,W之间的链路费用为2+e
3.距离向量选路算法
距离向量算法DV(Distance-vector)是一种迭代的、异步的和分布的算法:
- 分布式的:每个节点都要从一个活多个直接相连的邻居收集某些信息,执行计算,然后将结果发回个邻居。
- 迭代的:该过程要一直持续到邻居之间没有更多的信息要交换为止。
- 异步的:各个节点的操作不需要保持一致。
DV算法,利用了Bellman-Ford方程:
dx(y)=minv{c(x,v)+dv(y)}
其中dx(y)表示从节点x到节点y的最低费用路径的费用。c(x,v)的含义是节点x到其邻居v的路径费用。方程式的含义是从节点x到节点y的最低费用路径的费用等于所有邻居v中c(x,v)+dv(y)最小的那个。
在DV算法中,Bellman-Ford的一个重要的贡献就是,得到最小值的那个v节点就是当前节点向y转发时的下一跳节点,当需要向y转发时,只需要将分组送给节点v即可。算法思想:对于网络N中的素有节点,令Dx=[Dx(y):y属于N]是节点x的距离向量,该向量是从x到N中所有其它节点y的费用估计向量。每个节点x维护下列选路数据:
- 对于每个邻居v,从x到直接相连的邻居v的费用为c(x,v)。
- 节点x的距离向量,它包含了x到N中所有目的地的费用的估计值
- 它的每个邻居的距离向量,即对x的每个邻居v有Dv=[Dv(y):y属于N]
从邻居接收更新距离向量,重新计算选路表项和通知邻居到目的地的最低费用路径的费用已经变化的过程会一直持续知道无更新报文发送为止。DV算法被用于因特网的RIP和BGP。
1.距离向量算法:链路费用变化和链路故障
运行DV算法的节点在检测到其到邻居的链路费用发生变化时就会更新器距离向量,并且如果最低费用路径发生了变化,它就向邻居通知其新的距离向量。当链路费用降低时,DV算法可以就得到变化后的最低费用。但是如果是链路费用增加,则会出现一点问题,如下图所示拓扑:

- 链路费用变化前,网络拓扑如上图所示,则Dy(x)=4,Dy(z)=1, Dz(y)=1, Dz(x)=5,在t0时刻,y检测到链路费用变化(从4增加到40)。y会更新器最低费用路径,根据Bellman-Ford方程,其计算出来的值为6。但是观察这个时候的网络拓扑,显然这是不正确的。出现这个现象的原因是:y更新器距离向量时,利用了z通告给它的z的距离向量,Dz(x)=5,但是显然,Dz(x)是依赖于Dy(x)的,在Dy(x)变化后它显然是一个错误的值。更重要的是在这个时刻,会出现选路环路:为了到达x,y通过z选路,而z又选择通过y选路,这样的选路结果是分组无法到达目的地。
- y计算出来了一个新的到x的最低费用,因而它在t1时刻将新的距离向量通告给z
- z收到y的新的距离向量后更新其距离向量,它计算出来的新的Dz(x)=7
- 该过程一直循环,直到计算出来一个正确的值Dy(x)=40,Dz(x)=41
2.距离向量算法:增加毒性逆转
毒性逆转可以解决上述特定的网络拓扑中的环路状况。其思想是:如果z通过y选路,则z在通告y时会告诉y它(z)到x的距离是无穷大。毒性逆转只能解决这种特殊环路的问题,如果环路涉及到3个或更多的节点,则它也无能为力
3.LS和DV算法比较
DV算法中,每个节点仅与它的直接邻居交换信息,但它为它的邻居提供了通过它到达网络中(它所知道的)所有其它节点的最低费用估计。LS算法中,每个节点与所有节点交换信息,但它仅仅告其它节点与它直接相连的链路的费用。二者的比较
- 报文复杂性:LS算法要求每个节点都要知道网络中每条链路的费用,因而它需要发送O(|N||E|)个报文,而且无论何时一条链路的费用发生变化,都必须向所有节点发送新的链路费用。DV算法要求在每次迭代时,在两个直接邻居之间交换报文。当链路费用发生变化时,仅当新的费用导致与该链路相连的节点的最低费用发生了变化时,才会传播已改变的链路费用。
- 收敛速度:LS算法是一个O(n2)的算法,而DV算法收敛较慢,且在收敛时会遇到选路环路。
- 健壮性:由于LS算法中每个节点都独立的计算自己的路由,因而这在一定程度上提供了健壮性。而DV算法中一个节点的不正确信息则会扩散到整个网络。
4.层次选路
- 规模:因特网由上亿台主机组成,如果不采用层次选路,则路由器需要存储选路信息会需要极大的内存,而且如果采用LS算法,则可以预期网络将淹没在LS广播中无法工作;如果采用DV算法,可以预期它根本就不会收敛。
- 管理自治:某些组织可能倾向于按自己的意愿管理自己的网络,对外隐藏自己的内部网络面貌。
- 知道经过与自己的网关路由器相连的其它AS可以到达哪些目的地
- 在本AS内部传播这些可达信息
- 该网关路由器可以到达该目的地
- 该网关路由器到本路由器具有最低费用路径