QNX system architecture 6 - Process manager
进程管理器能够创建多个POSIX进程,每个进程可以包含多个POSIX线程。
在QNX Neutrino RTOS,procnto系统进程包含microkernel, 进程管理模块,内存管理模块和路径管理模块。因此进程管理模块并不是微内核的一部分。
- 进程管理 - 管理进程创建,销毁和进程属性比如uid和gid
- 内存管理 - 管理一定范围的内存保护能力,共享库,以及进程间的POSIX共享内存原语。
- 路径管理 - 管理路径空间
用户进程通过系统调用直接访问微内核,通过发送消息给procnto访问进程管理。注意用户进程通过MsgSend*()内核调用发送一个message。
注意,在procnto中调用微内核和在其他进程中是一样的。进程管理代码和微内核共享同一个地址空间,并不意味着它有特定的或者私有的接口。系统中所有的线程都使用一致的内核接口并且都会在调用内核接口时发生特权切换.
Process management
procnto的第一个职责是动态创建新进程。这些进程将会依赖procnto的其他功能:内存管理和路径管理。
进程管理包含了进程创建和进程销毁,以及进程属性的管理:比如进程ID,进程组ID和用户ID。
Process primitives
Process loading
使用exec*() posix_spawn或者spawn从文件系统加载进程。
如果文件系统存放在块设备上,代码和数据被加载到主存中。缺省情况下,包含二进制代码的内存页是按需加载的,但是你可以使用procnto -m选项改变它;更多的信息,参见本章中Locking memory小结
如果文件系统是内存映射的,比如ROM/flash image,那么代码不需要被装载到RAM中,而是在存储介质中直接执行。这种方法是在RAM中为数据和栈分配内存,代码则还是在ROM或者flash上。
不管代码以何种形式存放,如果相同的进程被加载多次,代码是共享的。
Memory management
某些实时内核在开发环境中提供了内存保护支持。随着内存保护在嵌入式处理器上变得越来越普及,引入内存管理所带来的性能损失越来越微不足道。
在嵌入式应用中特别是关键任务系统中增加内存保护的最大好处:是改善了系统健壮性。
通过内存保护,如果在多任务系统中一个进程试图非法访问内存,MMU硬件可以通知OS,然后系统会abort线程。
这防止进程间内存地址空间的滥用,防止一个进程错误的代码破坏另外一个进程甚至OS的内存。这个保护对于和集成实时系统是非常重要的,因为这使得事后分析称为可能。
在开发阶段,通常代码错误(比如野指针和数组越界)可能会导致一个进程或者线程破坏另外一个进程的数据空间。如果覆盖的内存在短时间内没有被使用,错误会变得更难跟踪,可能会花费数小时复杂的调试手段,比如使用电路模拟器或者逻辑分析仪,来发现犯罪方。
通过使能MMU,OS可以忽略掉进程非法内存访问的企图,并且立刻向程序员提供反馈,避免系统在随后某个时间神秘的崩溃。OS可以提供非法访问的指令位置,甚至非法指令的调试符号。
Memory Management Units(MMUs)
一个典型MMU操作,划分物理内存为4-KB的page。处理器硬件使用保存在系统内存中的页表定义虚拟地址到CPU物理地址的映射。
当线程执行时,OS管理的页表决定线程内的逻辑地址如何映射到处理器的物理内存。
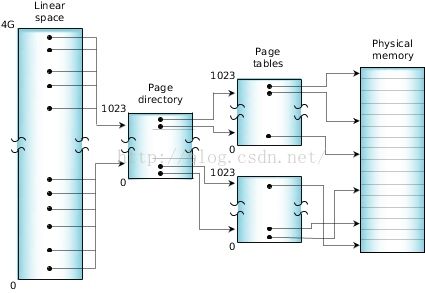
Figure 32: Virtual address mapping(on an x86)
如果系统内线程和进程很多,地址空间很大,需要描述这个映射的页表项数目变得非常可观,已经无法保存在处理器中。为了保证系统性能,处理器会caches经常使用的页表项到TLB中。
TLB cache可能会导致cache misses,OS要尽量避免由此带来的性能损失。
页表项中定义了内存中page的属性。Pages可以是只读,读写等等。典型的,可执行进程通常把代码页标记为只读,data和statck为可读写。
当OS执行上下文切换时(比如一个进程执行了挂起操作,恢复了另外一个进程执行)。这将操作MMU为新进程使用一组不同的页表。如果OS是在一个进程内的两个线程之间切换,那么MMU刷新是不必要的,因为同一进程的两个线程共享相同的地址空间。
当新进程恢复执行,新进程的任何地址转换都是通过新的页表生成。如果线程试图访问一个未映射的地址,或者试图访问一个地址但又不遵守页面访问权限,那么CPU会收到一个fault错误(类似一个除0错),OS实现一个特殊类型的中断。
通过检查压入中断栈中的指令地址,OS可以判断出引发fault的指令地址,并作进一步处理。
Memory protection at run time
在开发阶段内存保护是有用的,它可以提供嵌入式系统的可靠性。许多嵌入式系统已经采用了硬件watchdog 来检测软件或者硬件是否已经失控,但是这个办法和MMU相比,缺少精确性。
硬件watchdog通常实现为一个可重新触发的定时器,如果系统软件没有定期的复位定时器,定时器超时将会引发处理器reset。典型的,系统软件部件将检查系统完整性,并且更新时钟指示系统工作良好。
尽管这个方法可以把系统从软件或者硬件的错误中恢复过来,但是由于整个系统重启,因此导致重启时系统有一段时间不可用。
Software watchdog
在内存保护系统中,当一个间歇性软件错误发生后,OS可以捕捉到这个时间,并且把控制权转给一个用户线程而不是内存dump机制。这个线程可以进一步判断如何从失败中恢复过来,而不是简单粗暴的reset系统。软件watchdog可以:
- 中止触发内存访问失败的进程并重启这个进程,而不是关闭系统的其余部分。
- 中止失败的进程和相关的进程,初始化硬件到一个安全的状态,然后重新启动失败进程和相关进程。
- 如果失败非常关键,那么关闭整个系统,并发出声音警告。
这里最重要的区别是我们保留智能的,可编程的控制,即便控制软件的个别进程和线程由于某些原因失败。硬件watchdog仍然可以用来恢复系统。
当我们在执行某种恢复策略时,系统可以收集软件失败的各种信息。比如,如果嵌入式系统包含或者访问了mass storage,软件watchdog可以生成按事件排序的dump files。我们可以使用这个dump文件来做时候诊断。
嵌入式系统通常使用这种部分重启方法来处理间歇性软件失效,而不会让用户体验到系统宕机,甚至注意到这些快速恢复软件失效。因为dump files是可用的,软件开发者可以检测和发现软件问题,而不需要随时紧急的到达现场。如果我们比较这个方法和硬件watchdog方法,明显我们倾向与前者。事后dump file分析对于任务紧急的嵌入式系统是非常重要的。不论何时紧急系统失败,需要尽力发现失败的根源以便可以修复它并且应用到其他系统上。
dump files包含了程序员修复系统所需要的信息,没有dump files,程序员并不比碰到系统crashed的用户直到更多。
Quality control
Full-protection model
我们的全保护模式重定位镜像中的所有代码到新的虚拟空间,使能MMU硬件并重置页表映射。这允许procnto启动一个正确的MMU-enabled环境。进程管理器然后接收这个环境,改变进程需要的页表映射。
Private virtual memory
在全保护模式下,每个进程都给定了自己的虚拟地址空间,一般来说2 ~ 3.5GB,进程切换和消息传递的性能代价受到两个私有地址空间进行地址空间切换复杂性的影响。
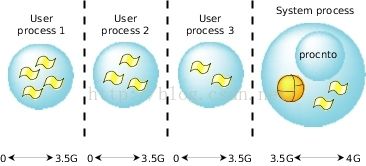
Figure 33: Full protection VM(on an x86)
每个进程花费在page table上的内存可能增加4KB~8KB。注意这个内存模型支持POSIX fork()调用。
Variable page size
虚拟内存管理器可以使用可变page尺寸,前提是处理器支持这个特性。
使用可变page size可以改善性能:
- 可以增加page size的尺寸,大于4KB。由此系统可以使用更少的TLB项
- TLB错失会变少
如果你想关闭可变page size功能,可以在procnto的buildfile中编辑-m~v选项,-mv选项则是使能可变page尺寸。
Locking memory
QNX支持POSIX内存锁定,所以一个进程可以避免取页延迟,通过锁定memory对应的page,所谓锁定,就是分配,并且不准交换到交换分区中。
锁定分为如下几种级别
- Unlocked
不锁定的内存可以换入换出。内存虽然被分配了,但是page table项并没有创建。第一次对内存的访问可能会失败,线程在WAITPAGE状态等待直到内存管理器初始化内存并创建页表项。
- locked
锁定的内存不可以换入或者换出。尽管在访问或者引用时仍然会发生page faults,来维护使用和修改统计。用户认为的PROT_WRITE页面可能仍是PROT_READ。这样,在第一次对MAP_PRIVATE页面执行写操作时,内核会收到警告:MAP_PRIVATE页面现在必须要私有化。
lock或者unlock一个线程的内存区域,可以调用mlock()和munlock();lock或者unlock线程所有内存区,可以使用mlockall()和munlockall()。内存保持锁定直到进程unlocks,进程退出,或者调用exec*()函数。如果进程调用fork(),posix_spawn*()或者spawn*()函数,在子进程中内存锁会被释放。
多个进程可以lock相同的内存区,内存会保持lock直到所有的进程都unlock它。内存锁不支持stack,如果一个进程lock同一段区域多次,那么unlock一次即可以取消该进程之前所有的lock操作。
lock所有应用的所有内存,procnto使用-ml选项。因此所有的pages至少被初始化。
- superlocked
不允许有faulting发生,所有的内存在映射时都被初始化,privatized以及设置权限。supoerlocking会覆盖线程的整个地址空间。
supoerlock所有应用的所有内存,procnto标识-mL选项。
对于MAP_LAZY映射,上面类型的内存在第一次引用之前并不会被分配。一旦被引用后,才会遵守以上规则。如果在critical代码区(比如禁止中断或者在ISR中),使用了从未引用的MAP_LAZY 区域,那么编程者要对此负责。
Defragmenting physical memory
大部分计算机用户都很熟悉disk随便整理的概念,随着时间的推移,磁盘空闲空间被分割为许多小块,散布在已使用块之间。物理内存分配和释放存在类似的问题,随着时间的推移,系统物理内存也会渐渐碎片化。最终,尽管空闲物理内存的总量非常大,但是由于碎片化,导致请求分配一块连续物理内存失败。
通常需要使用DMA的设备驱动会需要连续物理内存。一种解决办法是确保所有驱动都尽可能早的初始化(碎片发生前),并且获取所需的内存。这是个很不好的限制,特别是对于嵌入式系统可能只是根据用户动作启动相应驱动;同时启动所有可能的驱动,看起来相当的不灵活,而且浪费资源。
QNX使用一套分配和回收算法来显著的减少内存碎片的发生。然后,无论算法多么精妙,特定的行为仍然会导致内存碎片化。