论文笔记Meta-SR: A Magnification-Arbitrary Network for Super-Resolution
目录
一、创新点
二、模型结构
1.Feature Learning Module
2.Meta Upscale Module
1)位置投影Location Projection
2)权重预测Weight Prediction
3)特征映射Feature Mapping
三、实验细节
四、结果
1.不同采样因子Meta-RDN与RDN、EDSR结果对比
2.运行速度对比
3.与state-of-the-art模型性能对比
4.生成SR展示
本文出自中科院、CASIA、旷视、清华等机构。模型功能性突出,已被CVPR2019接收。
原文地址:http://arxiv.org/abs/1903.00875v1
代码地址:https://github.com/XuecaiHu/Meta-SR-Pytorch
一、创新点
引入元学习的思想构造Meta-Upscale Module,首次实现LR图像通过单模型进行任意尺度的上采样,通过动态预测上采样卷积参数,在应用上达成类似在图片查看器中滚动滑轮查看图片的效果。
二、模型结构
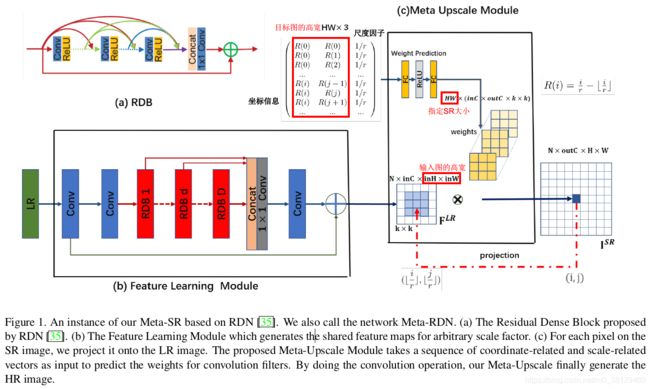
整个网络分为两个模块:Feature Learning Module和Meta Upscale Module。这里主要讲下Meta Upscale Module。
1.Feature Learning Module
Feature Learning Module其实就是RDN模型,模型细节参考这里。这里RDN如图1所示使用的3个卷积层和16个RDB(Residual Dense Block),每个RDB包含8个卷积层,其growth rate设为64,即特征通道为64。
注意,这里使用RDN是因为它的效果最好。同样也可使用EDSR、RCAN等其他模型前端作为Feature Learning Module。
2.Meta Upscale Module
这个模块依据Meta Learning的思想,学习对应不同因子上采样的卷积核数量及权重参数。关于元学习(Meta Learning),又称Learning to learn,具体百度,其中权重预测是Meta Learning的主要应用方向之一。
Meta Upscale Module本质是一个FC网络,能生成对应不同上采样因子SR的卷积核数量及参数,这里由FC层+ReLU层+FC层构造。由于网络输入输出维度差别较大,FC层神经节点数设置为256。
网络输入Size是3,输出Size是![]() (将其构造成多个
(将其构造成多个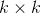 大小的卷积核),共计输入输出
大小的卷积核),共计输入输出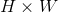 组,即图像的每个像素点送入模型作预测。这里的输出维度满足Feature Learning Module提取的特征图数(即
组,即图像的每个像素点送入模型作预测。这里的输出维度满足Feature Learning Module提取的特征图数(即![]() )、生成SR图像通道数(
)、生成SR图像通道数(![]() ,灰度图为1,RGB图为3)及两者的卷积核大小(,这里设为
,灰度图为1,RGB图为3)及两者的卷积核大小(,这里设为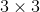 ),这三者乘积即为输出维度数。
),这三者乘积即为输出维度数。
上采样模块在运算上可分解为三个函数,即Location Projection,Weight Prediction,Feature Mapping。
1)位置投影Location Projection
对每个SR图像的像素点 ,要找到LR图上一点与之对应,并认为由该SR像素值由该LR点生成。找到对应点的方法:
,要找到LR图上一点与之对应,并认为由该SR像素值由该LR点生成。找到对应点的方法:
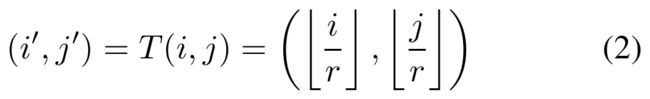
实际就是一个向下取整,通过每个目标SR像素坐标找到其在LR上的投影位置,一维图示如下:

----------------------------------------20190403更新-----------------------------------------
个人感觉这种位置邻近的方法不太合理,特别是在像素灰度变化特别快的区域。
-----------------------------------------------------------------------------------------------------
2)权重预测Weight Prediction
一般的超分辨率深度模型在上采样阶段都会为不同上采样因子指定filter的数目并学习到对应的filter参数,这里的filter参数即为目标SR像素点投影到![]() 特征像素区域的各点权重。而本文依据Meta Learning的思想,构造了一个权重预测模型,学习对应不同因子上采样的卷积核数量及参数。
特征像素区域的各点权重。而本文依据Meta Learning的思想,构造了一个权重预测模型,学习对应不同因子上采样的卷积核数量及参数。
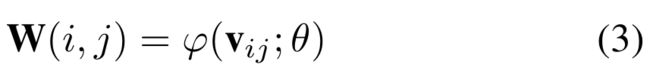
这里![]() 即为权重预测模型,W()为学得的对应坐标点的filter参数,
即为权重预测模型,W()为学得的对应坐标点的filter参数,![]() 为像素相关的向量,这里是关于
为像素相关的向量,这里是关于![]() 的相对偏移量(Why???),同时加上尺度因子(为什么是1/r而不是r),公式为:
的相对偏移量(Why???),同时加上尺度因子(为什么是1/r而不是r),公式为:
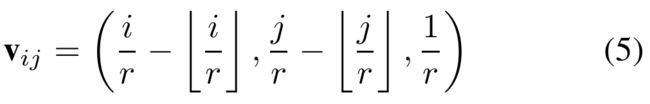
加上尺度因子目的是区分因子不同但像素位置相同学得的参数,因为在不添加尺度区分的情况下,对应LR上相同像素位置的不同因子的SR点学到的参数是等同的,也即生成的低倍率SR图是高倍率SR图的子图,这将极大限制模型表现。
3)特征映射Feature Mapping
目的是将每个LR点提取到的特征![]() 结合对应参数映射为目标SR的像素点,这里直接使用的矩阵积,即:
结合对应参数映射为目标SR的像素点,这里直接使用的矩阵积,即:
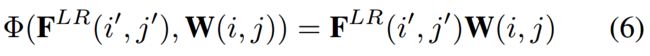
从原理上无法理解为什么通过矩阵积这种方式即可得到目标SR图(生成特征和特征权重是如何对应上的?)。但从数学角度去理解,整个计算过程也即矩阵运算嵌套卷积运算,原本矩阵积是要矩阵内部对应元素(元素为数值)相乘得到结果,而这里是对应元素(元素为矩阵)进行卷积得到结果。矩阵Size变化如下:
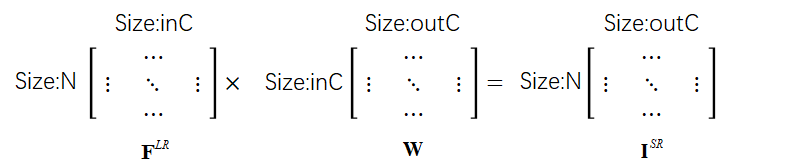
如图一所示,Feature Learning Module提得特征![]() 的Size为
的Size为![]() ,这里
,这里![]() 为输入图的高宽,因为是对其进行卷积操作,所以其大小不影响矩阵运算结果。
为输入图的高宽,因为是对其进行卷积操作,所以其大小不影响矩阵运算结果。
Meta Upscale Module预测结果的Size为![]() ,这里的、
,这里的、![]() 为目标SR的高宽、通道数;为网络预测出的卷积核大小,这里设置的,其大小也与矩阵运算无关。因此最后得到的结果为
为目标SR的高宽、通道数;为网络预测出的卷积核大小,这里设置的,其大小也与矩阵运算无关。因此最后得到的结果为![]() ,
, 是人为设定的生成SR图数量。
是人为设定的生成SR图数量。
Meta Upscale Module算法伪代码:

三、实验细节
训练集:DIV2K for training
测试集:Set14,B100,Manga109,DIV2K for testing
评价方法:PSNR,SSIM
训练过程:双三下采样;旋转数据增强;目标函数采用L1损失以确保更好的收敛;batch size 16,input size 50*50;ADAM;训练的尺度因子从1到4,最小变化单位0.1。采用4个并行GPU P40训练。
四、结果
1.不同采样因子Meta-RDN与RDN、EDSR结果对比
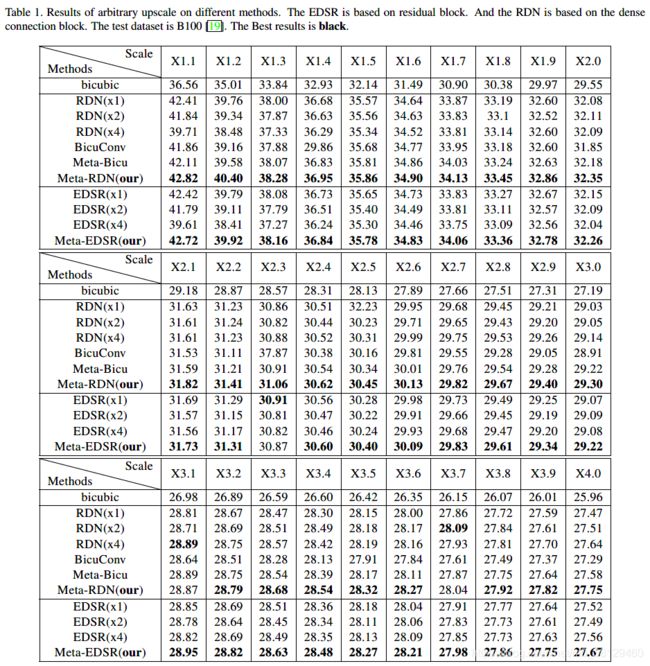
可以看到Meta Upscale Module表现还是很好的。
2.运行速度对比

3.与state-of-the-art模型性能对比

4.生成SR展示
可以看到,较大倍率的SR图像视觉感知效果不是特别好,细节纹理都比较模糊,个人感觉仍可提高。