一文看懂网络上采样层中的 align_corners
点击我爱计算机视觉标星,更快获取CVML新技术
本文来自于知乎专栏语义分割探索之路,经作者立夏之光授权转载,未经允许请勿二次转载。
https://zhuanlan.zhihu.com/p/87572724
上采样层 (upsample layer),是语义分割等密集输出 (dense prediction) 任务的必备组件。一般默认选择双线性插值 (bilinear) 或者最近邻 (nearest) 的方式。这两种方式在 pytorch 的 interpolate 函数中均有实现。关于它们如何实现,已有好多博客解读。但是 bilinear 情况下,会伴随一个选项 align_corners,默认为 False。关于这个选项的含义,pytorch 1.3.1 官网是如下解释的:

这个解释看起来令人似懂非懂。相比之下,pytorch 0.4.1 的解释更为模糊:

与此同时,熟悉语义分割任务的同学,会发现输入大小通常会设置为 8 的倍数加 1,比如 513 (PASCAL VOC) 或者 769 (Cityscapes)。好多同行会有这种疑惑:为什么不直接设置成 8 的倍数?
本文期望对如上问题做一个全面的解读。根据笔者了解,本文是全网第一篇解读 align_corners 的博文。本文还会对现有 libraries 插值是否 align_corners 做一个总结。看完本文后,相信读者能够全面理解这两个问题。
在接下来的图文中,我们默认以红色表示原图,蓝色表示插值上采样两倍后的图片。
首先介绍 align_corners=False,它是 pytorch 中 interpolate 的默认选项。这种设定下,我们认定像素值位于像素块的中心,如下图所示:

对它上采样两倍后,得到下图:
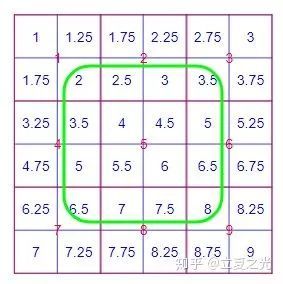
首先观察绿色框内的像素,我们会发现它们严格遵守了 bilinear 的定义。而对于角上的四个点,其像素值保持了原图的值。边上的点则根据角点的值,进行了 bilinear 插值。所以,我们从全局来看,内部和边缘处采用了比较不同的规则。对比绿色框内外,会有一种违和感。接下来,我们看看 align_corners=True 情况下,用同样画法对上采样的可视化:

这里像素之间毫无对齐的美感,强迫症看到要爆炸。事实上,在 align_corners=True 的世界观下,上图的画法是错误的。在其世界观里,像素值位于网格上,如下图所示:

那么,把它上采样两倍后,我们会得到如下的结果:

强迫症:“整个世界都整齐了”。这里仔细的读者会发现,3*3 的图像上采两倍后,变成了 5*5。更广泛地来讲,对于输入尺寸是 (2x+1) * (2x+1) 的图片,其经过 align_corners=True 的上采样后,尺寸变为 (4x+1) * (4x+1)。所以虽然内容上整齐了,外在的数目上,却没了那种 2 的整数次幂的美感。
下面,我们同时展示两种方法的示例图:

对于密集输出任务,“整整齐齐”才是王道。所以我们最优的选择是 align_corners=True 以及输入尺寸 8 的倍数加 1。这里 8 是因为 dilated ResNet 下采样 8 倍。
如上,我们讨论了上采样的选择。那么,我们对图像处理时,理想情况下,下采样也应该选择对应的方式。既然上采样 align_corners=True,下采样也理应 align_corners。接下来,我们调研下几个流行的图像处理库,看下它们的实现是用了哪种设置。对于输入 [[1, 2], [3, 4]]:
这里我们先列出 pytorch 的结果作为参考:

接下来是 cv2:

然后是 PIL:

还有 MXNet 的:

我们发现,cv2、PIL的插值都是 align_corners=False;MXNet 默认 True。而 pytorch 和 tensorflow 都是可选。为了保持和下采样时的操作对应一致,笔者建议大家进行密集输出任务的图像预处理时 (尤其是 resize 操作),放弃官方的 transform (PIL 实现) 以及 cv2 的实现,转而使用 pytorch 自己实现一份。
这里笔者提供自己 repo 中的代码作为参考,细节请见:
https://github.com/XiaLiPKU/EMANet/blob/master/dataset.py
综上,我们分析了 align_corners 的原理,解释了输入尺寸设置为基数的原因。并且笔者根据分析,推荐使用 pytorch 实现预处理中的 resize。
图像分割交流群
关注最新最前沿的语义分割、实例分割、全景分割技术,扫码添加CV君拉你入群,(如已为CV君其他账号好友请直接私信)
(请务必注明:分割)

喜欢在QQ交流的童鞋,可以加52CV官方QQ群:805388940。
(不会时时在线,如果没能及时通过验证还请见谅)

长按关注我爱计算机视觉