【目标跟踪】MemTrack:Learning Dynamic Memory Networks for Object Tracking
ECCV2018一篇用LSTM做tracking的文章,文章链接:MemTrack
Motivation:
作者主要是想解决基于模板匹配类算法对目标形变的适应性问题。 典型的模板匹配算法比如Siamese通常采用第一帧或者上一帧目标特征作为模板。采用第一帧为模板难以适应目标的形状变化,而直接用前一帧的目标特征作为模板又很容易因为累积性的误差导致跟踪漂移。所以作者提出用一个动态记忆网络来适应目标的形态变化,同时采用LSTM网络来控制目标特征的读取。
Contribution
- 提出了一个动态记忆网络(dynamic memory network)来适应外观的变化
- 提出了一个门控残差模板学习策略(gated residual template learning)来控制最终模板的生成,能够在初始特征之上添加适当的特征变化量。
Method
先来看看MemTrack的网络结构

两个主要的模块记忆模块和LSTM模块我分别用蓝色和绿色框表示了出来。记忆模块用来存储目标的外形特征,LSTM模块用来输出一系列的控制信号。整个的流程大概是:
候选区 S t S_t St输入 → \rightarrow → 特征提取 → \rightarrow → LSTM读控制信号 → \rightarrow → 读取记忆模块特征 → \rightarrow → 与原始特征模板融合生成最终模板 → \rightarrow → 模板匹配目标 → \rightarrow → 边界框回归 → \rightarrow → 提取目标特征 → \rightarrow → LSTM写控制信号 → \rightarrow → 存入新的目标特征 → \rightarrow → 提取下一帧候选区
LSTM控制模块

这幅图详细的描述了LSTM和记忆模块的交互结构,当前帧的特征向量 a t a_t at 和上一帧的隐藏状态 h t − 1 h_{t-1} ht−1 输入到LSTM,输出当前帧的隐藏状态 h t h_t ht ,然后用 h t h_t ht 计算一系列的控制信号
读控制信号
LSTM产生读控制信号用来将存储区内的不同特征加权求和,对于存储区 M t ∈ R N × n × n × c M_t \in R^{N\times n\times n\times c} Mt∈RN×n×n×c N表示存储的feature map 的数量,每个feature map 尺寸是 n × n × c n\times n \times c n×n×c, c是通道数。
LSTM通过 h t h_t ht 计算秘钥和强度:

其中 W k , W β , b k , b β W^k, W^\beta, b^k, b^\beta Wk,Wβ,bk,bβ 表示对应的权值矩阵和偏移量。
k t ∈ R c k_t \in R^c kt∈Rc 用来匹配存储区的内容, β t \beta_t βt 表示生成的秘钥的可信度。通过这两个参数,可以求得权重

k M t ( j ) ∈ R c k_{M_t(j)} \in R^c kMt(j)∈Rc 表示对应特征 M t ( j ) M_t(j) Mt(j) 的秘钥, C ( x , y ) C(x,y) C(x,y) 是一个余弦函数,用来度量 k t k_t kt 和 k M t ( j ) k_{M_t(j)} kMt(j) 的相似度。 w t r ( j ) w^r_t(j) wtr(j) 表示存储区内第 j 个特征在t帧的加权权重。最终,可以得到模板:

写控制信号
当得到了新的目标时,就需要考虑更新存储区的特征了。对于当前帧的模板,有三种可能情况:
- 当新的模板不可靠,选择不更新存储区的特征
- 当目标在当前帧外形变化不大,选择更新存储区特征
- 当目标在当前帧存在很大的外形变化,选择将当前帧的特征存储在一个存储槽内。
为了解决这三种case,作者提出了一种计算写权重的公式:

w t γ , w t a w^\gamma_t, w^a_t wtγ,wta 分别表示读取的权重和分配一个新空间的权重。三个门信号 g ω , g γ , g a g^\omega, g^\gamma, g^a gω,gγ,ga 由LSTM控制器生成:

分配权重 w t a ( j ) w^a_t(j) wta(j) 是这么定义的:

其中 w t u w^u_t wtu 表示访问向量:

表示对应特征被读取的频繁程度, w t u w^u_t wtu越大,表示该特征与当前的目标越像,而 w t u w^u_t wtu太小,则可能会被新的特征直接覆盖。最终,每个槽内的特征用以下公式更新:

e ω e^\omega eω 表示一个擦除因子,用来控制槽内的特征更新或者直接重写。
残差模板学习(Residual Template Learning)
作者提出一个残差模板学习的策略,使得最终的模板更够适应目标实时的变化,又不会完全受上一帧的影响而导致跟踪漂移。

T t f i n a l T^{final}_t Ttfinal 是最终的模板, T 0 T_0 T0 是初始模板, r t ∈ R c r_t \in R^c rt∈Rc 是一个LSTM生成的残差门控制参数,用来控制不同通道中模板的学习率。
Experiment
ablation study
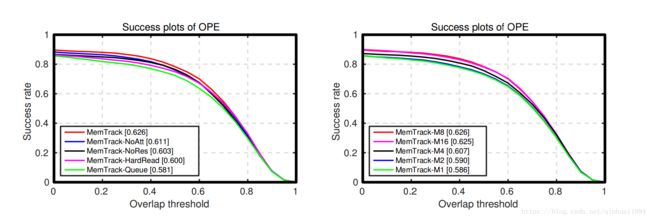
左边是不同components的涨点情况,右边是不同存储容量下的性能,在容量为8时达到饱和。
OTB2015
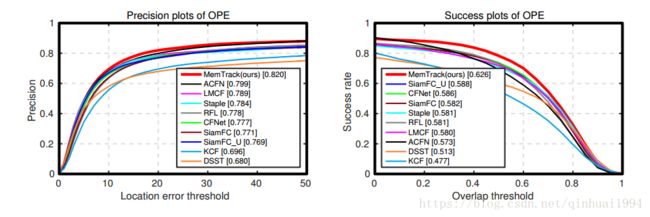
点不算很高,但考虑到速度(~50)和novelty,算是一个比较solid的工作。