Dremel made simple with Parquet(CN)
列式存储是在并行RDBM中优化分析工作负载的流行技术。在学术文献以及几个商业分析数据库中都充分记录了存储和处理大量数据的性能和压缩优势。
目的是通过仅从磁盘读取查询所需的数据来使I / O降至最低。使用Twitter上的Parquet,我们在大型数据集上的大小减少了三分之一。在仅需要一部分列的常见情况下,扫描时间也减少到原始时间的一小部分。原理很简单:代替传统的行布局,将数据一次写入一列。尽管在平面模式下将行变成列很简单,但是在处理嵌套数据结构时却更具挑战性。
我们最近引入了Parquet,这是一种用于Hadoop的开源文件格式,可提供列式存储。最初是Twitter和Cloudera的共同努力,现在它有许多其他贡献者,包括Criteo等公司。Parquet使用Google的Dremel论文中概述的技术以平面列格式存储嵌套数据结构。基于本文实现了该模型后,我们决定提供一个更易于理解的解释。我们将首先描述用于表示嵌套数据结构的通用模型。然后,我们将解释如何将该模型表示为平坦的列列表。最后,我们将讨论为什么这种表示有效。
为了说明列式存储的全部含义,下面是一个包含三列的示例。
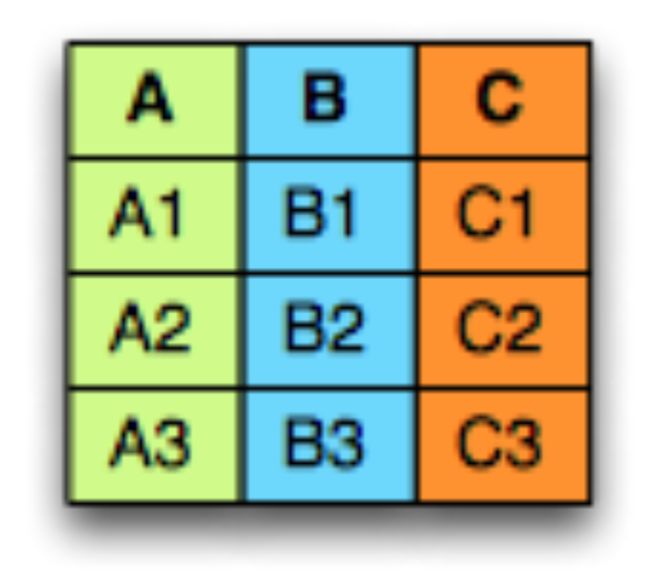
在面向行的存储中,数据一次排成一行,如下所示:

而在面向列的存储中,它一次只能布置一列:

列格式有很多优点。
- 按列组织可实现更好的压缩,因为数据更加均匀。在Hadoop集群的规模上,空间节省非常明显。
- I / O将减少,因为我们可以在读取数据时仅有效扫描列的子集。更好的压缩还减少了读取输入所需的带宽。
- 当我们在每一列中存储相同类型的数据时,通过使指令分支更可预测,我们可以使用更适合现代处理器流水线的编码。
The model
要以列式存储,我们首先需要使用Schema来描述数据结构。这是使用类似于协议缓冲区的模型完成的。此模型是极简主义的模型,它表示使用字段组进行嵌套和使用重复字段进行重复。不需要任何其他复杂类型,例如Maps,List或Sets,因为它们都可以映射到重复字段和组的组合。
Schema的root是一组称为消息的字段。每个字段具有三个属性:重复,类型和名称。字段的类型可以是组类型或原始类型(例如,int,float,boolean,string),而重复可以是以下三种情况之一:
- required: 恰好发生一次
- optional: 发生0或1次
- repeated: 发生0次或多次
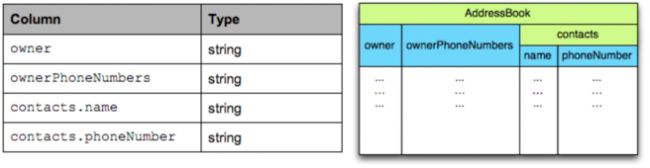
例如,以下是一种可能用于AddressBook的Schema:
message AddressBook {
required string owner;
repeated string ownerPhoneNumbers;
repeated group contacts {
required string name;
optional string phoneNumber;
}
}List(或Set)可以由重复字段表示。

Map等效于一个重复字段,其中包含需要键的一组键值对。

Columnar format
列格式通过将相同原始类型的值存储在一起来提供更有效的编码和解码。要以列格式存储嵌套数据结构,我们需要将架构映射到column的list中,以便可以将记录写入扁平式列结构并将其读回其原始的嵌套数据结构。在Parquet中,我们为Schema中的每个基本类型字段创建一列。如果我们将Schema表示为树,则原始类型是该树的叶子。
将AddressBook示例作为树:

为了以列格式表示数据,我们为每个基本类型单元格创建一列,以蓝色显示。
对于每个值,记录的结构由两个称为重复级别(repetition level) 和定义级别(definition level)的整数捕获。使用定义和重复级别,我们可以完全重建嵌套结构。这将在下面详细说明。
Definition levels
为了支持嵌套记录,我们需要存储字段为null的级别。这就是定义级别的含义:从Schema根目录的0到此列的最大级别。当定义了一个字段时,它的所有父对象也都被定义了,但是当它为null时,我们需要记录它开始为null的级别,以便能够重建记录。
例如,考虑下面的简单嵌套模式:
message ExampleDefinitionLevel {
optional group a {
optional group b {
optional string c;
}
}
}它包含一列:a.b.c,其中所有字段都是可选的,可以为null。定义c时,也必须定义a和b,但是当c为null时,我们需要保存null值的级别。有3个嵌套的可选字段,因此最大定义级别为3。
这是以下每种情况的定义级别:
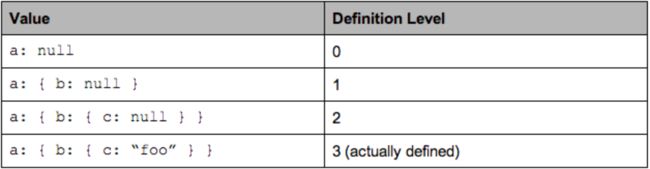
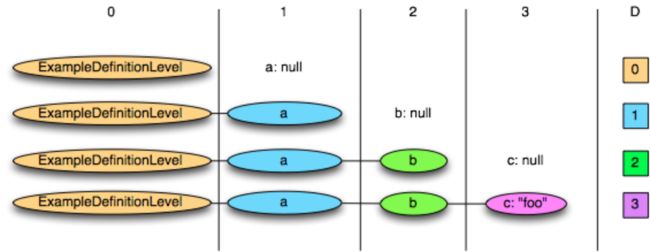
可能的最大定义级别为3,表示已定义该值。值0到2表示空字段出现在哪个级别。
必填字段始终已定义,不需要定义级别。让我们将相同的示例与字段b一起重新使用:
message ExampleDefinitionLevel {
optional group a {
required group b {
optional string c;
}
}
}现在最大定义级别为2,因为b不需要设置为一个定义级别。b下方字段的定义级别的值更改如下:

使定义级别小很重要,因为目标是将级别尽可能少地存储。
Repetition levels
为了支持重复的字段,我们需要存储何时在值列中开始新列表。这就是重复级别的用途:这是我们必须为当前值创建新列表的级别。换句话说,重复级别可以视为何时开始新列表以及在哪个级别开始的标记。例如,考虑以下字符串列表的表示形式:

该列将包含以下重复级别和值:

重复级别标记了列表的开始,并且可以按以下方式解释:
- 0标记每个新记录,并表示创建一个新的level1和level2列表
- 1标记每个新的level1列表,并表示也创建一个新的level2列表。
- 2标记了level2列表中的每个新元素。
在下图中,我们可以直观地看到插入记录的嵌套级别:
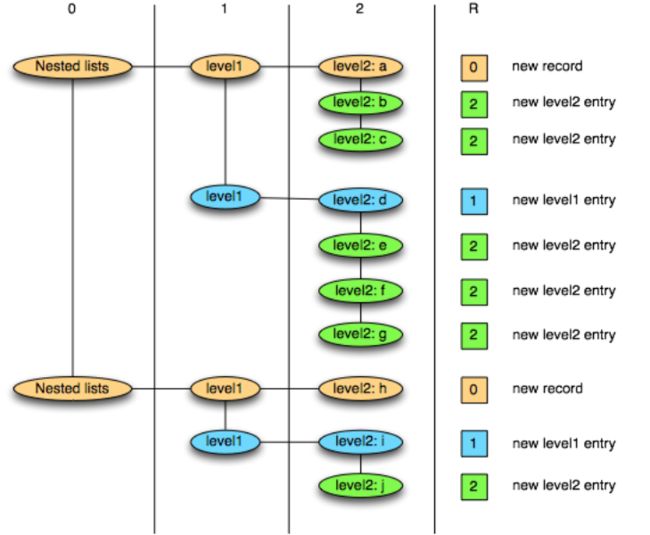
重复级别0表示新记录的开始。在平面模式中,没有重复并且重复级别始终为0。只有重复的级别才需要重复级别:可选字段或必填字段从不重复,并且在分配重复级别时可以跳过。
Striping and assembly
现在同时使用这两个概念,让我们再次考虑AddressBook示例。下表显示了每列的最大重复和定义级别,并解释了为什么它们小于列的深度:

特别是对于contacts.phoneNumber列,定义的电话号码的最大定义级别为2,而没有电话号码的联系人的最大定义级别为1.如果没有联系人,则为0。
AddressBook {
owner: "Julien Le Dem",
ownerPhoneNumbers: "555 123 4567",
ownerPhoneNumbers: "555 666 1337",
contacts: {
name: "Dmitriy Ryaboy",
phoneNumber: "555 987 6543",
},
contacts: {
name: "Chris Aniszczyk"
}
}
AddressBook {
owner: "A. Nonymous"
}现在我们将重点放在contacts.phoneNumber列上进行说明。
一旦投影,记录具有以下结构:
AddressBook {
contacts: {
phoneNumber: "555 987 6543"
}
contacts: {
}
}
AddressBook {
}该列中的数据如下(R = Repetition Level, D = Definition Level)
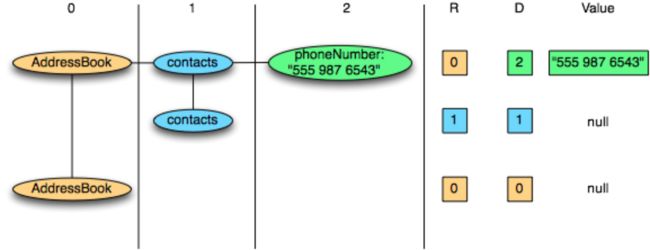
要写该列,我们遍历该列的记录数据:
- contacts.phoneNumber: “555 987 6543”
- new record: R = 0
- value is defined: D = maximum (2)
- contacts.phoneNumber: null
- repeated contacts: R = 1
- only defined up to contacts: D = 1
- contacts: null
- new record: R = 0
- only defined up to AddressBook: D = 0
这些列包含以下数据:
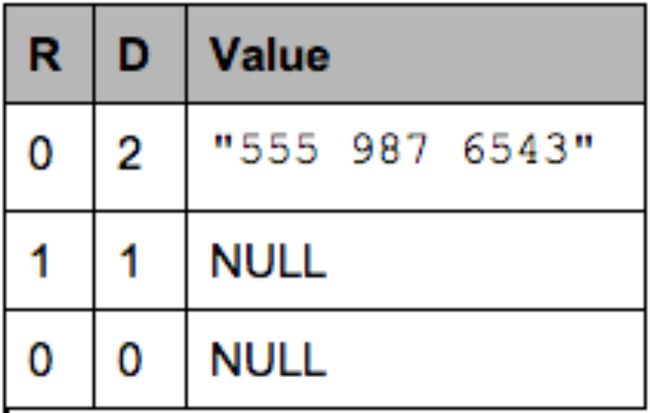
请注意,为清楚起见,此处显示的是NULL值,但根本没有存储。严格低于最大值(此处为2)的定义级别表示NULL值。
要从该列重建记录,我们遍历该列:
- R=0, D=2, Value = “555 987 6543”:
- R = 0 means a new record. We recreate the nested records from the root until the definition level (here 2)
- D = 2 which is the maximum. The value is defined and is inserted.
- R=1, D=1:
- R = 1 means a new entry in the contacts list at level 1.
- D = 1 means contacts is defined but not phoneNumber, so we just create an empty contacts.
- R=0, D=0:
- R = 0 means a new record. we create the nested records from the root until the definition level
- D = 0 => contacts is actually null, so we only have an empty AddressBook
有效地存储定义级别和重复级别
关于存储,这实际上可以归结为为每种基本类型创建三个子列。但是,由于采用了列式表示,因此存储这些子列的开销很低。这是因为级别受模式深度的约束,并且每个值仅使用几个位就可以有效地存储(一个位最多可以存储1个级别,2个位可以存储3个级别,3个位可以存储7个嵌套级别)。在上面的通讯录示例中,owner 列的深度为1,而`contacts.name列的深度为2。级别将始终以零作为下限,而列的深度始终作为上限。更好的是,不重复的字段不需要重复级别,而必填字段也不需要定义级别,从而降低了上限。
在带有所有必填字段的平面模式的特殊情况下(相当于SQL中的NOT NULL),重复级别和定义级别被完全省略(它们始终为零),并且我们仅存储列的值。实际上,如果必须仅支持平面表,则可以选择相同的表示形式。
这些特性使嵌套的表示非常紧凑,可以结合使用运行长度编码和位打包来有效地编码嵌套。包含很多空值的稀疏列将几乎压缩为空,类似地,实际上始终设置的可选列将花费很少的开销来存储数百万个1。在实践中,层级占用的空间可以忽略不计。此表示形式概括了如何表示平面模式的简单情况:顺序写入列的所有值,并且当字段为可选字段时使用位字段存储空值。