高并发应对策略
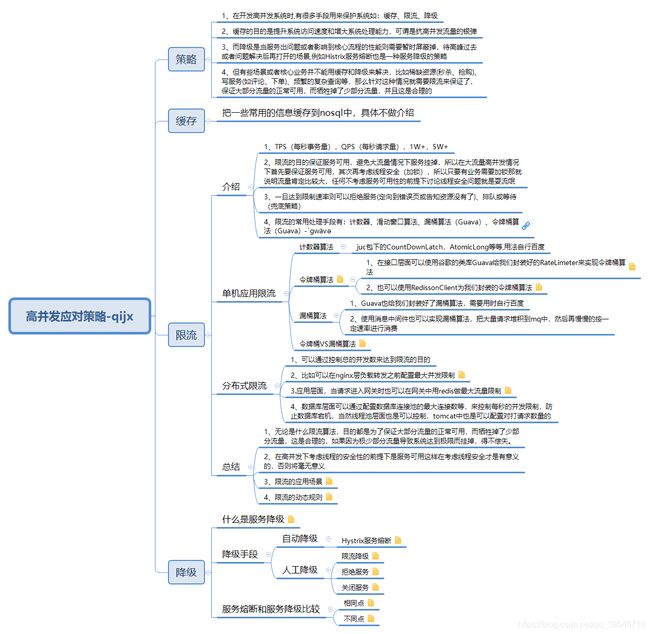
策略
1、在开发高并发系统时,有很多手段用来保护系统如:缓存、限流、降级
2、缓存的目的是提升系统访问速度和增大系统处理能力,可谓是抗高并发流量的银弹
3、而降级是当服务出问题或者影响到核心流程的性能则需要暂时屏蔽掉,待高峰过去或者问题解决后再打开的场景,例如Histrix服务熔断也是一种服务降级的策略
4、但有些场景或者核心业务并不能用缓存和降级来解决,比如稀缺资源(秒杀、抢购)、写服务(如评论、下单)、频繁的复杂查询等,那么针对这种情况就需要限流来保证了,保证大部分流量的正常可用,而牺牲掉了少部分流量,并且这是合理的
缓存
把一些常用的信息缓存到nosql中,具体不做介绍
限流
介绍
1、TPS(每秒事务量),QPS(每秒请求量),1W+,5W+
2、限流的目的保证服务可用,避免大流量情况下服务挂掉,所以在大流量高并发情况下首先要保证服务可用,其次再考虑线程安全(加锁),所以只要有业务需要加锁那就说明流量肯定比较大,任何不考虑服务可用性的前提下讨论线程安全问题就是耍流氓
3、一旦达到限制速率则可以拒绝服务(定向到错误页或告知资源没有了)、排队或等待(兜底策略)
4、限流的常用处理手段有:计数器、滑动窗口算法、漏桶算法(Guava)、令牌桶算法(Guava)-ˈgwävə
单机应用限流
计数器算法
juc包下的CountDownLatch,AtomicLong等等,用法自行百度
令牌桶算法
介绍:系统会以一定的速度生成令牌,并将其放置到令牌桶中,当令牌桶填满的时候,新生成的令牌会被扔掉。当一个请求过来时需要先拿到一个令牌才能去执行,否则等待或者直接拒绝
1、这里有两个变量很重要:第一个是生成令牌的速度,一般称为 rate ,比如,我们设定 rate = 2 ,即每秒钟生成 2 个令牌,也就是每 1/2 秒生成一个令牌;第二个是令牌桶的大小,一般称为 burst 。比如,我们设定 burst = 10 ,即令牌桶最大只能容纳 10 个令牌。
1、在接口层面可以使用谷歌的类库Guava给我们封装好的RateLimeter来实现令牌桶算法
RateLimiter limiter=RateLimiter.create(5);
double acquire1 = limiter.acquire();//阻塞式
boolean b = limiter.tryAcquire();//非阻塞式
1、RateLimiter.create(5) 表示桶容量为5且每秒新增5个令牌,即每隔200毫秒新增一个令牌;
2、limiter.acquire()表示消费一个令牌,如果当前桶中有足够令牌则成功(返回值为0),如果桶中没有令牌则暂停一段时间,比如发令牌间隔是200毫秒,则等待200毫秒后再去消费令牌,这种实现将突发请求速率平均为了固定请求速率。
2、也可以使用RedissonClient为我们封装的令牌桶算法
redis也为我们封装好了分布式令牌桶算法来限流
RRateLimiter rateLimiter = redissonClient.getRateLimiter("100");
rateLimiter.acquire();
boolean b = rateLimiter.tryAcquire();漏桶算法
1、Guava也给我们封装好了漏桶算法,需要用时自行百度
2、使用消息中间件也可以实现漏桶算法,把大量请求堆积到mq中,然后再慢慢的按一定速率进行消费
令牌桶VS漏桶算法
1、令牌桶算法可以处理突发请求,而漏桶算法只能恒定处理请求解释:
- 漏桶:有一个固定的桶,进水的速率是不确定的,但是出水的速率是恒定的,当水满的时候是会溢出的。所以是恒定的速率处理请求
- 令牌桶:生成令牌的速度是恒定的,而请求去拿令牌是没有速度限制的,这意味,如果当令牌桶中有足够的令牌,那么当面对瞬时大流量,该算法可以在短时间内请求拿到大量令牌,当流量趋于平稳时又可以像漏桶算法那样恒定的去处理请求
- 所以令牌桶算发较漏桶算法好一些,具体还要看使用场景
分布式限流
1、可以通过控制总的并发数来达到限流的目的
2、比如可以在nginx层负载转发之前配置最大并发限制
nginx中有配置文件可以配置瞬时最大连接数
Nginx每秒可支持的并发数量5万,假如后台最多能支持4万并发,那么就把Nginx的最大限制设为4万连接,然后4万请求打到单个应用时再去设置应用级别的限流策略
按照一定的规则如帐号、IP、系统调用逻辑等在Nginx层面做限流
Nginx是粒度最大的一层,这层的频度设置我们需要谨慎操作,这里将影响我们整个网站访问,
nginx黑名单:当我们发现一些恶意访问的IP之后我们可以把他们放到黑名单里,配置略3.应用层面,当请求进入网关时也可以在网关中用redis做最大流量限制
redis也为我们封装好了分布式令牌桶算法来限流
RRateLimiter rateLimiter = redissonClient.getRateLimiter("100");
rateLimiter.acquire();
boolean b = rateLimiter.tryAcquire();4、数据库层面可以通过配置数据库连接池的最大连接数等,来控制每秒的并发限制,防止数据库宕机,当然线程池层面也是可以控制,tomcat中也是可以配置对打请求数量的
总结
1、无论是什么限流算法,目的都是为了保证大部分流量的正常可用,而牺牲掉了少部分流量,这是合理的,如果因为极少部分流量导致系统达到极限而挂掉,得不偿失。
2、在高并发下考虑线程的安全性的前提下是服务可用这样在考虑线程安全才是有意义的,否则将毫无意义
3、限流的应用场景
1、单机应用限流主要针对的是防止用户访问我们的系统流量过大导致我们的系统崩溃,一般而言面对不是特别高的流量单机应用限流已经够用了。
2、分布式限流主要针对的是我们调用第三方的服务接口,当我们流量较大时并且需要调用第三方的接口时(如:短信服务)我们不能把我们的流量全都堆积到第三方应用上,那样有可能会把他们系统弄崩溃,或者是如果他们有限流策略了会把我们的应用加入到黑名单中,所以我们就需要使用分布式限流策略把流量按一定速率引流到他们系统之上。4、限流的动态规则
动态规则:比如限流的QPS我们希望可以动态修改,限流的功能可以随时开启、关闭,限流的规则可以跟随业务进行动态变更等。我们可以在配置文件中加入开关,限流qps数量,再代码中判断这些操作来达到动态限流的目的
降级
什么是服务降级
服务降级,就是对不怎么重要的服务进行低优先级的处理。说白了,就是尽可能的把系统资源让给优先级高的服务。资源有限,而请求是无限的。
降级手段
-
自动降级
Hystrix服务熔断
如:springcloud中的Hystrix
概念跟交易市场上的止损止盈很相似
1、超时降级:主要配置好超时时间和超时重试次数和机制,并使用异步机制探测回复情况
2、比如要调用的远程服务挂掉了(网络故障、DNS故障、http服务返回错误的状态码、rpc服务抛出异常),则可以直接降级。降级后的处理方案有:默认值(比如库存服务挂了,返回默认现货)、兜底数据(比如广告挂了,返回提前准备好的一些静态页面)、缓存(之前暂存的一些缓存数据)人工降级
限流降级
当我们去秒杀或者抢购一些限购商品时,此时可能会因为访问量太大而导致系统崩溃,此时开发者会使用限流来进行限制访问量,当达到限流阀值,后续请求会被降级;降级后的处理方案可以是:排队页面(将用户导流到排队页面等一会重试)、无货(直接告知用户没货了)、错误页(如活动太火爆了,稍后重试)。
拒绝服务
拒绝服务:判断应用来源,高峰时段拒绝低优先级应用的服务请求,保证核心应用正常工作,避免同时涌入过多的请求,这在电商秒杀时用的特别多。
可以通过Nginx把一些恶意请求加入黑名单过滤
关闭服务
关闭服务:如淘宝每年双11时候都会关闭如评价、确定收货等一些与下单核心业务无关的服务,以保证用户下单支付正常,因为一台服务器上一般可能会部署多个微服务应用,如果关闭了一些不重要的那么系统资源就会节省出来给核心服务去用
服务熔断和服务降级比较
相同点
1、目的很一致,都是从可用性可靠性着想,为防止系统的整体缓慢甚至崩溃,采用的技术手段;
2、最终表现类似,对于两者来说,最终让用户体验到的是某些功能暂时不可达或不可用;
3、粒度一般都是服务级别,当然,业界也有不少更细粒度的做法,比如做到数据持久层(允许查询,不允许增删改);
不同点
1、触发原因不太一样,服务熔断一般是某个服务(下游服务)故障引起,而服务降级一般是从整体负荷考虑;
2、管理目标的层次不太一样,熔断其实是一个框架级的处理,每个微服务都需要(无层级之分),而降级一般需要对业务有层级之分(比如降级一般是从最外围服务开始)
3、实现方式不太一样