Presto coordinator的CPU持续上涨,原因竟然是这样
问题背景
之前介绍过presto的架构, coordinator是Presto架构中负责调度的master节点。在实际部署中,为了减少该节点的负载,指定node-scheduler.include-coordinator=false,避免把计算任务调度到coordinator节点上。
由于Presto进程是常驻进程,而且需要实时的提供在线服务。通常只有在需要升级时,才会通过热升级手段重启进程。于是我们在一个大集群上发现了这个现象,coordinator的CPU随着时间不短增长。最高达到了3000%+ 。见下图是连续一个月的持续上涨。

如果任由CPU这样上涨下去,整个集群将不可控,也会影响计算能力。于是我开始了一系列的调查。
是json的原因吗?
首先,通过jstack命令打印Presto进程的栈。在栈中最常见的调用栈,是json的反序列化操作。
at com.fasterxml.jackson.core.json.UTF8StreamJsonParser.parseMediumName2(UTF8StreamJsonParser.java:1836)
at com.fasterxml.jackson.core.json.UTF8StreamJsonParser.parseMediumName(UTF8StreamJsonParser.java:1793)
at com.fasterxml.jackson.core.json.UTF8StreamJsonParser._parseName(UTF8StreamJsonParser.java:1728)
at com.fasterxml.jackson.core.json.UTF8StreamJsonParser.nextToken(UTF8StreamJsonParser.java:776)
at com.fasterxml.jackson.databind.deser.BeanDeserializer._deserializeUsingPropertyBased(BeanDeserializer.java:389)
at com.fasterxml.jackson.databind.deser.BeanDeserializerBase.deserializeFromObjectUsingNonDefault(BeanDeserializerBase.java:1194)
at com.fasterxml.jackson.databind.deser.BeanDeserializer.deserializeFromObject(BeanDeserializer.java:314)
at com.fasterxml.jackson.databind.deser.BeanDeserializer.deserialize(BeanDeserializer.java:148)
at com.fasterxml.jackson.databind.ObjectMapper._readMapAndClose(ObjectMapper.java:3789)
at com.fasterxml.jackson.databind.ObjectMapper.readValue(ObjectMapper.java:2950)
at io.airlift.json.JsonCodec.fromJson(JsonCodec.java:198)
at io.airlift.http.client.FullJsonResponseHandler$JsonResponse.(FullJsonResponseHandler.java:118)
at io.airlift.http.client.FullJsonResponseHandler.handle(FullJsonResponseHandler.java:68)
at io.airlift.http.client.FullJsonResponseHandler.handle(FullJsonResponseHandler.java:37)
at io.airlift.http.client.jetty.JettyHttpClient$JettyResponseFuture.processResponse(JettyHttpClient.java:857)
at io.airlift.http.client.jetty.JettyHttpClient$JettyResponseFuture.completed(JettyHttpClient.java:834)
at io.airlift.http.client.jetty.JettyHttpClient$BufferingResponseListener.onComplete(JettyHttpClient.java:1119)
这个栈是一个http请求的callback,在callback中把response把json反序列化成对象。http的callback线程时包括了200个线程,而我经常能在stack中看到超过180个线程在做json反序列化。从栈总看不出是属于什么http请求。但是我们能从代码中找到coordinator发出的这几类请求。

- task任务状态的fetcher,循环的获取task的状态,直到task结束。这其中其中有两类fetch操作:
- 一个获取taskStatus,只包含task状态,循环获取,前一次获取结束后,立马启动下一次
- 一个获取taskInfo。包含task的详细信息,每3秒获取一次。
- Memory管理,coordinator定期向每台机器获取机器的内存使用状况。
- fail detect 请求有两类:
- 一类是head请求,没有response
- 另一类是/v1/info/state请求,是worker的状态,返回类似于"ACTIVE"或者"SHUTDOWN"之类的状态。
由于内存同步和心跳检查是跟机器数据相关,而task同步则跟query数目相关。于是我怀疑是同时运行的query太多,有1000多个query在同时运行,每个query生成上百个task。 coordinator每分钟要发起几十万次读取task状态的请求。jackson库的反序列化效率不高,导致coordinator的CPU很高。 这可以解释CPU高的原因,但不能解释CPU持续上涨的原因。不管怎么样,我还是决定把jackson改成性能更佳的fastjson。
改成fastjson上线后,过段时间发现,CPU仍然在缓慢的持续上涨,不得不再重新寻找新的证据。
是不停的分配新的线程吗?
我们在jstack栈中,能清楚地看到很多线程同时在做json反序列化操作。证明是和json反序列化相关的操作。于是再去阅读源码。发现task status fetcher使用的线程池是一个可变的线程池newCachedThreadPool。
具体操作是:任何请求,都是放入队列中,然后由线程池处理。如果队列满,则线程池会新分配一个线程。
于是我怀疑是负载太高,导致不停的分配新的线程,于是CPU越来越高。怎么解决这个问题?我改造了coordinator,由原来的单节点,变成了多节点,以均分coordinator的压力。
把coordinator改造成分布式能解决问题吗?
Presto原生的coordinator由于依赖单节点进行内存监控,如果强行部署成多coordinator的话,会造成内存管理的混乱,有可能让某些大query死锁。因此改造成分布式还颇费一番功夫。我会另起一个话题,讲述如何把coordinator改造成分布式。
简单的说,改造完成后,有3个coordinator。原来的coordinator,负责内存管理和worker failover管理,同时处理1/3的query。而另外两个coordinator,只分别负责管理另外1/3的query。同时把内存管理的心跳间隔调整到了5s。
过了一段时间,发现了新的情况。中心coordinator的CPU仍然在缓慢持续上涨,但是CPU并不是一直很高,而是每隔5s飙升一次。新增的两个coordinator则没有变化。于是我从所有的配置中找跟5s相关的参数,从这里开始意思到似乎和内存管理的心跳有关。
从jstack能看到跟json反序列化有关, 内存管理的http response也需要反序列化json。虽然之前把jackson改造成了fastjson,但只是改造了task心跳部分,没有改造内存管理部分。
coordinator每5s向每个worker发送一次请求,获取worker的内存使用,这个请求量是恒定的。理论上,除非我们增加机器,负载才会增加。于是我去检查了presto的http-request.log。 我把日志采集到阿里云日志服务,通过日志分析,检查http请求的变化趋势。
v1/memory | select date_trunc('day',__time__) as t, count(1) as pv, sum(response_size) as res from log group by t order by t
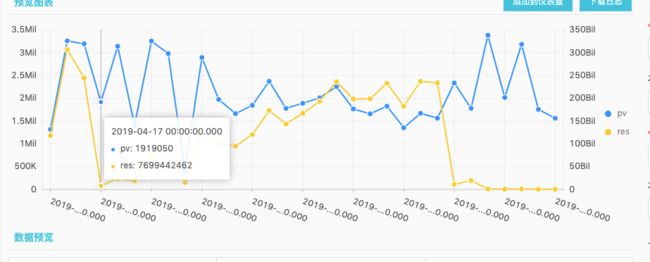
左Y轴是PV,右Y轴是response size的一天累加值。我们可以看到PV基本上没有大的变化。而response size则不断增长。20天内从最低7.6G/day增长到了237G/day。平均每个response达到149k。 这个截图是我写文章时截取的。在当时调查问题时,看到了600k的response。
response增加 -> json反序列化负载增加 -> CPU不断增加。看起来符合逻辑,接下来只有去找为什么response不断增加了。
tcp抓包
为了查看response这么大的原因,我用tcpdump抓取presto的流量。
sudo tcpdump port 10000 -s 0 -w /tmp/netstat
在/v1/memory的响应结果中,会包含general , reserved, 和system 三个pool分别总的大小以及使用大小,和目前占用对应内存池的queryId。结构是这样:
{
"totalNodeMemory": "12884901888B",
"pools": {
"reserved": {
"maxBytes": 3221225472,
"freeBytes": 3221225472,
"queryMemoryReservations": {
}
},
"general": {
"maxBytes": 9663676416,
"freeBytes": 9663676416,
"queryMemoryReservations": {
}
},
"system": {
"maxBytes": 8589934592,
"freeBytes": 8589934592,
"queryMemoryReservations": {
"20190509_113603_03920_25e2h",
"20190509_113608_02758_rdy5b",
...
...
}
}
}
}
其中system -> queryMemoryReservations 这个节点下的内容非常的多,甚至包含几天前的queryId。这意味着某些query占用了system内存池,结束后没有正常释放。接下来就需要查找什么地方存在内存泄露。
查找内存泄漏点
query使用的内存,都会记录在context中,因此我专门写了个程序,向coordinator轮训已经完成的query,获取这些query的描述信息。查看到底是哪个环节的内存使用有问题。
"tasks" : [ {
"stats" : {
"systemMemoryReservation" : "712B",
"pipelines" : [ {
"systemMemoryReservation" : "712B",
"operatorSummaries" : [ {
"systemMemoryReservation" : "0B",
抓取到的多个query的stat信息,都具备相同的特征:
- 某一个task的systemMemoryReservation 不为0。
- task的第一层pipeline不为0。
- pipeline的Operator都是ExchangeOperator和LocalExchangeSinkOperator,但是operator内部的systemMeoryReservation为0。
system内存是在计算过程中,使用的系统内存,例如两个worker之间传递数据,使用的就是system mem pool
Operator信息表明,这个节点是从前一层节点接收数据,放在内存中,供下层pipeline计算。

task -> pipeline -> driver -> operator 构成了一层层结构。由于数据显示pipeline这一层发生了泄露,我只好去看pipeline分配内存的逻辑。
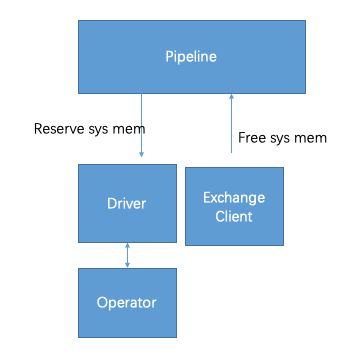
Driver和ExchangeClient在分配内存时,都会调用Pipeline的内存分配逻辑。由于数据显示跟Exchange有关,于是我重点检查了这ExchangeOperator分配内存的逻辑,初看之下,每一层都能做到自平衡,也就是在某一层结束的时候,调用close,自己把尚未释放的内存释放掉。
但是,我也发现了在多线程场景下,由于执行时序不同,会导致出现内存泄露情况。
多线程时序问题
在ExchangeClient中,就存在多种场景。
第一种场景,ExchangeClient是一个生产者和消费者模型,后台线程从远端拿到数据后,由callback线程把数据放入队列,然后才分配内存。 消费者线程从队列中poll到数据后,再释放内存。

假如事件发生的顺序是这样的 P1 C1 C2 P2 , 那么会先释放内存,在C2释放内存时,由于出错而分配失败。接下来在P2再去分配内存就会出错。确保不会出错的顺序是把P1和P2对调顺序。
如果上边的假设成立,那么会在日志中看到tried to free more memory than is reserved的错误。没有从日志中发现上边的错误,于是这种假设被排除了。
第二种场景, C2在释放内存是,会先判断closed变量。如果生产者在C2之前就设置了closed变量,那么就不会进入释放的逻辑。我加了一些日志,证明发生内存泄露时,closed变量确实被设置了。
设置closed变量的方式如下代码,在代码中只设置了closed变量,而没有做内存清理:
if (!closed.get() && pageBuffer.peek() == NO_MORE_PAGES) {
closed.set(true);
}
由于我使用的presto代码比较老,是176版本,和master head版本进行对比,发现最新代码已经改成了close(), 调用close()函数,会提前清理内存,能够避免内存泄露的问题。
git blame的结果:
e3535bbfeca (Dain Sundstrom 2017-02-24 10:04:37 -0800 289) close();
根据commit id找到对应的信息:https://github.com/prestodb/presto/commit/e3535bbfeca

内存泄露的原因已经解决了,我用的版本已经太老了。但是由于我对presto内核做了很多改动,想要merge到HEAD版本恐怕要花费不少时间。
总结
在ExchangeClient中,向上游节点拉取数据时,有一定概率导致内存泄露,上游节点越多,概率越大。
当内存发生泄露时,内存池忠实的记录了每一个queryId。这导致随着时间推移,queryId的list越来越多。
coordinator会定时向每台机器获取内存池的使用情况。因此response越来越大,而json反序列化的CPU使用率越来越高,几乎占满了http callback的线程池。最终反映到监控图上,就是coordinator随着时间推移,CPU Usage直线上涨。
One More Thing
把ExchangeClient内存泄露的问题解决后,再去验证。由ExchangeClient造成的内存泄露已经解决了,但是发现ScanFilterAndProjectOperator在很小的场景下,会出现内存泄露。这是一个SourceOperator的派生类,会调用plugin实现的ConnectorSource,方便ConnectorSource使用系统内存。内存泄露的原因还待分析。
个人博客地址