scrapyd部署scrapy项目及定时启动,SpiderKeeper(爬虫监控)
scrapyd部署scrapy项目
安装scrapyd 和scrapyd-client
pip install scrapyd
pip install scrapyd-client
发布项目
首先切换到项目的目录,scrapy.cfg记录了项目的配置信息
├── scrapy.cfg #项目配置目录
└── Test
├── __init__.py
├── __init__.pyc
├── items.py
├── middlewares.py
├── pipelines.py
├── settings.py
├── settings.pyc
└── spiders
├── __init__.py
└── __init__.pyc
scrapy.cfg的内容
[settings]
default = Test.settings
[deploy:Myploy]#发布名称
url = http://localhost:6800/ #项目发布到那个地址
project = Test#项目名称
接下来写一个简单的爬虫,爬取scrapy首页标题
#Spd.py
import scrapy
import logging
class TestSpider(scrapy.Spider):
name = "spd"#爬虫名称,调度的时候要用到
logger = logging.getLogger('Mylogger')
start_urls = ['https://scrapy.org/doc/']
def parse(self,response):
title = response.xpath('//title//text()')
self.logger.info(title)
项目结构:
├── scrapy.cfg
└── Test
├── __init__.py
├── __init__.pyc
├── items.py
├── middlewares.py
├── pipelines.py
├── settings.py
├── settings.pyc
└── spiders
├── __init__.py
├── __init__.pyc
└── Spd.py
要发布项目,首先要启动scrapyd,直接在命令行输入scrapyd,成功得到类似如下输出
2016-12-21 14:51:31+0800 [-] Log opened.
2016-12-21 14:51:31+0800 [-] twistd 16.0.0 (/usr/bin/python 2.7.12) starting up.
2016-12-21 14:51:31+0800 [-] reactor class: twisted.internet.epollreactor.EPollReactor.
2016-12-21 14:51:31+0800 [-] Site starting on 6800
2016-12-21 14:51:31+0800 [-] Starting factory
2016-12-21 14:51:31+0800 [Launcher] Scrapyd 1.1.1 started: max_proc=32, runner='scrapyd.runner'
发布项目
scrapyd-deploy Myploy -p Test #在scrapy.cfg文件有配置
Packing version 1482303178
Deploying to project "Test" in http://localhost:6800/addversion.json
Server response (200):
{"status": "ok", "project": "Test", "version": "1482303178", "spiders": 1, "node_name": "tozo-CW65S"}
现在只是将项目发布到目标地址,但是没有调度爬虫,调度爬虫需要用到curl命令,在http://localhost:6800有提示如下:
curl http://localhost:6800/schedule.json -d project=default -d spider=somespider
只需要改动一下即可
curl http://localhost:6800/schedule.json -d project=Test -d spider=spd
#输出
{"status": "ok", "jobid": "bd12faeac74a11e690de80fa5b1efd50", "node_name": "tozo-CW65S"}
然后即可在http://127.0.0.1:6800/jobs查看调度结果了
windows部署SpiderKeeper(爬虫监控)
第一步:
mkvirtualenv 创建虚拟环境
第二步:
- workon spiderkeeper (本人创建的虚拟环境spiderkeeper)
- pip install spiderkeeper
- pip install scrapy
- pip install scrapy_redis
- pip install scrapyd
- pip install scrapy_client
第三步:
先进入虚拟环境,直接在任意目录下命令行输入spiderkeeper即可运行spiderkeeeper
第四步:
使用scrapyd打包你的项目生成.egg文件,以便后面传到spiderkeeper上面
python "C:\Users\admin\workspace\pc\Lib\site-packages\scrapyd-client\scrapyd-deploy" --build-egg news.egg
![]()
这里写图片描述
第五步:
在项目目录下启动scrapyd(注意,必须现在项目目录下的scrapy.cfg中开启url这个选项,默认是注释状态,不生效)
第六步:
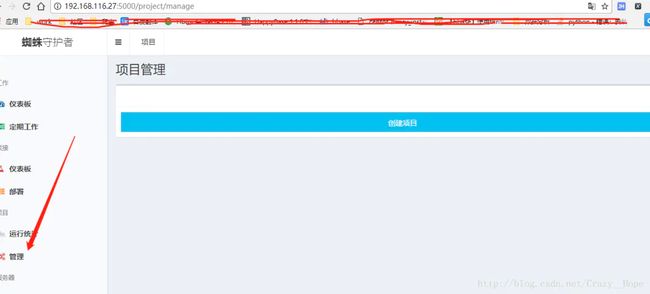
在浏览器访问127.0.0.1:5000,创建项目
这里写图片描述
点击创建项目,项目名称自己随意设置
第七步:
上传刚才生成的egg文件
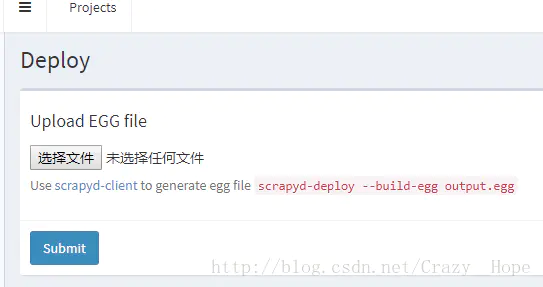
这里写图片描述
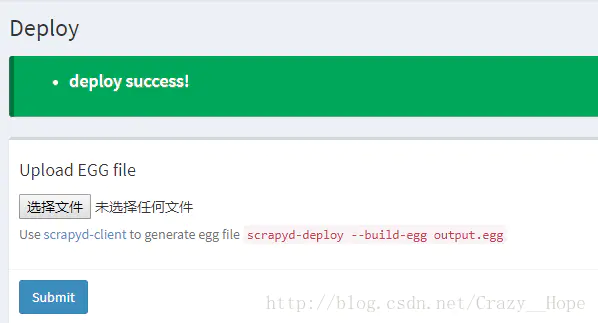
这里写图片描述
上传成功
第八步:
点击仪表盘,添加一个任务
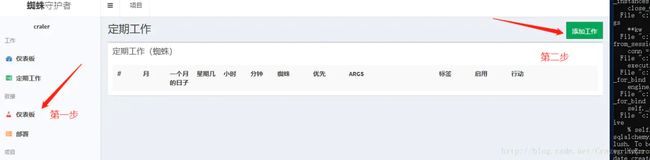
这里写图片描述
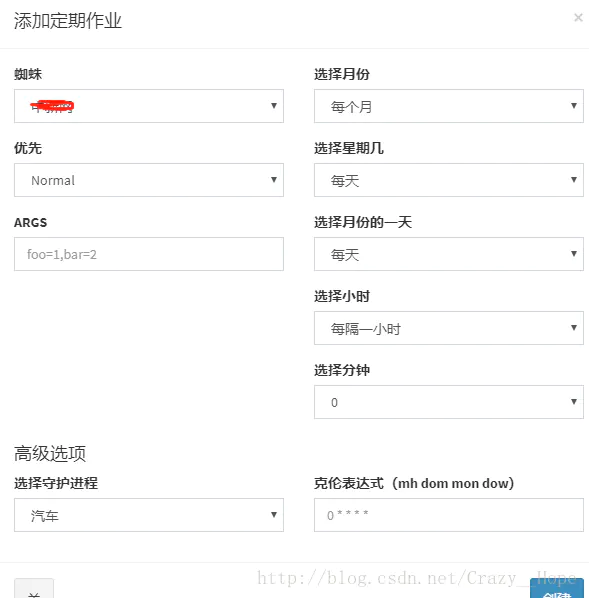
这里写图片描述
spiderkeeper一大优点就是计划任务做的很好,帮助我们减少了一些工作。
这里计划任务根据自己需求设置,设置完点击创建即可
第九步:
设置完成点击运行即可,如果你设置错了,也可以选择移除它。
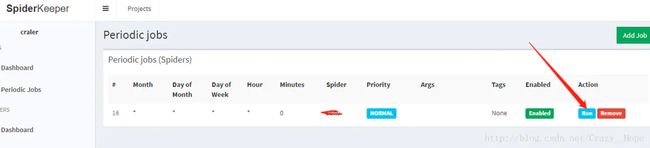
这里写图片描述
第十步:
部署完成,回到仪表盘看下自己的爬虫执行状态。
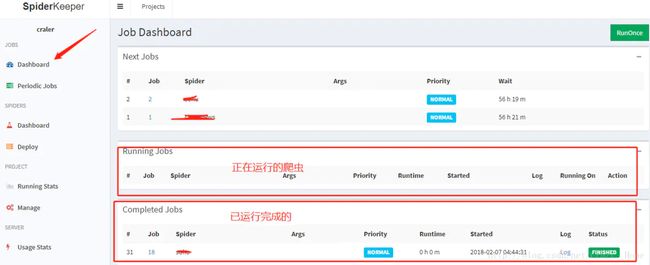
这里写图片描述
不想运行了也可以点击结束爬虫,需要注意的是,一个爬虫结束后,需要在进行添加一次任务。spiderkeeper封装了scrapyd的log接口,我们可以直接点击log查看爬虫的异常信息。
扩展 如果想把监控部署在网络上,项目目录下scrapy.cfg中的url需要配置成0.0.0.0,设置完请重启scrapyd。