性能调优及CPU使用过高代码定位
1.性能优化的几个维度
1.1 CPU
1.1.1 命令 vmstat
vmstat命令是最常见的Linux/Unix监控工具,可以展现给定时间间隔的服务器的状态值,包括服务器的CPU使用率,内存使用,虚拟内存 交换情况,IO读写情况。相比top,通过vmstat可以看到整个机器的 CPU,内存,IO的使用情况,而不是单单看到各个进程的CPU使用率和内存使用率。

2表示每个两秒采集一次服务器状态,1表示只采集一次。
参数详解(https://blog.nbhao.org/1925.html)
Linux 内存监控vmstat命令输出分成六个部分:
(1)进程procs:
r:在运行队列中等待的进程数 。
b:在等待io的进程数 。
(2)Linux 内存监控内存memoy:
swpd:现时可用的交换内存(单位KB)。
free:空闲的内存(单位KB)。
buff: 缓冲去中的内存数(单位:KB)。
cache:被用来做为高速缓存的内存数(单位:KB)。
(3) Linux 内存监控swap交换页面
si: 从磁盘交换到内存的交换页数量,单位:KB/秒。
so: 从内存交换到磁盘的交换页数量,单位:KB/秒。
(4)Linux 内存监控 io块设备:
bi: 发送到块设备的块数,单位:块/秒。
bo: 从块设备接收到的块数,单位:块/秒。
(5)Linux 内存监控system系统:
in: 每秒的中断数,包括时钟中断。
cs: 每秒的环境(上下文)转换次数。
(6)Linux 内存监控cpu中央处理器:
cs:用户进程使用的时间 。以百分比表示。
sy:系统进程使用的时间。 以百分比表示。
id:中央处理器的空闲时间 。以百分比表示。首先检查 cpu,cpu 使用率要提升而不是降低,CPU 空闲并不一定是没事做,也有可能是锁或者外部资源瓶颈。
1.1.2 命令 Top
top命令是Linux下常用的性能分析工具,能够实时显示系统中各个进程的资源占用状况,类似于Windows的任务管理器。
参数详解(https://www.cnblogs.com/sunshuhai/p/6250514.html)
统计信息区前五行是系统整体的统计信息。
第一行是任务队列信息,同 uptime 命令的执行结果。其内容如下:
01:06:48 当前时间
up 1:22 系统运行时间,格式为时:分
1 user 当前登录用户数
load average: 0.06, 0.60, 0.48 系统负载,即任务队列的平均长度。三个数值分别为 1分钟、5分钟、15分钟前到现在的平均值。
第二、三行为进程和CPU的信息。当有多个CPU时,这些内容可能会超过两行。内容如下:
total 进程总数
running 正在运行的进程数
sleeping 睡眠的进程数
stopped 停止的进程数
zombie 僵尸进程数
Cpu(s):
0.3% us 用户空间占用CPU百分比
1.0% sy 内核空间占用CPU百分比
0.0% ni 用户进程空间内改变过优先级的进程占用CPU百分比
98.7% id 空闲CPU百分比
0.0% wa 等待输入输出的CPU时间百分比
0.0%hi:硬件CPU中断占用百分比
0.0%si:软中断占用百分比
0.0%st:虚拟机占用百分比
第四,五行为内存信息。内容如下:
Mem:
191272k total 物理内存总量
173656k used 使用的物理内存总量
17616k free 空闲内存总量
22052k buffers 用作内核缓存的内存量
Swap:
192772k total 交换区总量
0k used 使用的交换区总量
192772k free 空闲交换区总量
123988k cached 缓冲的交换区总量,内存中的内容被换出到交换区,而后又被换入到内存,但使用过的交换区尚未被覆盖,该数值即为这些内容已存在于内存中的交换区的大小,相应的内存再次被换出时可不必再对交换区写入。
进程信息区统计信息区域的下方显示了各个进程的详细信息。首先来认识一下各列的含义。
序号 列名 含义
a PID 进程id
b PPID 父进程id
c RUSER Real user name
d UID 进程所有者的用户id
e USER 进程所有者的用户名
f GROUP 进程所有者的组名
g TTY 启动进程的终端名。不是从终端启动的进程则显示为 ?
h PR 优先级
i NI nice值。负值表示高优先级,正值表示低优先级
j P 最后使用的CPU,仅在多CPU环境下有意义
k %CPU 上次更新到现在的CPU时间占用百分比
l TIME 进程使用的CPU时间总计,单位秒
m TIME+ 进程使用的CPU时间总计,单位1/100秒
n %MEM 进程使用的物理内存百分比
o VIRT 进程使用的虚拟内存总量,单位kb。VIRT=SWAP+RES
p SWAP 进程使用的虚拟内存中,被换出的大小,单位kb。
q RES 进程使用的、未被换出的物理内存大小,单位kb。RES=CODE+DATA
r CODE 可执行代码占用的物理内存大小,单位kb
s DATA 可执行代码以外的部分(数据段+栈)占用的物理内存大小,单位kb
t SHR 共享内存大小,单位kb
u nFLT 页面错误次数
v nDRT 最后一次写入到现在,被修改过的页面数。
w S 进程状态(D=不可中断的睡眠状态,R=运行,S=睡眠,T=跟踪/停止,Z=僵尸进程)
x COMMAND 命令名/命令行
y WCHAN 若该进程在睡眠,则显示睡眠中的系统函数名
z Flags 任务标志,参考 sched.h
默认情况下仅显示比较重要的 PID、USER、PR、NI、VIRT、RES、SHR、S、%CPU、%MEM、TIME+、COMMAND 列。可以通过下面的快捷键来更改显示内容。
更改显示内容通过 f 键可以选择显示的内容。按 f 键之后会显示列的列表,按 a-z 即可显示或隐藏对应的列,最后按回车键确定。
按 o 键可以改变列的显示顺序。按小写的 a-z 可以将相应的列向右移动,而大写的 A-Z 可以将相应的列向左移动。最后按回车键确定。
按大写的 F 或 O 键,然后按 a-z 可以将进程按照相应的列进行排序。而大写的 R 键可以将当前的排序倒转。
命令使用
top使用格式
top [-] [d] [p] [q] [c] [C] [S] [s] [n]
参数说明
d 指定每两次屏幕信息刷新之间的时间间隔。当然用户可以使用s交互命令来改变之。
p 通过指定监控进程ID来仅仅监控某个进程的状态。
q 该选项将使top没有任何延迟的进行刷新。如果调用程序有超级用户权限,那么top将以尽可能高的优先级运行。
S 指定累计模式
s 使top命令在安全模式中运行。这将去除交互命令所带来的潜在危险。
i 使top不显示任何闲置或者僵死进程。
c 显示整个命令行而不只是显示命令名
其他实用命令
下面介绍在top命令执行过程中可以使用的一些交互命令。从使用角度来看,熟练的掌握这些命令比掌握选项还重要一些。这些命令都是单字母的,如果在命令行选项中使用了s选项,则可能其中一些命令会被屏蔽掉。
Ctrl+L 擦除并且重写屏幕。
h或者? 显示帮助画面,给出一些简短的命令总结说明。
k 终止一个进程。系统将提示用户输入需要终止的进程PID,以及需要发送给该进程什么样的信号。一般的终止进程可以使用15信号;如果不能正常结束那就使用信号9强制结束该进程。默认值是信号15。在安全模式中此命令被屏蔽。
i 忽略闲置和僵死进程。这是一个开关式命令。
q 退出程序。
r 重新安排一个进程的优先级别。系统提示用户输入需要改变的进程PID以及需要设置的进程优先级值。输入一个正值将使优先级降低,反之则可以使该进程拥有更高的优先权。默认值是10。
S 切换到累计模式。
s 改变两次刷新之间的延迟时间。系统将提示用户输入新的时间,单位为s。如果有小数,就换算成m s。输入0值则系统将不断刷新,默认值是5 s。需要注意的是如果设置太小的时间,很可能会引起不断刷新,从而根本来不及看清显示的情况,而且系统负载也会大大增加。
f或者F 从当前显示中添加或者删除项目。
o或者O 改变显示项目的顺序。
l 切换显示平均负载和启动时间信息。
m 切换显示内存信息。
t 切换显示进程和CPU状态信息。
c 切换显示命令名称和完整命令行。
M 根据驻留内存大小进行排序。
P 根据CPU使用百分比大小进行排序。
T 根据时间/累计时间进行排序。
W 将当前设置写入~/.toprc文件中。这是写top配置文件的推荐方法。
附常用操作:
top //每隔5秒显式所有进程的资源占用情况
top -d 2 //每隔2秒显式所有进程的资源占用情况
top -c //每隔5秒显式进程的资源占用情况,并显示进程的命令行参数(默认只有进程名)
top -p 12345 -p 6789//每隔5秒显示pid是12345和pid是6789的两个进程的资源占用情况
top -d 2 -c -p 123456 //每隔2秒显示pid是12345的进程的资源使用情况,并显式该进程启动的命令行参数
1.2 IO
1.2.1 命令 iostat
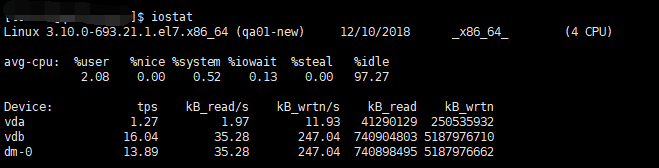
iostat -k 3 5 (以KB为单位,每3秒统计一次,共统计5次)
参数说明:
cpu属性值说明:
%user: CPU处在用户模式下的时间百分比。
%nice: CPU处在带NICE值的用户模式下的时间百分比。
%system: CPU处在系统模式下的时间百分比。
%iowait: CPU等待输入输出完成时间的百分比。
%steal: 管理程序维护另一个虚拟处理器时,虚拟CPU的无意识等待时间百分比。
%idle: CPU空闲时间百分比。
备注:如果%iowait的值过高,表示硬盘存在I/O瓶颈,%idle值高,表示CPU较空闲,如果%idle值高但系统响应慢时,有可能是CPU等待分配内存,此时应加大内存容量。%idle值如果持续低于10,那么系统的CPU处理能力相对较低,表明系统中最需要解决的资源是CPU。
disk属性值说明:
rrqm/s: 每秒进行 merge 的读操作数目。即 rmerge/s
wrqm/s: 每秒进行 merge 的写操作数目。即 wmerge/s
r/s: 每秒完成的读 I/O 设备次数。即 rio/s
w/s: 每秒完成的写 I/O 设备次数。即 wio/s
rsec/s: 每秒读扇区数。即 rsect/s
wsec/s: 每秒写扇区数。即 wsect/s
rkB/s: 每秒读K字节数。是 rsect/s 的一半,因为每扇区大小为512字节。
wkB/s: 每秒写K字节数。是 wsect/s 的一半。
avgrq-sz: 平均每次设备I/O操作的数据大小(扇区)。
avgqu-sz: 平均I/O队列长度。
Await: 平均每次设备I/O操作的等待时间(毫秒)。
Svctm: 平均每次设备I/O操作的服务时间(毫秒)。
%util: 一秒中有百分之多少的时间用于 I/O 操作,即被io消耗的cpu百分比
备注:如果 %util 接近 100%,说明产生的I/O请求太多,I/O系统已经满负荷,该磁盘可能存在瓶颈。如果 svctm 比较接近 await,说明 I/O 几乎没有等待时间;如果 await 远大于 svctm,说明I/O 队列太长,io响应太慢,则需要进行必要优化。如果avgqu-sz比较大,也表示有当量io在等待。
命令格式:
iostat [参数] [时间] [次数]
命令功能:
通过iostat方便查看CPU、网卡、tty设备、磁盘、CD-ROM 等等设备的活动情况, 负载信息。
命令参数:
-c 显示CPU使用情况
-d 显示磁盘使用情况
-k 以 KB 为单位显示
-m 以 M 为单位显示
-N 显示磁盘阵列(LVM)信息
-n 显示NFS 使用情况
-p [磁盘]显示磁盘和分区的情况
-t 显示终端和CPU的信息
-x 显示详细信息
-V 显示版本信息
2 使用实例:
1.3 Memory
1.3.1 命令 free(https://www.jb51.net/article/135410.htm)

用法: free [-bkmotV][-s <间隔秒数>]
补充说明:free指令会显示内存的使用情况,包括实体内存,虚拟的交换文件内存,共享内存区段,以及系统核心使用的缓冲区等。
参 数:
-b 以Byte为单位显示内存使用情况。
-k 以KB为单位显示内存使用情况。
-m 以MB为单位显示内存使用情况。
-o 不显示缓冲区调节列。
-s<间隔秒数> 持续观察内存使用状况。
-t 显示内存总和列。
-V 显示版本信息。
常用操作:
free //以KB为单位,显式系统内存使用情况
free -ml -s 1 //每秒以M为单位,显式系统内存详细使用情况。
free -c 4 -s 2 //为KB为单位,每2秒显式系统内存使用情况,一共显示4次
参数详解
Mem 行(第二行)是内存的使用情况。
Swap 行(第三行)是交换空间的使用情况。
total 列显示系统总的可用物理内存和交换空间大小。
used 列显示已经被使用的物理内存和交换空间。
free 列显示还有多少物理内存和交换空间可用使用。
shared 列显示被共享使用的物理内存大小。
buff/cache 列显示被 buffer 和 cache 使用的物理内存大小。
available 列显示还可以被应用程序使用的物理内存大小。
1.4 Network
命令 nicstat (需要安装)
wget http://sourceforge.net/projects/nicstat/files/nicstat-1.92.tar.gz
tar -zxvf nicstat-1.92.tar.gz sudo vim Makefile
CFLAGS = $(COPT) -m32#将此行修改为如下: CFLAGS = $(COPT)
sudo make -f Makefile install
2.性能术语
吞吐量:对单位时间内完成的工作量的度量
系统吞吐量几个重要参数:QPS(TPS)、并发数、响应时间
QPS(TPS):每秒钟request/事务 数量
QPS:Queries Per Second意思是“每秒查询率”,是一台服务器每秒能够相应的查询次数,是对一个特定的查询服务器在规定时间内所处理流量多少的衡量标准。
TPS:是TransactionsPerSecond的缩写,也就是事务数/秒。它是软件测试结果的测量单位。一个事务是指一个客户机向服务器发送请求然后服务器做出反应的过程。客户机在发送请求时开始计时,收到服务器响应后结束计时,以此来计算使用的时间和完成的事务个数.
并发数: 系统同时处理的request/事务数
平均响应时间: 提交请求和返回该请求的响应之间使用的时间,一般取平均响应时间.
(很多人经常会把并发数和TPS理解混淆)
理解了上面三个要素的意义之后,就能推算出它们之间的关系:
QPS(TPS)= 并发数/平均响应时间
一个系统吞吐量通常由QPS(TPS)、并发数两个因素决定,每套系统这两个值都有一个相对极限值,在应用场景访问压力下,只要某一项达 到系统最高值,系统的吞吐量就上不去了,如果压力继续增大,系统的吞吐量反而会下降,原因是系统超负荷工作,上下文切换、内存等等其它消耗导致系统性能下 降。
平均响应时间越短,系统吞吐量越大;平均响应时间越长,系统吞吐量越小;但是,系统吞吐量越大,未必平均响应时间越短;因为在某些情况(例如,不增加任何硬件配置)吞吐量的增大,有时会把平均响应时间作为牺牲, 来换取一段时间处理更多的请求。
3. CPU 负载高怎么定位:
原理:方法是由线程执行的,线程是在进程下的,找到进程下 cpu 最高的线程就能定位到方法
ps -ef|grep tomcat
查tomcat进程号
3.1 top 找到 CPU 高的进程
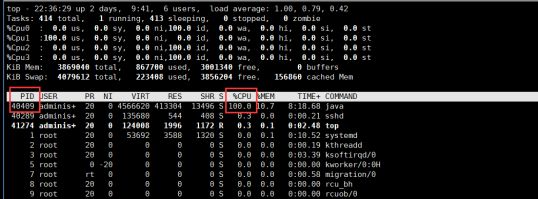
3.2 找到进程中执行最高的线程号
方法一:Shift + H 切换到线程模型 ,此时打开的是线程视图,pid为线程号,找到线程执行 cpu 高的线程号.
方法二: 通过top -Hp 48489可以查看该进程下各个线程的cpu使用情况;
3.3 用jstack pid (进程号)导出线程的 dump日志
方法一:jstack 48489;
方法二:jstack -l
注意:由于jstack.log文件记录的线程ID是16进制,需要将top命令展示的线程号转换为16进制。
把线程号转 16 进制 printf “%x \n” 40437
![]()
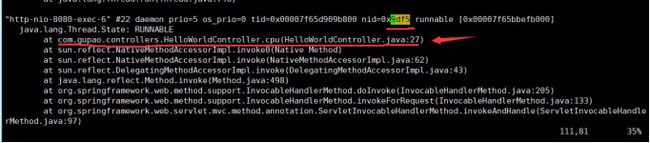
3.4 到刚刚导出的 jvm_listlocks.txt 里面检索定位到定位到问题
3.5 总结
对于jstack做的ThreadDump的栈,可以反映如下信息:
- 如果某个相同的call stack经常出现, 我们有80%的以上的理由确定这个代码存在性能问题(读网络的部分除外);
- 如果相同的call stack出现在同一个线程上(tid)上, 我们很很大理由相信, 这段代码可能存在较多的循环或者死循环;
- 如果某call stack经常出现, 并且里面带有lock,请检查一下这个lock的产生的原因, 可能是全局lock造成了性能问题;
- 在一个不大压力的群集里(w<2), 我们是很少拿到带有业务代码的stack的, 并且一般在一个完整stack中, 最多只有1-2业务代码的stack,
- 如果经常出现, 一定要检查代码, 是否出现性能问题。
- 如果你怀疑有dead lock问题, 那么请把所有的lock id找出来,看看是不是出现重复的lock id。
最后,总结下排查CPU故障的方法和技巧有哪些:
1、top命令:Linux命令。可以查看实时的CPU使用情况。也可以查看最近一段时间的CPU使用情况。
2、PS命令:Linux命令。强大的进程状态监控命令。可以查看进程以及进程中线程的当前CPU使用情况。属于当前状态的采样数据。
3、jstack:Java提供的命令。可以查看某个进程的当前线程栈运行情况。根据这个命令的输出可以定位某个进程的所有线程的当前运行状态、运行代码,以及是否死锁等等。
4、pstack:Linux命令。可以查看某个进程的当前线程栈运行情况。
4. 监控软件
zabbix nagios prometheus
监控资源:zabbix, elk,Prometheus,top
jvm监控工具:jrock, jmap,jprofile