Oracle存储过程处理大批量数据性能测试
通过此次的大批量数据性能测试,还会间接的给大家分享一个知识点,Oracle存储过程如何处理List集合的问题,废话不多说了,老规矩直接上代码!!!
首先要做的,想必大家应该猜到了。。。建表!
create table tab_1
(
id varchar(100) primary key,
name varchar(100),
password varchar(100)
)
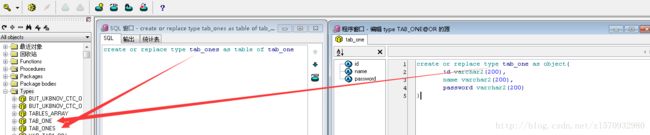
第一步:
create or replace type tab_one as object(
id varchar2(200),
name varchar2(200),
password varchar2(200)
)
第二步:
create or replace type tab_ones as table of tab_one
第三步:
create or replace procedure test7(i_orders in tab_ones)
as
orders tab_one;
begin
FOR idx in i_orders.first..i_orders.count loop
orders:=i_orders(idx);
insert into tab_1
(id,name,password)
values
(orders.id,orders.name,orders.password);
end loop;
exception when others then
raise;
end test7;
测试代码:
public static void main(String[] args) throws SQLException {
Statement stmt = null;
ResultSet rs = null;
Connection conn = null;
try {
Class.forName(driver);
conn = DriverManager.getConnection(url,name,password);
CallableStatement proc = null;
List orderList = new ArrayList();
String date=DateUtils.getDate_time();
System.out.println("开始:"+date);
for(int i=0;i<100000;i++){
System.out.println("第"+i+"个");
orderList.add(new Tab_One_Bean("第"+i+"个","新增用户"+i,i+"@126.com"));
}
StructDescriptor recDesc = StructDescriptor.createDescriptor("TAB_ONE", conn);
//这里注意下TAB_ONE在创建时是小写但编译后在Types显示的是大写的
ArrayList pstruct = new ArrayList();
for (Tab_One_Bean ord:orderList) {
Object[] record = new Object[3];
record[0] = ord.getId();
record[1] = ord.getName();
record[2] = ord.getPassword();
STRUCT item = new STRUCT(recDesc, conn, record);
pstruct.add(item);
}
ArrayDescriptor tabDesc = ArrayDescriptor.createDescriptor("TAB_ONES", conn);
//这里注意下TAB_ONES在创建时是小写但编译后在Types显示的是大写的
ARRAY vArray = new ARRAY(tabDesc, conn, pstruct.toArray());
proc = conn.prepareCall("{call test7(?)}");
proc.setArray(1, vArray);
proc.execute();
conn.commit();
System.out.println("开始:"+date+" 结束:"+DateUtils.getDate_time());
}
catch (SQLException ex2) {
ex2.printStackTrace();
}
catch (Exception ex2) {
ex2.printStackTrace();
}
finally{
try {
if(rs != null){
rs.close();
if(stmt!=null){
stmt.close();
}
if(conn!=null){
conn.close();
}
}
}
catch (SQLException ex1) {
}
}
}
【主意点:】
我这里测试了100000条数据量,运行结果:
...
第99989个
第99990个
第99991个
第99992个
第99993个
第99994个
第99995个
第99996个
第99997个
第99998个
第99999个
开始:2017-09-08 16:18:07 结束:2017-09-08 16:18:18
最快的一次用了9秒!
**继续优化以上代码:修改的代码,直接注释了**
第一步:【建议使用这种方式】
public class Tab_One_Bean1 implements ORAData{
private String id;
private String name;
private String password;
public static final String ORACLE_TYPE_NAME = "TAB_ONE";
protected MutableStruct struct;
static int[] sqlType = { OracleTypes.VARCHAR, OracleTypes.VARCHAR,OracleTypes.VARCHAR };
static ORADataFactory[] factory = new ORADataFactory[sqlType.length];
public Tab_One_Bean1() {
struct = new MutableStruct(new Object[sqlType.length], sqlType, factory);
}
public Tab_One_Bean1(String id,String name,String password){
this();//注意这里的this()必须加上,不加会报错,具体错误看下面截图
this.id=id;
this.name=name;
this.password=password;
}
@Override
public Datum toDatum(Connection conn) throws SQLException {
System.out.println("id:"+this.id+" name:"+this.name+" password: "+this.password);
struct.setAttribute(0, this.id);
struct.setAttribute(1, this.name);
struct.setAttribute(2, this.password);
return struct.toDatum(conn, ORACLE_TYPE_NAME);
}
}
【注意】这里的this()必须加上,不加会报以下错误:
开始:2017-09-08 16:49:29
id:第0个 name:新增用户0 password: 0@126.com
java.lang.NullPointerException
at com.util.oracleutils.Tab_One_Bean1.toDatum(Tab_One_Bean1.java:32)
at oracle.sql.STRUCT.toSTRUCT(STRUCT.java:603)
at oracle.jdbc.oracore.OracleTypeADT.toDatum(OracleTypeADT.java:241)
at oracle.jdbc.oracore.OracleTypeADT.toDatumArray(OracleTypeADT.java:302)
at oracle.jdbc.oracore.OracleTypeUPT.toDatumArray(OracleTypeUPT.java:117)
at oracle.sql.ArrayDescriptor.toOracleArray(ArrayDescriptor.java:1517)
at oracle.sql.ARRAY.(ARRAY.java:117)
at com.util.oracleutils.CallableStatementOracleUtils.main(CallableStatementOracleUtils.java:55) 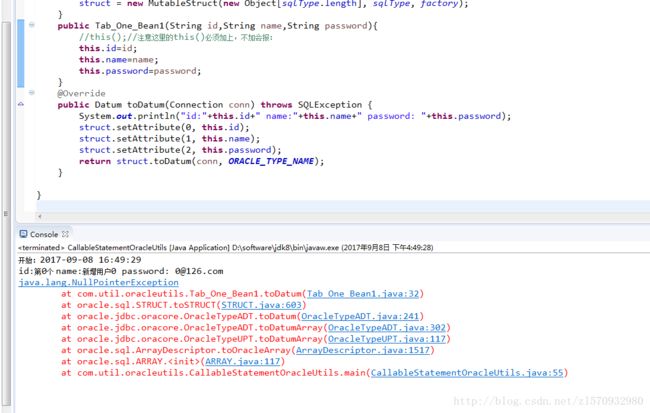
public static void main(String[] args) throws SQLException {
Statement stmt = null;
ResultSet rs = null;
Connection conn = null;
try {
Class.forName(driver);
conn = DriverManager.getConnection(url,name,password);
CallableStatement proc = null;
// List orderList = new ArrayList();
List orderList = new ArrayList();
String date=DateUtils.getDate_time();
System.out.println("开始:"+date);
for(int i=0;i<100000;i++){
// System.out.println("第"+i+"个");
// orderList.add(new Tab_One_Bean("第"+i+"个","新增用户"+i,i+"@126.com"));
orderList.add(new Tab_One_Bean1("第"+i+"个","新增用户"+i,i+"@126.com"));
}
// StructDescriptor recDesc = StructDescriptor.createDescriptor("TAB_ONE", conn); //这里注意下TAB_ONE在创建时是小写但编译后在Types显示的是大写的
// ArrayList pstruct = new ArrayList();
// for (Tab_One_Bean ord:orderList) {
// Object[] record = new Object[3];
// record[0] = ord.getId();
// record[1] = ord.getName();
// record[2] = ord.getPassword();
// STRUCT item = new STRUCT(recDesc, conn, record);
// pstruct.add(item);
// }
ArrayDescriptor tabDesc = ArrayDescriptor.createDescriptor("TAB_ONES", conn);//这里注意下TAB_ONES在创建时是小写但编译后在Types显示的是大写的
//ARRAY vArray = new ARRAY(tabDesc, conn, pstruct.toArray());
ARRAY vArray = new ARRAY(tabDesc, conn, orderList.toArray());
proc = conn.prepareCall("{call test7(?)}");
proc.setArray(1, vArray);
proc.execute();
conn.commit();
System.out.println("开始:"+date+" 结束:"+DateUtils.getDate_time());
}
catch (SQLException ex2) {
ex2.printStackTrace();
}
catch (Exception ex2) {
ex2.printStackTrace();
}
finally{
try {
if(rs != null){
rs.close();
if(stmt!=null){
stmt.close();
}
if(conn!=null){
conn.close();
}
}
}
catch (SQLException ex1) {
}
}
}
继续测试10万条数据,运行结果:
开始:2017-09-08 16:56:32
开始:2017-09-08 16:56:32 结束:2017-09-08 16:56:42
还有一种批量处理的方法进行和存储过程方法对比下哈:
public static void main(String[] args) throws SQLException {
Statement stmt = null;
ResultSet rs = null;
Connection conn = null;
try {
Class.forName(driver);
conn = DriverManager.getConnection(url, name, password);
String date = DateUtils.getDate_time();
System.out.println("开始:" + date);
List lis = new ArrayList<>();
for (int i = 0; i < 10000; i++) {
lis.add("insert into tab_1 (id,name,password)values('第" + i + "位','新增用户" + i + "','" + i + "@126.com')");
}
conn.setAutoCommit(false);
pst = conn.createStatement();
for (int i = 0; i < lis.size(); i++) {
System.out.println("第:" +i);
pst.addBatch(lis.get(i).toString());
}
pst.executeBatch();
conn.commit();
System.out.println("开始:" + date + " 结束:" + DateUtils.getDate_time());
} catch (SQLException ex2) {
ex2.printStackTrace();
} catch (Exception ex2) {
ex2.printStackTrace();
} finally {
try {
if (rs != null) {
rs.close();
if (stmt != null) {
stmt.close();
}
if (conn != null) {
conn.close();
}
}
} catch (SQLException ex1) {
}
}
}
运行结果:
...
第:9990
第:9991
第:9992
第:9993
第:9994
第:9995
第:9996
第:9997
第:9998
第:9999
开始:2017-09-08 17:52:24 结束:2017-09-08 17:53:46
使用addBatch()方法批量处理数据测试10000条数据用时82秒!
存储过程10000条数据用时1秒!!!
存储过程再次测试100000条数据用时8秒!!! 我的技术群这里给大家分享下:472148690 问题可以在群里咨询