【原创】【论文复现】【Matlab】【图像处理】基于竞争性学习的非监督式图像分割(DSRPCL法)
参考文献:
[1]Ma J W, Wang T J. A cost-function approach to rival penalized competitive learning (RCPL) [J]. IEEE Transactions on Systems, Man, and Cybernetics-Part B: Cybernetics, 2006, 36(4): 722-737
[2]数字图像处理. 冈萨雷斯
概述
2006年,Ma等人提出了DSRPCL算法。用户只要适当调整权重指数与学习率,并赋予算法一个大于实际聚类数量的初始聚类数,该算法可以自行迭代出合适的聚类数量。简单地讲,该算法通过获奖惩罚机制,自动地完成图像的聚类分割。
该算法通过将下列目标函数E最小化,从而寻找到最佳的聚类模式:
E = 1 2 ∑ i ∣ ∣ x i − ω c ( i ) ∣ ∣ 2 + 2 P ∑ i , j ≠ c ( i ) ∣ ∣ x i − ω j ∣ ∣ − P E=\frac{1}{2}\sum_{i}||x_{i}-\omega_{c(i)}||^2+\frac{2}{P}\sum_{i,j≠c(i)}||x_i-\omega_j||^{-P} E=21i∑∣∣xi−ωc(i)∣∣2+P2i,j̸=c(i)∑∣∣xi−ωj∣∣−P
其中, x i x_i xi为图像中的某一个像素, ω c ( i ) \omega_{c(i)} ωc(i)为距离该像素最近的聚类中心, ω j \omega_j ωj为某一个聚类中心,P为权重指数。
利用梯度下降法,Ma等人导出了如下聚类中心的更新公式:
Δ ω j = { α ( x i − ω j ) , j = c ( i ) − α ∣ ∣ x i − ω j ∣ ∣ − P − 2 ( x i − ω j ) , o t h e r w i s e \Delta\omega_j=\begin{cases}\alpha(x_i-\omega_j),j=c(i)\\-\alpha||x_i-\omega_j||^{-P-2}(x_i-\omega_j)&,otherwise\end{cases} Δωj={α(xi−ωj),j=c(i)−α∣∣xi−ωj∣∣−P−2(xi−ωj),otherwise
其中 α \alpha α为学习率。
对于所有聚类中心来说,当算法进行某一次迭代,遍历到其中一个像素时,若聚类中心c(i)离该像素最近,即下标为c(i),则通过第一个式子对此聚类中心进行更新,并通过第二个式子对剩下的聚类中心进行更新。通俗的说,就是将离某像素最近的聚类中心拉近,并把剩下的踢开。
上述聚类中心更新公式称为DSRPCL1,使用该法遍历像素时,需要对所有像素的聚类中心进行奖励惩罚,所以目标函数的下降曲线十分光滑,但耗时很长。
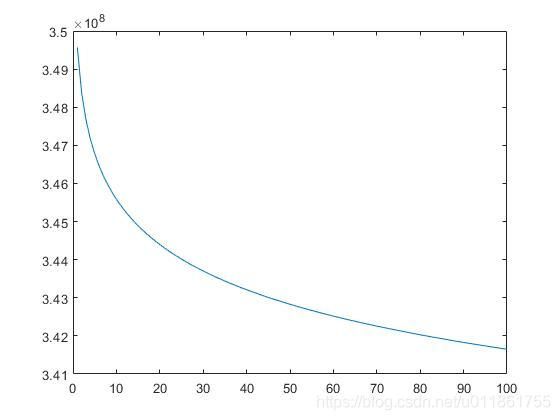
绘制下图耗时1分25秒。
为了提高运算速度,Ma等人提出了改进版本(DSRPCL2):
Δ ω j = { α ( x i − ω j ) , j = c ( i ) − α ∣ ∣ x i − ω j ∣ ∣ − P − 2 ( x i − ω j ) , j = r ( i ) 0 , o t h e r w i s e \Delta\omega_j=\begin{cases}\alpha(x_i-\omega_j),j=c(i)\\-\alpha||x_i-\omega_j||^{-P-2}(x_i-\omega_j)&,j=r(i)\\0,otherwise\end{cases} Δωj=⎩⎪⎨⎪⎧α(xi−ωj),j=c(i)−α∣∣xi−ωj∣∣−P−2(xi−ωj)0,otherwise,j=r(i)
该改进版本仅仅惩罚了竞争对手中的第一个聚类中心,保持其他竞争对手不变。
同样,由于在迭代中没有引入随机,下降曲线依然十分光滑。
绘制下图用时1分05秒,缩短了20秒。

新方法确实提高了运算速度,但是我们知道,光滑的曲线是通过在每一次迭代中遍历所有像素得到的,这就使得运算速度存在继续提高的空间。
在此,通过在每一次迭代中随机选取一个像素点进行聚类中心的更新,得到了下图的目标函数曲线。

注意,由于引入了随机取像素的机制,所以目标函数曲线产生了大量的不规则起伏,而且由于迭代次数未设置得足够大,也会导致每一次运行算法,得到不同的分割结果,但绘制此图只花费了11秒。
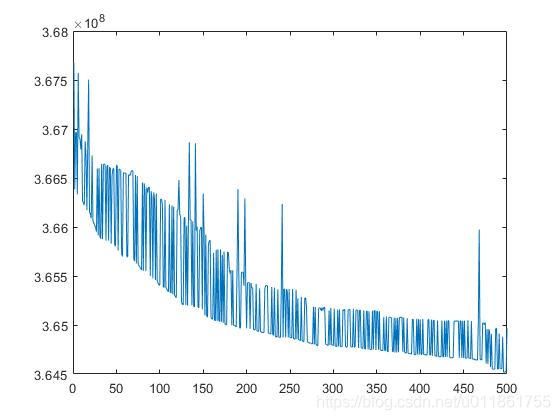
我们增加迭代次数到500,可以得到如下的目标函数下降图,可以看出目标函数整体上仍然是在不断减小的。
下面展示该方法的分割效果:
设置权重指数P=0.01,学习率 α \alpha α=0.001,迭代500次,初始聚类数6


设置权重指数P=0.01,学习率 α \alpha α=0.001,迭代次数50次,初始聚类数7


代码:
f=imread('(你想测试的图像)');
% f=rgb2gray(f);%如果输入图像是彩色的,则执行此步
f=double(f);
f=f/255;
figure(1),imshow(f);
tic;
%输入图像的长宽
[row,col]=size(f);
%将所有像素展开
all_pixel=reshape(f,row*col,1);
%指定初始聚类数
cluster_num=7;
%指定权重指数
P=0.05;
%制定学习率
learning_rate=0.001;
%设置最大迭代次数
iter_max=100;
%保存所有能量函数值
E_all=zeros(0,1);
% 创建初始聚类中心
center=rand(cluster_num,1);
%进行聚类中心的更新
for i=1:iter_max
%随机取一个像素,进行聚类中心的竞争惩罚机制
pixel_indice_random=randi([1,row*col],1);
random_pixel=all_pixel(pixel_indice_random);
%获得距离像素最近的聚类中心的序号
distance=abs(random_pixel-center);
[~,indice]=sort(distance);
for m=1:cluster_num
if m==indice(1)
%对距离像素最近的聚类中心进行奖励
center(m)=center(m)+learning_rate*(random_pixel-center(m));
break;
end
end
%对剩下聚类中心中的第一个进行惩罚
m=indice(2);
center(m)=center(m)-learning_rate*abs(random_pixel-center(m))^(-P-2)*(random_pixel-center(m));
%求能量函数
dist1=abs(all_pixel-center(indice(1)));
E_part1=0.5*(dist1'*dist1);
%去除离像素点最近的聚类中心
if indice(1)~=1
center2=[center(1:indice(1)-1);center(indice(1)+1:end)];
else
center2=center(indice(1)+1:end);
end
%求所有像素距离其他聚类中心的距离之和
dist2=abs(all_pixel*ones(1,cluster_num-1)-(center2*ones(1,row*col))').^(-P);
E_part2=2/P*sum(dist2,'all');
E_all=[E_all;E_part1+E_part2];
fprintf('第%d次迭代,E=%f\n',i,E_all(i));
end
%分割图像
distance_result=abs(all_pixel*ones(1,cluster_num)-(center*ones(1,row*col))');
[~,result_indice]=min(distance_result,[],2);
color_level=rand(cluster_num,3);
result=zeros(row*col,1,3);
for i=1:row*col
result(i,1,:)=color_level(result_indice(i),:);
end
result=reshape(result,row,col,3);
figure(2),imshow(result);
figure(3),plot(E_all);
toc;