尝试复现论文:RePr: Improved Training of Convolutional Filters
尝试复现RePr
我的复现地址:https://github.com/SweetWind1996/implementation-of-RePr
论文看了好几遍,也看了一些讨论,讨论在:https://www.reddit.com/r/MachineLearning/comments/ayh2hf/r_repr_improved_training_of_convolutional_filters/eozi40e/
参考了这个复现:https://github.com/siahuat0727/RePr/blob/master/main.py
最后的结果就是:没达到论文效果,但是有点提升。
2020.7.8更新:因为一直没有做出类似论文中的效果,所以这个复现又进行了尝试。回头重新去看了评论和siahuat0727的复现代码,最后修改了原有代码,使用了学习率衰减和权重衰减,最终取得了一点效果,聊以慰藉我之前的复现过程。本次更新是最后一次更新。
上次复现方式:上次复现使用的是keras,这次使用siahuat0727的代码,并稍作了修改。keras代码的冗余度较高,且没有对剪裁filters停止梯度更新而是在每个batch重新置0.siahuat0727的代码在训练过程中是停止pruned filters梯度更新的。
关于QR分解求解正交向量的问题:一个矩阵进行QR分解后,Q是正交方正,R是上三角矩阵。对于列满秩的矩阵A,A=QR后R存在零行。又因为Q.T=Q=Q逆,所以Q.TA=R,Q.T中的最后n行与A乘得到R中的最后n行,R中最后n行为零。所以取出最后n行的向量就是重新初始化的向量。
注:之前keras的代码就不删除了,我将修改后的siahuat0727的代码放在最前面,只放置修改过的部分,其他代码请到siahuat0727的github上查看。https://github.com/siahuat0727/RePr/blob/master/main.py
有任何问题或者建议请在下面回复,谢谢!
这里画图的部分我用的是visdom。
'''Train CIFAR10 with PyTorch.'''
from __future__ import print_function
import math
import visdom
import argparse
import time
import datetime
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.backends.cudnn as cudnn
import torchvision
import torchvision.transforms as transforms
import numpy as np
import matplotlib.pyplot as plt
from matplotlib.colors import ListedColormap
from models import Vanilla
from average_meter import AverageMeter
from utils import qr_null, test_filter_sparsity, accuracy
# from tensorboardX import SummaryWriter
# import tensorflow as tf
parser = argparse.ArgumentParser(description='PyTorch CIFAR10 Training',
formatter_class=argparse.ArgumentDefaultsHelpFormatter)
parser.add_argument('--lr', type=float, default=0.01, help="learning rate")
parser.add_argument('--repr', action='store_true', help="whether to use RePr training scheme")
parser.add_argument('--S1', type=int, default=20, help="S1 epochs for RePr")
parser.add_argument('--S2', type=int, default=10, help="S2 epochs for RePr")
parser.add_argument('--epochs', type=int, default=100, help="total epochs for training")
parser.add_argument('--workers', type=int, default=0, help="number of worker to load data")
parser.add_argument('--print_freq', type=int, default=50, help="print frequency")
parser.add_argument('--gpu', type=int, default=0, help="gpu id")
parser.add_argument('--save_model', type=str, default='best.pt', help="path to save model")
parser.add_argument('--prune_ratio', type=float, default=0.3, help="prune ratio")
parser.add_argument('--comment', type=str, default='', help="tag for tensorboardX event name")
parser.add_argument('--zero_init', action='store_true', help="whether to initialize with zero")
def train(train_loader, criterion, optimizer, epoch, model, viz, train_loss_win, train_acc_win, mask, args, conv_weights):
batch_time = AverageMeter()
data_time = AverageMeter()
losses = AverageMeter()
top1 = AverageMeter()
# switch to train mode
model.train()
end = time.time() # 返回当前时间戳
for i, (data, target) in enumerate(train_loader):
# measure data loading time
data_time.update(time.time() - end)
if args.gpu is not None: # TODO None?
data = data.cuda(args.gpu, non_blocking=True) # 将数据放在gpu上,非阻塞
target = target.cuda(args.gpu, non_blocking=True)
output = model(data)
loss = criterion(output, target)
acc1, _ = accuracy(output, target, topk=(1, 5))
losses.update(loss.item(), data.size(0))
top1.update(acc1[0], data.size(0))
optimizer.zero_grad()
loss.backward()
S1, S2 = args.S1, args.S2
if args.repr and any(s1 <= epoch < s1+S2 for s1 in range(S1, args.epochs, S1+S2)): # 运行到指定epoch
if i == 0:
print('freeze for this epoch')
with torch.no_grad():
for name, W in conv_weights:
W.grad[mask[name]] = 0 # 裁剪filter停止梯度更新
optimizer.step()
# measure elapsed time
batch_time.update(time.time() - end)
if i % args.print_freq == 0:
print('Epoch: [{0}][{1}/{2}]\t'
'Time {batch_time.val:.3f} ({batch_time.avg:.3f})\t'
'Data {data_time.val:.3f} ({data_time.avg:.3f})\t'
'Loss {loss.val:.4f} ({loss.avg:.4f})\t'
'Acc@1 {top1.val:.3f} ({top1.avg:.3f})\t'
'LR {lr:.3f}\t'
.format(
epoch, i, len(train_loader), batch_time=batch_time,
data_time=data_time, loss=losses, top1=top1,
lr=optimizer.param_groups[0]['lr']))
end = time.time()
viz.line(Y=[losses.avg], X=[epoch], update='append', win=train_loss_win)
viz.line(Y=[top1.avg.item()], X=[epoch], update='append', win=train_acc_win)
# writer.add_scalar('Train/Acc', top1.avg, epoch) # tensorboard
# writer.add_scalar('Train/Loss', losses.avg, epoch)
def validate(val_loader, criterion, model, viz, test_loss_win, test_acc_win, args, epoch, best_acc):
batch_time = AverageMeter()
losses = AverageMeter()
top1 = AverageMeter()
# switch to evaluate mode
model.eval()
with torch.no_grad():
end = time.time()
for i, (data, target) in enumerate(val_loader):
if args.gpu is not None: # TODO None?
data = data.cuda(args.gpu, non_blocking=True)
target = target.cuda(args.gpu, non_blocking=True)
# compute output
output = model(data)
loss = criterion(output, target)
# measure accuracy and record loss
acc1, _ = accuracy(output, target, topk=(1, 5))
losses.update(loss.item(), data.size(0))
top1.update(acc1[0], data.size(0))
# measure elapsed time
batch_time.update(time.time() - end)
if i % args.print_freq == 0:
print('Test: [{0}/{1}]\t'
'Time {batch_time.val:.3f} ({batch_time.avg:.3f})\t'
'Loss {loss.val:.4f} ({loss.avg:.4f})\t'
'Acc@1 {top1.val:.3f} ({top1.avg:.3f})\t'
.format(
i, len(val_loader), batch_time=batch_time, loss=losses,
top1=top1))
end = time.time()
print(' * Acc@1 {top1.avg:.3f} '.format(top1=top1))
viz.line(Y=[losses.avg], X=[epoch], update='append', win=test_loss_win)
viz.line(Y=[top1.avg.item()], X=[epoch], update='append', win=test_acc_win)
# writer.add_scalar('Test/Acc', top1.avg, epoch)
# writer.add_scalar('Test/Loss', losses.avg, epoch)
if top1.avg.item() > best_acc:
print('new best_acc is {top1.avg:.3f}'.format(top1=top1))
print('saving model {}'.format(args.save_model))
torch.save(model.state_dict(), args.save_model)
return top1.avg.item()
def pruning(conv_weights, prune_ratio):
print('Pruning...')
# calculate inter-filter orthogonality
inter_filter_ortho = {}
for name, W in conv_weights:
size = W.size()
W2d = W.view(size[0], -1) # 变成二维数据
W2d = F.normalize(W2d, p=2, dim=1) # 对输入的数据(tensor)进行指定维度的L2_norm运算。
W_WT = torch.mm(W2d, W2d.transpose(0, 1)) # 得到相关性矩阵
I = torch.eye(W_WT.size()[0], dtype=torch.float32).cuda()# 单位矩阵
P = torch.abs(W_WT - I)
P = P.sum(dim=1) / size[0] # 求行平均值,变成一维
inter_filter_ortho[name] = P.cpu().detach().numpy()
# the ranking is computed overall the filters in the network
ranks = np.concatenate([v.flatten() for v in inter_filter_ortho.values()])
threshold = np.percentile(ranks, 100*(1-prune_ratio)) # 将百分位数设置为阈值
prune = {}
mask = {}
drop_filters = {}
for name, W in conv_weights:
prune[name] = inter_filter_ortho[name] > threshold # e.g. [True, False, True, True, False] 找出相关性大的filters
# get indice of bad filters
mask[name] = np.where(prune[name])[0] # e.g. [0, 2, 3] # 找到要裁剪的filter的索引
drop_filters[name] = None
if mask[name].size > 0:
with torch.no_grad():
drop_filters[name] = W.data[mask[name]].view(mask[name].size, -1).cpu().numpy()
W.data[mask[name]] = 0 # 将对应的filter置为0
test_filter_sparsity(conv_weights)
return prune, mask, drop_filters
def reinitialize(mask, drop_filters, conv_weights, fc_weights, zero_init):
print('Reinitializing...')
with torch.no_grad():
prev_layer_name = None
prev_num_filters = None
for name, W in conv_weights + fc_weights:
if W.dim() == 4 and drop_filters[name] is not None: # conv weights
# find null space
size = W.size()
stdv = 1. / math.sqrt(size[1]*size[2]*size[3]) # https://github.com/pytorch/pytorch/blob/08891b0a4e08e2c642deac2042a02238a4d34c67/torch/nn/modules/conv.py#L40-L47
W2d = W.view(size[0], -1).cpu().numpy()
null_space = qr_null(np.vstack((drop_filters[name], W2d)))
null_space = torch.from_numpy(null_space).cuda()
if null_space.size == 0:
W.data[mask[name]].uniform_(-stdv, stdv)
else:
null_space = null_space.transpose(0, 1).view(-1, size[1], size[2], size[3])
null_count = 0
for mask_idx in mask[name]:
if null_count < null_space.size(0):
W.data[mask_idx] = null_space.data[null_count].clamp_(-stdv, stdv)
null_count += 1
else:
W.data[mask_idx].uniform_(-stdv, stdv)
# # mask channels of prev-layer-pruned-filters' outputs
# if prev_layer_name is not None:
# if W.dim() == 4: # conv
# if zero_init:
# W.data[:, mask[prev_layer_name]] = 0
# else:
# W.data[:, mask[prev_layer_name]].uniform_(-stdv, stdv)
# elif W.dim() == 2: # fc
# if zero_init:
# W.view(W.size(0), prev_num_filters, -1).data[:, mask[prev_layer_name]] = 0
# else:
# stdv = 1. / math.sqrt(W.size(1))
# W.view(W.size(0), prev_num_filters, -1).data[:, mask[prev_layer_name]].uniform_(-stdv, stdv)
# prev_layer_name, prev_num_filters = name, W.size(0)
test_filter_sparsity(conv_weights)
def main():
viz = visdom.Visdom(env='repr') # 定义好环境
if not torch.cuda.is_available():
raise Exception("Only support GPU training")
cudnn.benchmark = True # 加速卷积运算
args = parser.parse_args()
# Data
print('==> Preparing data..')
transform_train = transforms.Compose([ # 数据增广
transforms.RandomCrop(32, padding=4),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010)),
])
transform_test = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010)),
])
trainset = torchvision.datasets.CIFAR10(
root='./data', train=True, download=True, transform=transform_train)
trainloader = torch.utils.data.DataLoader(
trainset, batch_size=128, shuffle=True, num_workers=args.workers)
testset = torchvision.datasets.CIFAR10(
root='./data', train=False, download=True, transform=transform_test)
testloader = torch.utils.data.DataLoader(
testset, batch_size=100, shuffle=False, num_workers=args.workers)
# Model
print('==> Building model..')
model = Vanilla()
print(model)
if args.gpu is not None:
torch.cuda.set_device(args.gpu)
model.cuda()
else:
model.cuda()
model = torch.nn.DataParallel(model)
conv_weights = [] # 卷积层参数
fc_weights = [] # 全连接层参数
for name, W in model.named_parameters():
if W.dim() == 4: # 卷积层参数
conv_weights.append((name, W))
elif W.dim() == 2: # 全连接层参数
fc_weights.append((name, W))
criterion = nn.CrossEntropyLoss().cuda()
optimizer = torch.optim.SGD(model.parameters(), args.lr, momentum=0.9, weight_decay=0.001)
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=30, gamma=0.5)
train_loss_win = viz.line([0.0], [0.], win='train_loss', opts=dict(title='train loss',legend=['trian loss']))# 先定义好窗口
train_acc_win = viz.line([0.0], [0.], win='train_acc', opts=dict(title='train acc',legend=['trian acc']))# 先定义好窗口
test_loss_win = viz.line([0.0], [0.], win='test_loss', opts=dict(title='test loss',legend=['test loss']))# 先定义好窗口
test_acc_win = viz.line([0.0], [0.], win='test_acc', opts=dict(title='test acc',legend=['test acc']))# 先定义好窗口
# comment = "-{}-{}-{}".format("repr" if args.repr else "norepr", args.epochs, args.comment)
# writer = SummaryWriter(comment=comment)
mask = None
drop_filters = None
best_acc = 0 # best test accuracy
prune_map = []
for epoch in range(args.epochs):
if args.repr:
# check if the end of S1 stage
if any(epoch == s for s in range(args.S1, args.epochs, args.S1+args.S2)):
prune, mask, drop_filters = pruning(conv_weights, args.prune_ratio)
prune_map.append(np.concatenate(list(prune.values())))
# check if the end of S2 stage
if any(epoch == s for s in range(args.S1+args.S2, args.epochs, args.S1+args.S2)):
reinitialize(mask, drop_filters, conv_weights, fc_weights, args.zero_init)
# scheduler.step()
train(trainloader, criterion, optimizer, epoch, model, viz, train_loss_win, train_acc_win, mask, args, conv_weights)
acc = validate(testloader, criterion, model, viz, test_loss_win, test_acc_win, args, epoch, best_acc)
scheduler.step()
best_acc = max(best_acc, acc)
test_filter_sparsity(conv_weights)
# writer.close()
print('overall best_acc is {}'.format(best_acc))
# # Shows which filters turn off as training progresses
# if args.repr:
# prune_map = np.array(prune_map).transpose()
# print(prune_map)
# plt.matshow(prune_map.astype(np.int), cmap=ListedColormap(['k', 'w']))
# plt.xticks(np.arange(prune_map.shape[1]))
# plt.yticks(np.arange(prune_map.shape[0]))
# plt.title('Filters on/off map\nwhite: off (pruned)\nblack: on')
# plt.xlabel('Pruning stage')
# plt.ylabel('Filter index from shallower layer to deeper layer')
# plt.savefig('{}-{}.png'.format(
# datetime.datetime.fromtimestamp(time.time()).strftime('%Y-%m-%d-%H:%M:%S'),
# comment))
if __name__ == '__main__':
main()效果图:
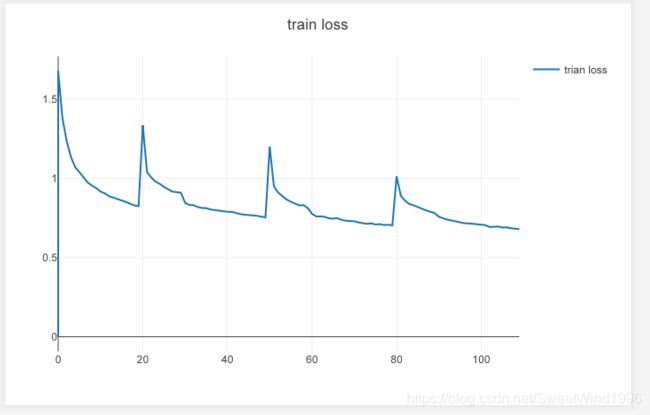

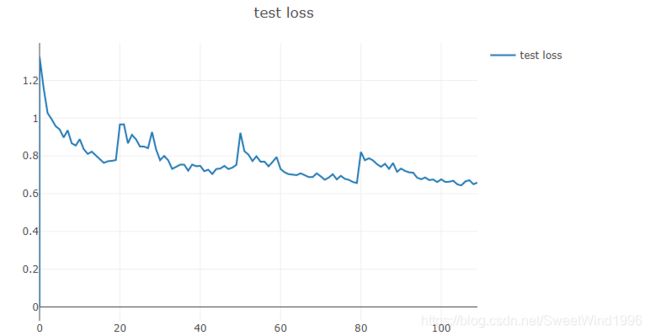
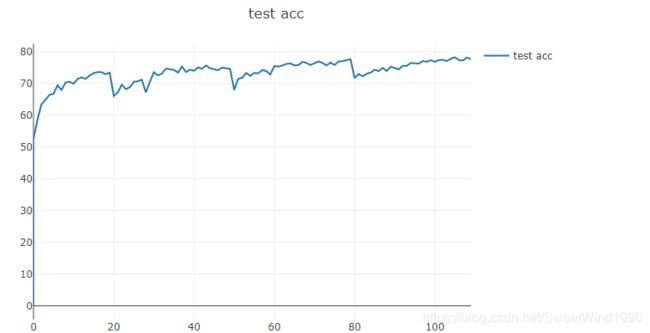
结论:与之前相比,在训练图中重新初始化时没有下降并且往上提升了,这是和论文一致的。但是测试集acc提升幅度没有论文中那么夸张,同时reinit后的acc提升也和很大。我猜测是作者没有裁剪第一层卷积,另外使用了别的技术。该论文至今代码未开源,作者的理由是未得到许可。
有问题欢迎大家讨论哦!~~
之前的内容:
思考:
1.首先一点是,在ranking的时候是进行全局的ranking,就是将所有的filters放在一起prune。但是O(公式2)是通过层内的计算而来的。生成W(公式1)是先将flatten之后的filter进行了归一化。详细内容可以看论文的第五部分。要注意的是:在讨论中,作者提到,在进行rank时不考虑第一个卷积层。
2.重新初始化 论文中的方法是用QR分解。我这里产生过一个问题,假如filters(全局)的个数远大于flat后的权重,或者每一层的权重尺寸不一样,后面的QR分解怎么操作。因为文章说了,在重新初始化时新的权重是与原来被prune的权重和当前新的权重同时正交的。
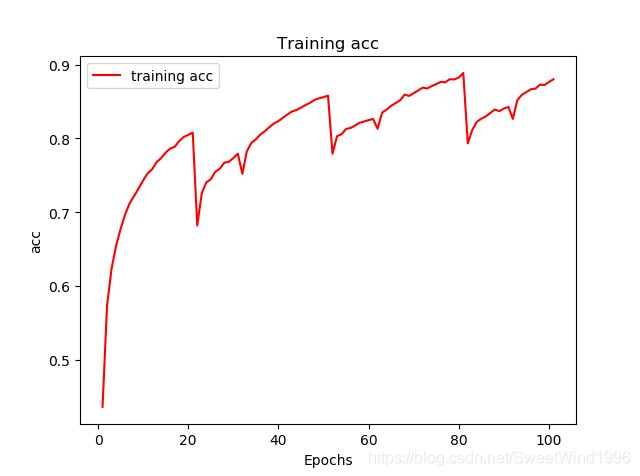
3.论文中的figure1 该训练图像很稳定,并且在reinitialize的时候没有出现下降的情况,在论文中的figure7中是出现了下降的。我在实验中也是出现下降的。
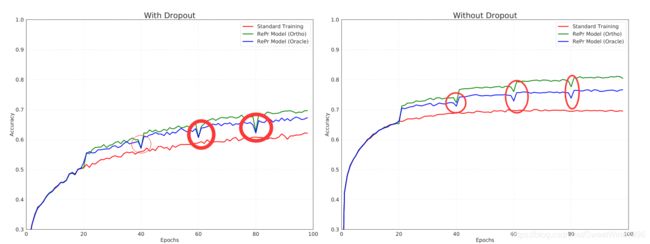
我的训练图像(出现reinit后的下降):
其实测试过程也不是很稳定(图中标错了,蓝色是训练acc,橙色是testacc):
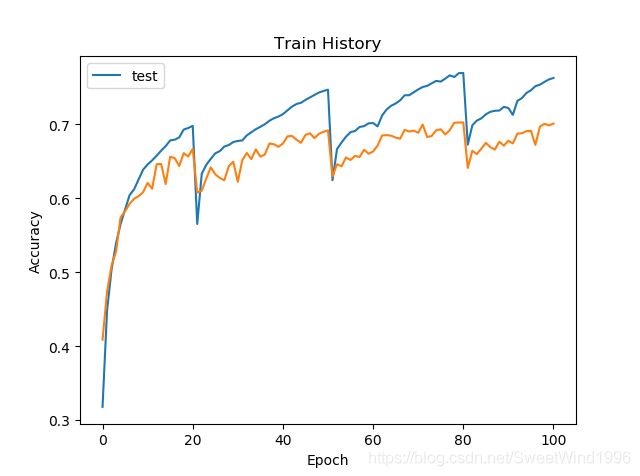
4.说一下结果:我重复训练了几次,结果不是很稳定,可能是我还没完全理解作者的思想或者代码写的存在问题,但这个工作也算是告一段落了。
总结: 1.可能使用的网络和作者不太一样,参数设置也存在出入,但是实验还是有一些效果的。我总共训练了大概20次,最好的一次就是测试集的正确率从67%(standard)上升到了70%(RePr)。 2.网络模型可能用的不太一样,但是如果正确的完成了总是有点效果的。
贴一些主要的代码:
def standard(shape=(32, 32, 3), num_classes=10):
modelinput = Input(shape)
conv1 = Conv2D(32, (3, 3))(modelinput)
bn1 = BatchNormalization()(conv1)
act1 = ReLU()(bn1)
pool1 = MaxPooling2D((2, 2))(act1)
conv2 = Conv2D(32, (3, 3))(pool1)
bn2 = BatchNormalization()(conv2)
act2 = ReLU()(bn2)
pool2 = MaxPooling2D((2, 2))(act2)
conv3 = Conv2D(32, (3, 3))(pool2)
bn3 = BatchNormalization()(conv3)
act3 = ReLU()(bn3)
pool3 = MaxPooling2D((2, 2))(act3)
flat = Flatten()(pool3)
dense1 = Dense(512)(flat)
act4 = ReLU()(flat)
drop = Dropout(0.5)(act4)
dense2 = Dense(num_classes)(drop)
act5 = Softmax()(dense2)
model = Model(modelinput, act5)
return model
def get_convlayername(model):
'''
获取卷积层的名称
# 参数
model: 神经网络模型
'''
layername = []
for i in range(len(model.layers)):
# 将模型中所有层的名称存入列表
layername.append(model.layers[i].name)
# 将卷积层分离出来
convlayername = [layername[name] for name in range(len(layername)) if 'conv2d' in layername[name]]
return convlayername[1:] # 不包括第一层
def prunefilters(model, convlayername, count=0):
'''
裁剪filters
# 参数
model: 神经网络模型
convlayername: 保存所有卷积层(2D)的名称
count: 用于存储每层filters的起始index
'''
convnum = len(convlayername) # 卷积层的个数
params = [i for i in range(convnum)]
weight = [i for i in range(convnum)]
MASK = [i for i in range(convnum)]
rank = dict() # 初始化存储rank的字典
drop = []
index1 = 0
index2 = 0
for j in range(convnum):
# 保存卷积层的权重到一个列表,列表的每个元素是一个数组
params[j] = model.get_layer(convlayername[j]).get_weights() # 将权重转置后才是正常的数组排列(32,32,3,3)
weight[j] = params[j][0].T
filternum = weight[j].shape[0] # 获取每一层filter的个数
# 初始化一个用于判断正交性的矩阵
W = np.zeros((weight[j].shape[0], weight[j].shape[2]*weight[j].shape[3]*weight[j].shape[1]), dtype='float32')
for x in range(filternum):
# filters是一个列表,它的每一个元素是包含一个卷积层所有filter(1D)的列表
filter = weight[j][x,:,:,:].flatten()
filter_length = np.linalg.norm(filter)
eps = np.finfo(filter_length.dtype).eps
filter_length = max([filter_length, eps])
filter_norm = filter / filter_length # 归一化
# 将每一层的filters放到矩阵的每一行
W[x,:] = filter_norm
# 计算层内正交性
I = np.identity(filternum)
P = abs(np.dot(W, W.T) - I)
O = P.sum(axis=1) / 32 # 计算每行元素之和
for index, o in enumerate(O):
rank.update({index+count: o})
count = filternum + count
# 对字典进行排序,在所有filters上进行ranking
ranking = sorted(rank.items(), key=lambda x: x[1]) # ranking为一个列表,其元素是存放键值的元组
for t in range(int(len(ranking)*0.8), len(ranking)):
drop.append(ranking[t][0])
for j in range(convnum):
MASK[j] = np.ones((weight[j].shape), dtype='float32')
index2 = weight[j].shape[0] + index1
for a in drop:
if a >= index1 and a < index2:
MASK[j][a-index1,:,:,:] = 0
index1 = index2
# weight[j] = (weight[j] * MASK[j]).T
# for j in range(convnum):
# params[j][0] = weight[j]
# model.get_layer(convlayername[j]).set_weights(params[j])
return MASK, weight, drop, convnum, convlayername
def Mask(model, mask):
convlayername = get_convlayername(model)
for i in range(len(convlayername)):
Params = [i for i in range(len(convlayername))]
Weight = [i for i in range(len(convlayername))]
Params[i] = model.get_layer(convlayername[i]).get_weights()
Weight[i] = (Params[i][0].T*mask[i]).T
Params[i][0] = Weight[i]
model.get_layer(convlayername[i]).set_weights(Params[i])
prune_callback = LambdaCallback(
on_batch_end=lambda batch,logs: Mask(model, mask))
def reinit(model, weight, drop, convnum, convlayername):
index1 = 0
index2 = 0
new_params = [i for i in range(convnum)]
new_weight = [i for i in range(convnum)]
for j in range(convnum):
new_params[j] = model.get_layer(convlayername[j]).get_weights()
new_weight[j] = new_params[j][0].T
stack_new_filters = new_weight[0]
stack_filters = weight[0]
filter_index1 = 0
filter_index2 = 0
for i in range(len(new_weight)-1):
next_new_filter = new_weight[i+1]
next_filter = weight[i+1]
stack_new_filters = np.vstack((stack_new_filters, next_new_filter))
stack_filters = np.vstack((stack_filters, next_filter))
stack_new_filters_flat = np.zeros((stack_new_filters.shape[0],
stack_new_filters.shape[1]*stack_new_filters.shape[2]*stack_new_filters.shape[3]), dtype='float32')
stack_filters_flat = np.zeros((stack_filters.shape[0],
stack_filters.shape[1]*stack_filters.shape[2]*stack_filters.shape[3]), dtype='float32')
for p in range(stack_new_filters.shape[0]):
stack_new_filters_flat[p] = stack_new_filters[p].flatten()
stack_filters_flat[p] = stack_filters[p].flatten()
q = np.zeros((stack_new_filters_flat.shape[0]), dtype='float32')
tol = None
reinit = None
solve = None
for b in drop:
Q, R= qr(stack_new_filters_flat.T)
for k in range(R.shape[0]):
if np.abs(np.diag(R)[k])==0:
# print(k)
reinit = Q.T[k]
break
null_space = reinit
stack_new_filters_flat[b] = null_space
for filter_in_stack in range(stack_new_filters_flat.shape[0]):
stack_new_filters[filter_in_stack] = stack_new_filters_flat[filter_in_stack].reshape(
(stack_new_filters.shape[1], stack_new_filters.shape[2], stack_new_filters.shape[3]))
for f in range(len(new_weight)):
filter_index2 = new_weight[f].shape[0] + filter_index1
new_weight[f] = stack_new_filters[filter_index1:filter_index2,:,:,:]
filter_index1 = new_weight[f].shape[0]
new_params[f][0] = new_weight[f].T
model.get_layer(convlayername[f]).set_weights(new_params[f])