深度学习14—循环神经网络RNN实战+MNIST案例+IMDB案例
RNN相关的网络层定义
循环层
keras.layers.SimpleRNN( # 全连接的 RNN,其输出直接被反馈到输入。
units : 正整数,输出空间的维度。
activation = 'tanh' : 要使用的激活函数。
use_bias = True : 该层是否使用偏置向量。
kernel_initializer = 'glorot_uniform' : kernel权值矩阵的初始化器。
用于输入的线性转换。
recurrent_initializer = 'orthogonal' : recurrent_kernel权值矩阵初始化器
用于循环层状态的线性转换。
bias_initializer = 'zeros' : 偏置向量的初始化器。
kernel_regularizer = None : kernel权值矩阵的正则化函数。
recurrent_regularizer = None : recurrent_kernel权值矩阵的正则化函数。
bias_regularizer = None : 偏置向量的正则化函数。
activity_regularizer = None : 层输出(它的激活值)的正则化函数。
kernel_constraint = None : kernel权值矩阵的约束函数。
recurrent_constraint = None : recurrent_kernel权值矩阵的约束函数。
bias_constraint = None : 偏置向量的约束函数。
dropout = 0.0 : 单元的丢弃比例,用于输入的线性转换。
recurrent_dropout = 0.0 : 单元的丢弃比例,用于循环层状态的线性转换。
return_sequences = False : 是返回输出序列中的最后一个输出,还是全部序列。
return_state = False : 除了输出之外是否返回最后一个状态(cell state)。
go_backwards = False : 如果为True,则向后处理输入序列并返回相反的序列。
stateful = False : 是否将批次中索引i的样品最后状态用作下一批次i样品的初始状态。
unroll = False : 如果为True,网络将展开,否则将使用符号循环。
展开可以加速RNN,但它往往会占用更多的内存。展开只适用于短序列。
)
keras.layers.RNN(
cell : 一个 RNN 单元实例。
return_sequences = False : 是返回输出序列中的最后一个输出,还是全部序列。
return_state = False : 除了输出之外是否返回最后一个状态(cell state)。
go_backwards = False : 是否向后处理输入序列并返回相反的序列。
stateful = False : 是否将批次中索引i的样品最后状态用作下一批次i样品的初始状态。
unroll = False : 如果为True,网络将展开,否则将使用符号循环。
展开可以加速RNN,但它往往会占用更多的内存。展开只适用于短序列。
input_dim : 输入的维度(整数)。 将此层用作模型中的第一层时,此参数必需。
input_length : 输入序列的长度,在恒定时指定。
如果在上游连接Flatten和Dense层,需要此参数(没有它无法计算全连接输出尺寸)。
)
其余RNN函数:
SimpleRNNCell : SimpleRNN的单元类。
嵌入层
用于将正整数的(字符串字典索引值)转换为固定尺寸的稠密向量,该层只能用作模型中的第一层。
例如: [[4], [20]] -> [[0.25, 0.1, 0.7], [0.6, -0.2, -1.3]]
keras.layers.Embedding(
input_dim : int > 0。词汇表大小, 即最大整数 index + 1。
output_dim : int >= 0。词向量的维度。
embeddings_initializer = 'uniform' : embeddings矩阵的初始化方法。
embeddings_regularizer = None : embeddings matrix的正则化方法。
activity_regularizer = None : 层输出(它的激活值)的正则化函数。
embeddings_constraint = None : embeddings matrix的约束函数。
mask_zero = False : 是否把0看作为一个应该被遮蔽的特殊的"padding"值。
input_length = None : 当输入序列长度固定时,给出输入序列的长度。
如果需要连接Flatten和Dense层,则这个参数是必须的。
)
用RNN拟合MNIST案例
数据准备
from keras.datasets import mnist
# 首次使用时会在线进行数据集下载
(X_train, y_train), (X_test, y_test) = mnist.load_data()
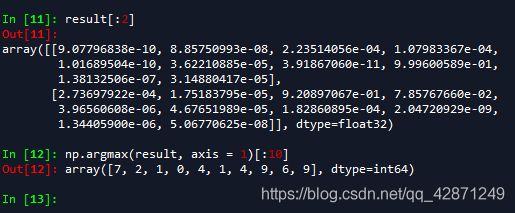
print('图像数据格式:', X_train.shape)
print("训练集:%2.0f,测试集:%2.0f" %(X_train.shape[0], X_test.shape[0]))
# 对数据做归一化处理以改善拟合效果
X_train = X_train / 255.
X_test = X_test / 255.
from keras.utils import to_categorical
# 将因变量转换为哑变量组
y_train = to_categorical(y_train)
y_test = to_categorical(y_test)
定义模型
from keras.layers import Input, Dense, SimpleRNN
from keras.models import Model
# 定义用于输入的张量
input = Input(shape = X_train[0].shape)
x = SimpleRNN(20, activation = 'relu')(input)
output = Dense(10, activation = 'softmax')(x) # 定义输出层
model = Model(inputs = input, outputs = output) # 定义模型
# RNN层连接权重数:(28 + 20 + 1) * 20
model.summary()
# RMSprop通常可用于RNN
model.compile(loss = 'categorical_crossentropy',
optimizer = 'rmsprop',
metrics = ['accuracy'])

模型训练
model.fit(X_train, y_train, batch_size = 200, epochs = 20)
模型评估与预测
import numpy as np
score = model.evaluate(X_test, y_test, batch_size = 200, verbose = 1)
print("测试集损失函数:%f,预测准确率:%2.2f%%" % (score[0], score[1] * 100))
# 模型预测
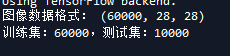
result = model.predict(X_test, batch_size = 200, verbose = 1)
result[:2]
np.argmax(result, axis = 1)[:10]
用RNN拟合IMDB案例
数据准备
IMDB数据集包括了来自IMDB的25,000条电影评论,以情绪(正面/负面)标记。评论已经过预处理,并编码为词索引(整数)的序列表示。
from keras.datasets import imdb
# 首次使用时会在线进行数据集下载
# 只保留数据集中最常出现的前10000个词
(X_train, y_train), (X_test, y_test) = imdb.load_data(num_words = 10000)
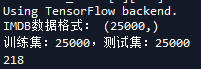
print('IMDB数据格式:', X_train.shape)
print("训练集:%2.0f,测试集:%2.0f" %(X_train.shape[0], X_test.shape[0]))
神经网络不能直接处理list类型的索引数据,需要考虑如何将list类型转换为tensor张量类型。
1、填充列表使每个列表长度都相同,然后转换为整数类型的张量,形状为(samples, word_indices),使用张量作为神经网络的第一层(Embedding层能处理这样的整数类型张量)。
2、将列表进行one-hot编码,转换成0、 1向量。然后用Dense网络层作为神经网络的第一层,处理浮点类型向量数据。
from keras.preprocessing.sequence import pad_sequences
# 将所有的序列均补齐或截断为统一长度
max_word = 300
X_train = pad_sequences(X_train, maxlen = max_word)
X_test = pad_sequences(X_test, maxlen = max_word)
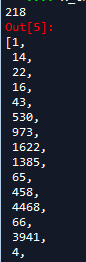
print(len(X_train[0]))
X_train[0][:100]
将X_train补全后,长度变为300
因变量
from keras.utils import to_categorical
# 将因变量转换为哑变量组
y_train = to_categorical(y_train)
y_test = to_categorical(y_test)
定义模型
from keras.layers import Input, Dense, SimpleRNN, Embedding
from keras.models import Model
from keras import layers
# 定义用于输入的张量
input = Input(shape = X_train[0].shape)
x = Embedding(input_dim = 10000, output_dim = 64)(input)
x = SimpleRNN(20, activation = 'relu')(x)
x = layers.Dense(16, activation='relu')(x)
output = Dense(2, activation = 'softmax')(x) # 定义输出层
model = Model(inputs = input, outputs = output) # 定义模型
model.summary()
# 注意设定适当的优化函数
model.compile(loss = 'categorical_crossentropy',
optimizer = 'rmsprop',
metrics = ['accuracy'])

模型训练
model.fit(X_train, y_train, batch_size = 128, epochs = 10)
模型评估与预测
score = model.evaluate(X_test, y_test, batch_size = 200, verbose = 1)
print("测试集损失函数:%f,预测准确率:%2.2f%%" % (score[0], score[1] * 100))
模型效果
![]()
预测:
result = model.predict(X_test, batch_size = 200, verbose = 1)
result[:2]
np.argmax(result, axis = 1)[:10]

增加全序列输出的循环层
#增加全序列输出的循环层
from keras.layers import Input, Dense, SimpleRNN, Embedding
from keras.models import Model
# 定义用于输入的张量
input = Input(shape = X_train[0].shape)
x = Embedding(input_dim = 10000, output_dim = 64,
input_length = 10000)(input)
x = SimpleRNN(20, return_sequences = True, activation = 'relu')(x)
x = SimpleRNN(20, return_sequences = False, activation = 'relu')(x)
x = layers.Dense(16, activation='relu')(x)
output = Dense(2, activation = 'softmax')(x) # 定义输出层
model = Model(inputs = input, outputs = output) # 定义模型